Holy crap – an actual book!
Yo, everyone! The final version of my book now exists, and I have exactly one copy! Here’s my editor, Amanda Cook, holding it yesterday when we met for beers:

Here’s my son holding it:

He’s offered to become a meme in support of book sales.
Here’s the back of the book, with blurbs from really exceptional people:

In other exciting book news, there’s a review by Richard Beales from Reuter’s BreakingViews, and it made a list of new releases in Scientific American as well.
Endnote:
I want to apologize in advance for all the book news I’m going to be blogging, tweeting, and otherwise blabbing about. To be clear, I’ve been told it’s my job for the next few months to be a PR person for my book, so I guess that’s what I’m up to. If you come here for ideas and are turned off by cheerleading, feel free to temporarily hate me, and even unsubscribe to whatever feed I’m in for you!
But please buy my book first, available for pre-order now. And feel free to leave an amazing review.
Who Counts as a Futurist? Whose Future Counts?
This is a guest post by Matilde Marcolli, a mathematician and theoretical physicist, who also works on information theory and computational linguistics. She studied theoretical physics in Italy and mathematics at the University of Chicago. She worked at the Massachusetts Institute of Technology and the Max Planck Institute for Mathematics, and is currently a professor at Caltech. This post in in response to Cathy’s last post.
History of Futurism
For a good part of the past century the term “futurism” conjured up the image of a revolutionary artistic and cultural movement that flourished in Russia and Italy in the first two decades of the century. In more recent times and across the Atlantic, it has acquired a different connotation, one related to speculative thought about the future of advanced technology. In this later form, it is often explicitly associated to the speculations of a group of Silicon Valley tycoons and their acolytes.
Their musings revolve around a number of themes: technological immortality in the form of digital uploading of human consciousness, space colonization, and the threat of an emergent superintelligent AI. It is easy to laugh off all these ideas as the typical preoccupations of a group of aging narcissist wealthy white males, whose greatest fear is that an artificial intelligence may one day treat them the way they have been treating everybody else all along.
However, in fact none of these themes of “futurist speculation” originates in Silicon Valley: all of them have been closely intertwined in history and date back to the original Russian Futurism, and the related Cosmist movement, where mystics like Fedorov alternated with scientists like Tsiolkovsky (the godfather of the Soviet space program) envisioning a future where science and technology would “storm the heavens and vanquish death”.
The crucial difference in these forms of futurism does not lie in the themes of speculation, but rather in the role of humanity in this envisioned future. Is this the future of a wealthy elite? Is this the future of a classless society?
Strains of Modern Futurism
Fast forward to our time again, there are still widely different versions of “futurism” and not all of them are a capitalist protectorate. Indeed, there is a whole widely developed Anarchist Futurism (usually referred to as Anarcho-Transhumanism) which is anti-capitalist but very pro-science and technology. It has its roots in many historical predecessors: the Russian Futurism and Cosmism, naturally, but also the revolutionary brand of the Cybernetic movement (Stafford Beer, etc.), cultural and artistic movements like Afrofuturism and Solarpunk, Cyberfeminism (starting with Donna Haraway’s Cyborg), and more recently Xenofeminism.
What some of the main themes of futurism look like in the anarchist lamelight is quite different from their capitalist shadow.
Fighting Prejudice with Technology
“Morphological Freedom” is one of the main themes of anarchist transhumanism: it means the freedom to modify one’s own body with science and technology, but whereas in the capitalist version of transhumanism this gets immediately associated to Hollywood-style enhanced botox therapies for those incapable of coming to terms with their natural aging process, in the anarchist version the primary model of morphological freedom is the transgender rights, the freedom to modify one’s own sexual and gender identity.
It also involves a fight against ableism, in as there is nothing especially ideal about the (young, muscular, male, white, healthy) human body.
The Vitruvian Man, which was the very symbol of Humanism, was also a symbol of the intrinsically exclusionary nature of Humanism. Posthumanism and Transhumanism are also primarily an inclusionary process that explodes the exclusionary walls of Humanism, without negating its important values (for example Humanism replaced religious thinking by a basis for ethical values grounded in human rights).
An example of Morphological Freedom against ableism is the rethinking of the notion of prosthetics. The traditional approach aimed at constructing artificial limbs that as much as possible resemble the human limbs, implicitly declaring the user of prosthetics in some way “defective”.
However, professional designers have long realized that prosthetic arms that do not imitate a human arm, but that work like an octopus tentacle can be more efficient than most traditional prosthetics. And when children are given the possibility to design and 3D print their own prosthetics, they make colorful arms that launch darts and flying saucers and that make them look like superheroes. Anarchist transhumanism defends the value and importance of neurodiversity.
Protesting with Technology
The mathematical theory of networks and of complex systems and emergent behavior can be used to make protests and social movements more efficient and successful. Sousveillance and anti-surveillance techniques can help protecting people from police brutality. Hacker and biohacker spaces help spreading scientific literacy and directly involve people in advanced science and technology: the growing community of DIY synthetic biology with biohacker spaces like CounterCulture Labs, has been one of the most successful grassroot initiatives involving advanced science. These are all important aspects and components of the anarchist transhumanist movement.
