Measuring historical volatility
Say we are trying to estimate risk on a stock or a portfolio of stocks. For the purpose of this discussion, let’s say we’d like to know how far up or down we might expect to see a price move in one day.
First we need to decide how to measure the upness or downness of the prices as they vary from day to day. In other words we need to define a return. For most people this would naturally be defined as a percentage return, which is given by the formula:

where 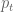


If you know your power series expansions, you will quickly realize there is not much difference between these two definitions for small returns- it’s only when we are talking about pretty serious market days that we will see a difference. One advantage of using the log returns is that they are additive- if you go down 0.01 one day, then up 0.01 the next, you end up with the same price as you started. This is not true for percentage returns (and is even more not true when you consider large movements like 50% down one day, 50% up the next).
Once we have our returns defined, we can keep a running estimate of how much we have seen it change recently, which is usually measured as a sample standard deviation, and is called a volatility estimate.
A critical decision in measuring the volatility is in choosing a lookback window, which is a length of time in the past we will take our information from. The longer the lookback window is, the more information we have to go by for our estimate. However, the shorter our lookback window, the more quickly our volatility estimate responds to new information. Sometimes you can think about it like this: if a pretty big market event occurs, how long does it take for the market to “forget about it”? That’s pretty vague but it can give one an intuition on the appropriate length of a lookback window. So, for example, more than a week, less than 4 months.
Next we need to decide how we are using the past few days worth of data. The simplest approach is to take a strictly rolling window, which means we weight each of the previous n days equally and a given day’s return is counted for those n days and then drops off the back of a window. The bad news about this easy approach is that a big return will be counted as big until that last moment, and it will completely disappear. This doesn’t jive with the sense of the ways people forget about things- they usually let information gradually fade from their memories.
For this reason we instead have a continuous look-back window, where we exponentially downweight the older data and we have a concept of the “half-life” of the data. This works out to saying that we scale the impact of the past returns depending on how far back in the past they are, and for each day they get multiplied by some number less than 1 (called the decay). For example, if we take the number to be 0.97, then for 5 days ago we are multiplying the impact of that return by the scalar 0.97^5. Then we will divide by the sum of the weights, and overall we are taking the weighted average of returns where the weights are just powers of something like 0.97. The “half-life” in this model can be inferred from the number 0.97 using these formulas as -ln(2)/ln(0.97) = 23.
Now that we have figured out how much we want to weight each previous day’s return, we calculate the variance as simply the weighted sum of the squares of the previous returns. Then we take the square root at the end to estimate the volatility.
Note I’ve just given you a formula that involves all of the previous returns. It’s potentially an infinite calculation, albeit with exponentially decaying weights. But there’s a cool trick: to actually compute this we only need to keep one running total of the sum so far, and combine it with the new squared return. So we can update our vol estimate with one thing in memory and one easy weighted average. This is easily seen as follows:
First, we are dividing by the sum of the weights, but the weights are powers of some number s, so it’s a geometric sum and the sum is given by

Next, assume we have the current variance estimate as

and we have a new return 
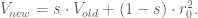
Note that I said we would use the sample standard deviation, but the formula for that normally involves removing the mean before taking the sum of squares. Here we ignore the mean, mostly because we are typically taking daily volatility, where the mean (which is hard to anticipate in any case!) is a much smaller factor than the noise. If we were to measure volatility on a longer time scale such as quarters or years, then we would not ignore the mean.
In my next post I will talk about how people use and abuse this concept of volatility, and in particular how it is this perspective that leads people to say things like, “a 6-standard deviation event took place three times in a row.”




Any market is a mixture of people trying to understand the fundamentals of what is being bought and sold, and people trying to understand the market and its participants. Small fish doing the latter are the suckers that make the big fish rich. Even more so when the small fish have predictable behaviour that the big fish are big enough to trigger.
LikeLike
Here I go again: I think you should take a look at this: http://en.support.wordpress.com/latex/ and this http://lucatrevisan.wordpress.com/latex-to-wordpress/
Ps: I loved your post anyway.
LikeLike
awesome thanks! I got pretty formulas!!
LikeLike