Needless to say, the community of people involved in Anarcho-Tranhumanism is a lot more diverse than the typical community of Silicon Valley futurists. Anarchism itself comes in many different forms, anarcho-communism, anarcho-syndacalism, mutualism, etc. (no, not anarcho-capitalism, that is an oxymoron not a political movement!) but at heart it is an ethical philosophy aimed at increasing people’s agency (and more generally the agency of any sentient being), based on empathy, cooperation, mutual aid.
Conclusion
Science and technology have enormous potential, if used inclusively and for the benefit of all and not with goals of profit and exploitation.
For people interested in finding out more about Anarcho-Tranhumanism there is an Anarcho-Transhumanist Manifesto currently being written (which is still very much in the making): the parts that are written at this point can be accessed here.
There is also a dedicated Facebook page, which posts on a range of topics including anarchist theory, philosophy, transhumanism and posthumanism and their historical roots, and various thoughts on science and technology and their transformative role.
The opinions expressed by the author are solely her own: her past and current affiliations are listed for identification purposes only.
The Absurd Moral Authority of Futurism
Yesterday one of my long-standing fears was confirmed: futurists are considered moral authorities.
The Intercept published an article entitled Microsoft Pitches Technology That Can Read Facial Expressions at Political Rallies, and written by Alex Emmons, which described a new Microsoft product that is meant to be used at large events like the Superbowl, or a Trump rally, to discern “anger, contempt, fear, disgust, happiness, neutral, sadness or surprise” in the crowd.
Spokesperson Kathryn Stack, when asked whether the tool could be used to identify dissidents or protesters, responded as follows:
“I think that would be a question for a futurist, not a technologist.”
Can we parse that a bit?
First and foremost, it is meant to convey that the technologists themselves are not responsible for the use of their technologies, even if they’ve intentionally designed it for sale to political campaigns.
So yeah, I created this efficient plug-and-play tool of social control, but that doesn’t mean I expect people to use it!
Second, beyond the deflecting of responsibility, the goal of that answer is to point to the person who really is in charge, which is for some reason “a futurist.” What?
Now, my experience with futurists is rather limited – although last year I declared myself to be one – but even so, I’d like to point out that futurism is male dominated, almost entirely white, and almost entirely consists of Silicon Valley nerds. They spend their time arguing about the exact timing and nature of the singularity, whether we’ll live forever in bliss or we’ll live forever under the control of rampant and hostile AI.
In particular, there’s no reason to imagine that they are well-versed in the history or in the rights of protesters or of political struggle.
In Star Wars terms, the futurists are the Empire, and Black Lives Matter are the scrappy Rebel Alliance. It’s pretty clear, to me at least, that we wouldn’t go to Emperor Palpatine for advice on ethics.
Expand Social Security, get rid of 401Ks
People, can we face some hard truths about how Americans save for retirement?
It Isn’t Happening
Here’s a fact: most people aren’t seriously saving for retirement. Ever since we chucked widespread employer based pension systems for 401K’s and personal responsibility, people just haven’t done very well saving. They take money out for college for their kids, or an unforeseen medical expense, or they just never put money in in the first place. Very few people are saving adequately.
In Fact, It Shouldn’t Happen
Next: it’s actually, mathematically speaking, extremely dumb to have 401K’s instead of a larger pool of retirement money like pensions or Social Security.
Why do I say that? Simple. Imagine everyone was doing a great job saving for retirement. This would mean that everyone “had enough” for the best-case scenario, which is to say living to 105 and dying an expensive, long-winded death. That’s a shit ton of money they’d need to be saving.
But most people, statistically speaking, won’t live until 105, and their end-of-life care costs might not always be extremely high. So for everyone to prepare for the worst is total overkill. Extremely inefficient to the point of hoarding, in fact.
Pooled Retirement Systems Are Key
Instead, we should think about how much more efficient it is to pool retirement savings. Then lots of people die young and are relatively “cheap” for the pool, and some people live really long but since it’s all pooled, things even out. It’s a better and more efficient system.
Most pension plans work like this, but they’ve fallen out of favor politically. And although some people complain that it’s hard to reasonably fund pension funds, most of that is actually poorly understood. Even so, I don’t see employer-based pension plans making a comeback.
Social Security is actually the best system we have, and given how few people have planned and saved for retirement, we should invest heavily in it, since it’s not sufficient to keep elderly people above the poverty line. And, contrary to popular opinion, Social Security isn’t going broke, could easily be made whole and then some, and is the right thing to do – both morally and mathematically – for our nation.
Stuff’s going on! Some of it’s progress!
Stuff’s going on, peoples, and some of it’s actually really great. I am so happy to tell you about it now that I’m back from vacation.
- The Tampon Tax is gone from New York State. This is actually old news but I somehow forgot to blog it. As my friend Josh says, we have to remember to celebrate our victories!!
- Next stop, Menstrual Equality! Jennifer Weiss-Wolf is a force of nature and she won’t stop until everyone has a free tampon in their… near vicinity.
- There’s a new “bail” algorithm in San Francisco, built by the Arnold Foundation. The good news is, they aren’t using educational background and other race and class proxies in the algorithm. The bad news is, they’re marketing it just like all the other problematic WMD algorithms out there. According to Arnold Foundation vice president of criminal justice Matt Alsdorf, “The idea is to provide judges with objective, data-driven, consistent information that can inform the decisions they make.” I believe the consistent part, but I’d like to see some data about the claim of objectivity. At the very least, Arnold Foundation, can you promise a transparent auditing process of your bail algorithms?
- In very very related news, Julia Angwin calls for algorithmic accountability.
- There’s a new method to de-bias sexist word corpora using vector algebra and Mechanical Turks. Cool! I might try to understand the math here and tell you more about it at a later date.
- Speaking of Mechanical Turk, are we paying them enough? The answer is no. Let’s require a reasonable hourly minimum wage for academic work. NSF?
Reform the CFAA
The Computer Fraud and Abuse Act is badly in need of reform. It currently criminalizes violations of terms of services for websites, even when those terms of service are written in a narrow way and the violation is being done for the public good.
Specifically, the CFAA keeps researchers from understanding how algorithms work. As an example, Julia Angwin’s recent work on recidivism modeling, which I blogged about here, was likely a violation of the CFAA:

A more general case has been made for CFAA reform in this 2014 paper, Auditing Algorithms: Research Methods for Detecting Discrimination on Internet Platforms, written by Christian Sandvig, Kevin Hamilton, Karrie Karahalios, and Cedric Langbort.
They make the case that discrimination audits – wherein you send a bunch of black people and then white people to, say, try to rent an apartment from Donald Trump’s real estate company in 1972 – have clearly violated standard ethical guidelines (by wasting people’s time and not letting them in on the fact that they’re involved in a study), but since they represent a clear public good, such guidelines should have have been set aside.
Similarly, we are technically treating employers unethically when we have fake (but similar) resumes from whites and blacks sent to them to see who gets an interview, but the point we’ve set out to prove is important enough to warrant such behavior.
Their argument for CFAA reform is a direct expansion of the aforementioned examples:
Indeed, the movement of unjust face-to-face discrimination into computer algorithms appears to have the net effect of protecting the wicked. As we have pointed out, algorithmic discrimination may be much more opaque and hard to detect than earlier forms of discrimination, while at the same time one important mode of monitoring—the audit study—has been circumscribed. Employing the “traditional” design of an audit study but doing so via computer would now waste far fewer resources in order to find discrimination. In fact, it is difficult to imagine that a major internet platform would even register a large amount of auditing by researchers. Although the impact of this auditing might now be undetectable, the CFAA treats computer processor time as and a provider’s “authorization” as far more precious than the minutes researchers have stolen from honest landlords and employers over the last few decades. This appears to be fundamentally misguided.
As a consequence, we advocate for a reconceptualization of accountability on Internet platforms. Rather than regulating for transparency or misbehavior, we find this situation argues for “regulation toward auditability.” In our terms, this means both minor, practical suggestions as well as larger shifts in thinking. For example, it implies the reform of the CFAA to allow for auditing exceptions that are in the public interest. It implies revised scholarly association guidelines that subject corporate rules like the terms of service to the same cost-benefit analysis that the Belmont Report requires for the conduct of ethical research—this would acknowledge that there may be many instances where ethical researchers should disobey a platform provider’s stated wishes.
Horrifying New Credit Scoring in China
When it comes to alternative credit scoring systems, look for the phrase “we give consumers more access to credit!”
That’s code for a longer phrase: “we’re doing anything at all we want, with personal information, possibly discriminatory and destructive, but there are a few people who will benefit from this new system versus the old, so we’re ignoring costs and only counting the benefits for those people, in an attempt to distract any critics.”
Unfortunately, the propaganda works a lot of the time, especially because tech reporters aren’t sufficiently skeptical (and haven’t read my upcoming book).
—
The alt credit scoring field has recently been joined by another player, and it’s the stuff of my nightmares. Specifically, ZestFinance is joining forces with Baidu in China to assign credit scores to Chinese citizens based on the history of their browsing results, as reported in the LA Times.
The players:
- ZestFinance is the American company, led by ex-Googler Douglas Merrill who likes to say “all data is credit data” and claims he cannot figure out why people who spell, capitalize, and punctuate correctly are somehow better credit risks. Between you and me, I think he’s lying. I think he just doesn’t like to say he happily discriminates against poor people who have gone to bad schools.
- Baidu is the Google of China. So they have a shit ton of browsing history on people. Things like, “symptoms for Hepatitis” or “how do I get a job.” In other words, the company collects information on a person’s most vulnerable hopes and fears.
Now put these two together, which they already did thankyouverymuch, and you’ve got a toxic cocktail of personal information, on the one hand, and absolutely no hesitation in using information against people, on the other.
In the U.S. we have some pretty good anti-discrimination laws governing credit scores – albeit incomplete, especially in the age of big data. In China, as far as I know, there are no such rules. Anything goes.
So, for example, someone who recently googled for how to treat an illness might not get that loan, even if they were simply trying to help their friend or family member. Moreover, they will never know why they didn’t get the loan, nor will they be able to appeal the decision. Just as an example.
Am I being too suspicious? Maybe: at the end of the article announcing this new collaboration, after all, Douglas Merrill from ZestFinance is quoted touting the benefits:
“Today, three out of four Chinese citizens can’t get fair and transparent credit,” he said. “For a small amount of very carefully handled loss of privacy, to get more easily available credit, I think that’s going to be an easy choice.”
Auditing Algorithms
Big news!
I’ve started a company called ORCAA, which stands for O’Neil Risk Consulting and Algorithmic Auditing and is pronounced “orcaaaaaa”. ORCAA will audit algorithms and conduct risk assessments for algorithms, first as a consulting entity and eventually, if all goes well, as a more formal auditing firm, with open methodologies and toolkits.
So far all I’ve got is a webpage and a legal filing (as an S-Corp), but no clients.
No worries! I’m busy learning everything I can about the field, small though it is. Today, for example, my friend Suresh Naidu suggested I read this fascinating study, referred to by those in the know as “Oaxaca’s decomposition,” which separates differences of health outcomes for two groups – referred to as “the poor” and the “nonpoor” in the paper – into two parts: first, the effect of “worse attributes” for the poor, and second, the effect of “worse coefficients.” There’s also a worked-out example of children’s health in Viet Nam which is interesting.
The specific formulas they use depends crucially on the fact that the underlying model is a linear regression, but the idea doesn’t: in practice, we care about both issues. For example, with credit scores, it’s obvious we’d care about the coefficients – the coefficients are the ingredients in the recipe that takes the input and gives the output, so if they fundamentally discriminate against blacks, for example, that would be bad (but it has to be carefully defined!). At the same time, though, we also care about which inputs we choose in the first place, which is why there are laws about not being able to use race or gender in credit scoring.
And, importantly, this analysis won’t necessarily tell us what to do about the differences we pick up. Indeed many of the tests I’ve been learning about and studying have that same limitation: we can detect problems but we don’t learn how to address them.
If you have any suggestions for me on methods for either auditing algorithms or for how to modify problematic algorithms, I’d be very grateful if you’d share them with me.
Also, if there are any artists out there, I’m on the market for a logo.
Race and Police Shootings: Why Data Sampling Matters
This is a guest post by Brian D’Alessandro, who daylights as the Head of Data Science at Zocdoc and as an Adjunct Professor with NYU’s Center for Data Science. When not thinking probabilistically, he’s drumming with the indie surf rock quarter Coastgaard.
I’d like to address the recent study by Roland Fryer Jr from Harvard University, and associated NY Times coverage, that claims to show zero racial bias in police shootings. While this paper certainly makes an honest attempt to study this very important and timely problem, it ultimately suffers from issues of data sampling and subjective data preparation. Given the media attention it is receiving, and the potential policy and public perceptual implications of this attention, we as a community of data people need to comb through this work and make sure the headlines are consistent with the underlying statistics.
First thing’s first: is there really zero bias in police shootings? The evidence for this claim is, notably, derived from data drawn from a single precinct. This is a statistical red flag and might well represent selection bias. Put simply, a police department with a culture that successfully avoids systematic racial discrimination may be more willing than others to share their data than one that doesn’t. That’s not proof of cherry-picking, but as a rule we should demand that any journalist or author citing this work should preface any statistic with “In Houston, using self-reported data,…”.
For that matter, if the underlying analytic techniques hold up under scrutiny, we should ask other cities to run the same tests on their data and see what the results are more widely. If we’re right, and Houston is rather special, we should investigate what they’re doing right.
On to the next question: do those analytic techniques hold up? The short answer is: probably not.
How The Sampling Was Done
As discussed here by economist Rajiv Sethi and here by Justin Feldman, the means by which the data instances were sampled to measure racial bias in Houston police shootings is in itself potentially very biased.
Essentially, Fryer and his team sampled “all shootings” as their set of positively labeled instances, and then randomly sampled “arrests in which use of force may have been justified” (attempted murder of an officer, resisting/impeding arrest, etc.) as the negative instances. The analysis the measured racial biases using the union of these two sets.
Here is a simple Venn diagram representing the sampling scheme:
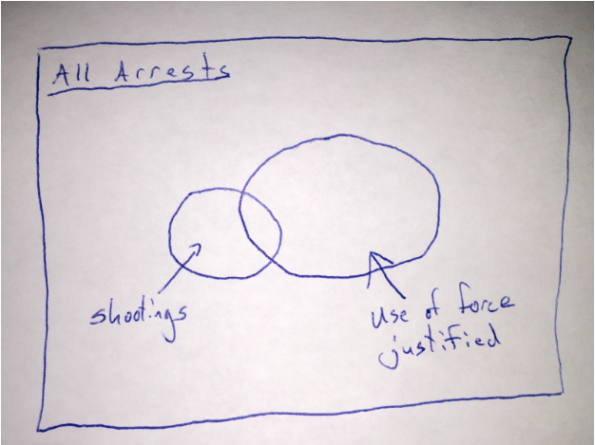
In other words, the positive population (those with shooting) is not drawn from the same distribution as the negative population (those arrests where use of force is justified). The article implies that there is no racial bias conditional on there being an arrest where use of force was justified. However, the fact that they used shootings that were outside of this set of arrests means that this is not what they actually tested.
Instead, they only show that there was no racial bias in the set that was sampled. That’s different. And, it turns out, a biased sampling mechanism can in fact undo the bias that exists in the original data population (see below for a light mathematical explanation). This is why we take great pains in social science research to carefully design our sampling schemes. In this case, if the sampling is correlated with race (which it very likely is), all bets are off on analyzing the real racial biases in police shootings.
What Is Actually Happening
Let’s accept for now the two main claims of the paper: 1) black and hispanic people are more likely to endure some force from police, but 2) this bias doesn’t exist in an escalated situation.
Well, how could one make any claim without chaining these two events together? The idea of an escalation, or an arrest reason where force is justified, is unfortunately an often subjective concept reported after the fact. Could it be possible that a an officer is more likely to find his/her life in danger when a black, as opposed to a white, suspect reaches for his wallet? Further, while unquestioned compliance is certainly the best life-preserving policy when dealing with an officer, I can imagine that an individual being roughed up by a cop is liable to push back with an adrenalized, self-preserving an instinctual use of force. I’ll say that this is likely for black and white persons, but if the black person is more likely to be in that situation in the first place, the black person is more likely to get shot from a pre-stop position.
To sum up, the issue at hand is not whether cops are more likely to shoot at black suspects who are pointing guns straight back at the cop (which is effectively what is being reported about the study). The more important questions, which is not addressed, is why are black men more likely to pushed up against the wall by a cop in the first place, or does race matter when a cop decides his/her life is in danger and believes lethal force is necessary?
What Should Have Happened
While I empathize with the data prep challenges Fryer and team faced (the Times article mentions that put a collective 3000 person hours here), the language of the article and its ensuing coverage unfortunately does not fit the data distribution induced by the method of sampling.
I don’t want to suggest in any way that the data may have been manipulated to engineer a certain result, or that the analysis team mistakenly committed some fundamental sampling error. The paper does indeed caveat the challenge here, but given that admission, I wonder why the authors were so quick to release an un-peer-reviewed working version and push it out via the NY Times.
Peer review would likely have pointed out these issues and at least push the authors to temper their conclusions. For instance, the paper uses multiple sources to show that non-lethal violence is much more likely if you are black or hispanic, controlling for other factors. I see the causal chain being unreasonably bisected here, and this is a pretty significant conceptual error.
Overall, Fryer is fairly honest in the paper about the given data limitations. I’d love for him to take his responsibility to the next level and make his data, both in raw and encoded forms, public. Given the dependency on both subjective, manual encodings of police reports and a single, biased choice of sampling method, more sensitivity analysis should be done here. Also, anyone reporting on this (Fryer himself), should make a better effort to connect the causal chain here.
Headlines are sticky, and first impressions are hard to undo.This study needs more scrutiny at all levels, with special attention to the data preparation that has been done. We need a better impression than the one already made.
The Math
The coverage of the results comes down to the following:
P(Shooting | Black, Escalation) = P(Shooting | White, Escalation)
(here I am using ‘Escalation’ as the set of arrests where use of force is considered justified. And for notational simplicity I have omitted the control variables from the conditional above).
However, the analysis actually shows that:
P(Shooting | Black, Sampled) = P(Shooting | White, Sampled),
Where (Sampled = True) if the person was either shot or the situation escalated and the person was not shot. This makes a huge difference, because with the right bias in the sampling, we could have a situation in which there is in fact bias in police shooting but not in the sampled data. We can show this with a little application of Bayes rule:
P(Shot|B, Samp) / P(Shot|W, Samp) = [P(Shot|B) / P(Shot|W)] * [P(Samp|W) / P(Samp|B)]
The above should be read as: the bias in the study depends on both the racial bias in the population (P(S|B) / P(S|W)) and the bias in the sampling. Any bias in the population can therefore effectively be undone by a sampling scheme that is also racially biased. Unfortunately, the data summarized in the study doesn’t allow us to back into the 4 terms on the right hand side of the above equality.
Review: The Wellness Syndrome
I just finished a neat little book called The Wellness Syndrome by Carl Cederström and André Spicer. They are (business school) professors in Stockholm and London, respectively, so the book has a welcome non-U.S. perspective.

The book defines the wellness syndrome to be an extension and a perversion of the concept of individual well-being. According to Cederström and Spicer, it’s not just that you are expected to care for yourself, it’s that you are blamed if you don’t, and conversely, if there’s anything at all wrong with your life, then it’s because you’ve failed to sufficiently take care of yourself. The result is that people have become utterly unaware of why things happen to them and how much power they actually have to change anything.
The wellness syndrome manifests itself in various ways:
- We are asked to “think positively” to make positive things happen to us. The funniest (read: saddest) section of the book relates to the fact that David Cameron was a big believer in this kind of positive thinking; he focused on good outcomes and ignored the bad ones, believing that somehow his personal willpower would make good things happen.
- We are asked to take care of ourselves in order to stay competitive in the workforce, to productize and commoditize ourselves. This could mean staying slim – because if you’re overweight you’re falling down on the self-optimization regiment – or it could mean engaging in the quantified self movement, keeping track of sleep, exercise, and even pooping schedules, and at the very least it requires us to monitor our attitudes.
- We are asked to enjoy ourselves while we take full personal responsibility for our own wellness, which in the age of the gig economy means we always appear happy to stay lively and infinitely employable under increasingly precarious economic conditions.
- If things don’t go well for us, if we cannot find that job or we cannot seem to lose the extra weight, we are expected to feel guilty and – this is crucial – not to blame the system for an inadequate supply of job, nor the racist, sexist, or otherwise discriminatory environment, but rather our own mindset. God forbid we ever accept any actual limit to our powers of reinvention, because that is equivalent to giving up.
- The authors point to Margaret Thatcher and Tony Blair in the UK and to Reagan and Bill Clinton in the US as creators of this notion of individual responsibility as a shield of governmental responsibility, and they frequently point out that the “positive mindset” self-help gurus thus represent a perfect pairing: a pairing, moreover, which manages to depoliticize itself as its power grows.
- The consequence: we don’t think of ourselves as political victims when we fall prey to a narcissistic worldview in which we are never fit enough, never eating enough organic kale, and never productive enough. Instead we engage in self-criticism, guilt, and renewed promises to try better next time. We internalize the shame and the definition of ourselves as “improperly optimized.”
- In the end, we all walk around with tiny little versions of Reagan’s welfare queens in our heads – or at the very least, the fear of becoming anything like her. In the UK it’s a slightly varied version called the Chav.
There are two rich topics that aren’t addressed in this book which I’d love to hear about, even if it’s just in an informal conversation with the authors. First, what about the online dating scene? How does that play into this and amplify it? From my perspective, online dating has a strong effect on how people create and wield data about themselves, and the extent to which they self-criticize, stemming from (I assume) the question of how they are being seen by potential lovers.
Second, to what extent does this concept of self-perfecting and quantifying encourage the subculture of futurism? Do people like Ray Kurzweil and others who believe they will live forever represent the most extreme version of the wellness syndrome, or do they suffer from some other disease?
I liked the book a lot. There are lots of topics in common with my upcoming book, in fact, including wellness programs and personal data collection, and other ways that employers have increasing control over our bodies and lives. And although we largely agree, it was interesting to read their more historical take on things. Also, it was a super fast read, at only 135 pages. I recommend it.
End Broken Windows Policing
Yesterday I learned about Campaign Zero, a grassroots plan to end police violence. The first step in their plan is to end Broken Windows policing. Here’s their argument:
A decades-long focus on policing minor crimes and activities – a practice called Broken Windows policing – has led to the criminalization and over-policing of communities of color and excessive force in otherwise harmless situations. In 2014, police killed at least 287people who were involved in minor offenses and harmless activities like sleeping in parks, possessing drugs, looking “suspicious” or having a mental health crisis. These activities are often symptoms of underlying issues of drug addiction, homelessness, and mental illness which should be treated by healthcare professionals and social workers rather than the police.
Having studied the effects of uneven policing myself, especially how it pertains to the data byproduct of “police events,” I could not agree more.
There was a recent New York Times article that got people’s attention. It claimed that there was no bias in police shootings of blacks over whites. What it didn’t talk about – crucially – was the chance that a given person would end up in an interaction with the police in the first place.
It’s much more likely for blacks, especially young black men, to end up in an interaction with cops. And that’s due in large part to the broken theory of Broken Windows policing.
New York City’s version of Broken Windows policing – Stop, Question, and Frisk – was particularly vile, and was eventually declared unconstitutional due to its disparate impact on minorities. The ACLU put some facts together when Stop and Frisk was at its height, including the following unbelievable statistics from 2011:
- The number of stops of young black men exceeded the entire city population of young black men (168,126 as compared to 158,406).
- In 70 out of 76 precincts, blacks and Latinos accounted for more than 50 percent of stops, and in 33 precincts they accounted for more than 90 percent of stops. In the 10 precincts with black and Latino populations of 14 percent or less (such as the 6th Precinct in Greenwich Village), black and Latino New Yorkers accounted for more than 70 percent of stops in six of those precincts.
What happens when this kind of uneven policing goes on? Lots of stupid arrests for petty crimes, for “resisting arrest,” and generally for being poor or having untreated mental health problems. About 1 in 1000 such stops are directly linked to a violent crime.
And again, since those stopped are overwhelmingly minority, it means that when City Hall decides to use predictive policing based on this data, they end up over policing the same neighborhoods, creating even more uneven and biased data. That continuing stream of data even ends up in sentencing and paroling algorithms, making it more likely for those same over-policed populations to stay in jail longer.
It’s high time we get rid of the root cause, the theory of Broken Windows, which was never proven in the first place, which optimizes on the wrong definition of success, and which further undermines community trust in the police.
When is AI appropriate?
I was invited last week to an event co-sponsored by the White House,Microsoft, and NYU called AI Now: The social and economic implications of artificial intelligence technologies in the near term. Many of the discussions were under “Chatham House Rule,” which means I get to talk about the ideas without attributing any given idea to any person.
Before I talk about some of the ideas that came up, I want to mention that the definition of “AI” was never discussed. After a while I took it to mean anything that was technological that had an embedded flow chart inside it. So, anything vaguely computerized that made decisions. Even a microwave that automatically detected whether your food was sufficiently hot – and kept heating if it wasn’t – would qualify as AI under these rules.
In particular, all of the algorithms I studied for my book certainly qualified. And some of them, like predictive policing and recidivism risk models, google search and resume filtering algorithms, were absolutely talked about and referred to as AI.
One of the questions we posed was, when is AI appropriate? Is there a class of questions that AI should not be used for, and why? More interestingly, is there AI working and making decisions right now, in some context, that should be outlawed? Or at least put on temporary suspension?
[Aside: I’m so glad we’re actually finally discussing this. Up until now it seems like wherever I go it’s taken as a given that algorithms would be an improvement over human decision-making. People still automatically assume algorithms are more fair and objective than humans, and sometimes they are, but they are by no means perfect.]
We didn’t actually have time to thoroughly discuss this question, but I’m going to throw down the gauntlet anyway.
—
Take recidivism risk models. Julia Angwin and her team at ProPublica recently demonstrated that the COMPAS model, which was being used in Broward County Florida (as well as many other places around the country), is racist. In particular, it has very different errors for blacks and for whites, with high “false positive” rates for blacks and high “false negative” rates for whites. This ends up meaning that blacks go to jail for longer, since that’s how recidivism rates are being used.
So, do we throw out recidivism modeling altogether? After all, judges by themselves are also racist; a models such as the COMPAS model might actually be improving the situation. Then again, it might be making it worse. We simply don’t know without a monitor in place. (So, let’s get some monitors in place, people! Let’s see some academic work in this area!)
I’ve heard people call for removing recidivism models altogether, but honestly I think that’s too simple. I think we should instead have a discussion on what they show, why they’re used the way they are, and how they can be improved to help people.
So, if we’re seeing way more black (men) with high recidivism risk scores, we need to ask ourselves: why are black men deemed so much more likely to return to jail? Is it because they’re generally poorer and don’t have the start-up funds necessary to start a new life? Or don’t have job opportunities when they get out of prison? Or because their families and friends don’t have a place for them to stay? Or because the cops are more likely to re-arrest them because they live in poor neighborhoods or are homeless? Or because the model’s design itself is flawed? In short, what are we measuring when we build recidivism scores?
Second, why are recidivism risk models used to further punish people who are already so disadvantaged? What is it about our punitive and vengeful justice system that makes us punish people in advance for crimes they have not yet committed? It keeps them away from society even longer and further casting them into a cycle of crime and poverty. If our goal were to permanently brand and isolate a criminal class, we couldn’t look for a better tool. We need to do better.
Next, how can we retool recidivism models to help people rather than harm them? We could use the scores to figure out who needs resources the most in order to stay out of trouble after release, to build evidence that we need to help people who leave jail rebuild their lives. How do investments in education inside help people once they get out land a job? Do states that make it hard for employers to discriminate based on prior convictions – or for that matter on race – see better results for recently released prisoners? To what extent does “broken windows policing” in a neighborhood affect the recidivism rates for its inhabitants? These are all questions we need to answer, but we cannot answer without data. So let’s collect the data.
—
Back to the question: when is AI appropriate? I’d argue that building AI is almost never inappropriate in itself, but interpreting results of AI decision-making is incredibly complicated and can be destructive or constructive, depending on how well it is carried out.
And, as was discussed at the meeting, most data scientists/ engineers have little or no training in thinking about this stuff beyond optimization techniques and when to use linear versus logistic regression. That’s a huge problem, because part of AI – a big part – is the assumption that AI can solve every problem in essentially the same way. AI teams are, generally speaking, homogenous in gender, class, and often race, and that monoculture gives rise to massive misunderstandings and narrow ways of thinking.
The short version of my answer is, AI can be made appropriate if it’s thoughtfully done, but most AI shops are not set up to be at all thoughtful about how it’s done. So maybe, at the end of the day, AI really is inappropriate, at least for now, and until we figure out how to involve more people and have a more principled discussion about what it is we’re really measuring with AI.
The arXiv should be supported by the NSF
What the fuck is wrong with the NSF? Why isn’t it supporting the arXiv?
I have been offended and enraged recently to receive pleading emails from members of the hard-working Cornell University Library arXiv Team for money. As in, please give us $5.
This is a ridiculous state of affairs.
Right now arXiv, which hosts preprints from the fields of mathematics, computer science, physics, quantitative biology, quantitative finance, and statistics, plays an absolutely pivotal role in basic research in this country, especially given the expense and time-consuming journal publishing process.
It has an operating budget of less that $1 million per year, and is somehow left begging for personal donations, supplemented by small grants from the Simons Foundation.
If you look at the mission of the National Science Foundation, it’s first part is “to promote the progress of science.” Moreover, it has an annual budget of $7.5 billion. I cannot think of a better way for it to fulfill its mission than to support the maintenance and expansion of the arXiv.
Am I wrong about this? WTF??
WMD Audiobook!
Today and yesterday I’m recording the audiobook version of my upcoming book, Weapons of Math Destruction, in a studio in the Random House building near Columbus Circle.
It’s hard work! I’m constantly having to retake sentences, either because I thought my tone was too flat (I hate flat audiobook readers!), or wasn’t emphasizing the right words, or because the words are just hard to say.
Speaking of which, I promise to never, ever write the phrase “assist statistics” in anything that might someday be read out loud, ever, anywhere. And also, you are hereby prohibited from reading this blogpost out loud.
I was pretty worried that the actual content would be bothersome to me – that I’d find tons of typos, or that things would have changed so much that the content is no longer relevant. So far, so good, though, at least to my eyes.
I’m happy with the book! Is that ok to say (not out loud!!)? I’m holding on to this delicious feeling until the nasty reviews come out. After that I’ll just cry inside at all times.
In the meantime, I’ve started a website for the book, including early reviews (i.e. blurbs, including from my buddy Jordan Ellenberg) and one actual review from Publisher’s Weekly, which I’m super happy with.
On Being Lane Bryant Fat
There was an amazing This American Life episode that aired earlier this month called Tell Me I’m Fat, centering around 4 stories about how people have dealt with being fat and the obesity epidemic more generally (hat tip Becky Jaffe).
And I plan to respond to all of them in turn, but let me mention right off the top that I didn’t think I had much to learn about this topic, but I learned a lot about this topic from listening to this episode, which was both empathetic and deep.
—
The first story could have been about me, almost. In short, it was about a woman who spent a bunch of wasted time in her youth worrying about being fat, then eventually she realized she was always going to be fat, that she was sick of apologizing for it and going on diets that didn’t work, and she came to terms with being fat. She owns it. Good for her.
What especially made me nod along was her talking about how she’d prefer the descriptor “fat” than the alternative, “overweight,” which is both a useless euphemism and a judgment, that it was somehow a temporary problem that would soon be fixed. Fuck that.
Oh, and also, she works with Dan Savage, and she called him on his fat shaming. I have always wanted someone to do that.
—
The second story was super sad, about a woman who was fat at some point but lost a bunch of weight by taking diet pills – basically speed – and found love and a good job by slimming down. She is now married to a man who admitted on tape that he wouldn’t love her if she were fat. She has a job which she claims she needs to be skinny to keep. She’s still taking (black market) diet pills. I am absolutely terrified for her.
—
The third story was what hit me. It was the story of a very fat woman of color, talking about just how hard it is to be that large. I really do get a lot of what she’s saying, but the more I think about it the more I realize I don’t get it, actually. I mean, I’ve been to restaurants where the chairs have arms and define a butt size that is simply smaller than mine. I have needed to ask for another chair. I have been extremely uncomfortable in an airplane seat.
But I’ve never been unable to fly, nor have I worried about chairs breaking beneath me. This woman does worry about this, and researches restaurants before she goes in case she cannot be accommodated. It’s a different level of humiliation and isolation. Where I feel annoyed that subway seats are too small, she is truly removed from the realm of normal.
She has a name for people like me: Lane Bryant Fat. I’m the woman who, increasingly, can find cute clothes to wear, who can talk about being fit and fat, and who can find company in a larger and larger adult population of women of size 22 or thereabouts.
She’s right, I don’t feel like a freak anymore. When I go to Brooklyn, I actually feel very normal. Even when I was in Paris I didn’t stick out very much, which was certainly very different 20 years ago.
And she’s also right that Lane Bryant Fat women don’t really get here or care about her. When I pass by people as large as she is, I do not regularly relate to them. On a normal day, some little voice inside me, some mean part of me, says, at least I haven’t let myself go that much.
Considering how hard I know I’ve tried in the past to change, you’d think I would be more enlightened about this issue, but until I heard this radio segment, I had never examined my own, internal version of fat shaming. Shame on me.
—
The last segment was about the Oral Roberts University effort in the 1970’s, I believe, to make its students lose weight as a graduation requirement. This resonated with me deeply, because it was a large scale version of what went on within my home as a child. For a time as a tweenager, I wasn’t given my allowance unless I’d lost enough weight each week. It was cruel, humiliating, and it imbued me with a shame that lasted longer than I’d care to admit.
—
This was a breakthrough, this radio program. I am so very glad this conversation has begun, and I’m so very glad it included these multiple voices, but it’s really just the beginning.
For example, here’s the thing I’m grappling with right now. I’m living in fear of becoming (type II) diabetic. I’m absolutely high risk for it: my age, my genetics, and my weight all point to it. The only thing I have going for myself is that I exercise regularly, which reduces the risk, but not entirely. So I’m on the lookout, and I’d like to think I’m prepared.
But part of that preparation includes being willing to have gastric bypass surgery, which has become much safer and is an almost miracle cure for type II diabetes. It is, in fact, the treatment of choice according to some international experts.
But at the same time, it’s a diet surgery, and if I underwent the procedure, I could expect to lose a lot of weight. For someone who has spent 20 years establishing a (Lane Bryant) fat identity, it’s actually really confusing to imagine opting for the knife. I’d feel like a turncoat.
Which isn’t to say I’d refuse it. I’ve already checked that my insurance covers the surgery. For BMI up to 40, it covers it if diabetes is present. But given that my BMI is actually above that, I could get the surgery now, without needing to “be sick.” I’m confused by this, and I don’t think I’m alone.
So what about it, This American Life? More episodes, please!
Why did the Brexit polls get it so wrong?
The Brexit vote was a huge deal, both politically and economically. Tons of polls have been telling us for weeks that’s it’d be a close contest, but since the murder of Jo Cox’s, they had mostly been pointing one way: namely, to a Remain win.
To be clear, lots of people said it was too close to call, but the bulk of yesterday’s evidence said that Remain would win by 52% to 48%, with a margin of error of around 2%. The actual results were the opposite, Remain lost by 48% to 52%.
Stock markets can also embed beliefs, and in this case they definitely seemed to think Britain would vote to remain in the EU. For that matter, there were plenty of betting markets that allowed people to bet directly on the vote, and as of yesterday the odds were steeply in favor of Remain. Even the early exit polls pointed to Remain.
So, why did all the polls get it so wrong? I have no more information that anyone else, but I have some purely unsubstantiated, backwards-looking guesses:
- Older people are much more likely to vote, and they also tended to vote Leave.
- People who voted to Leave cared more about the issue.
- People lie in polls, and given that the Leave campaign was being accused of racism, it’s maybe easier to lie towards Remain than the other way around. Also could be a reason that more “undecided” voters were secretly planning to vote Leave but didn’t want to say it out loud.
- People might have actually put money in the betting markets, including the financial markets, that have nothing to do with their belief of the outcome but rather represents a hedge for another position.
- As for the exit polls, they are easier to take in cities, where there are a lot of people, but where there also tend to be more “Remain” voters.
What do you think? Here’s some demographic info from the Guardian that may or may not help:

OIG Report: Broken Windows doesn’t work
The Office of the Inspector General for the New York Police Department (OIG-NYPD) issued a report yesterday which used statistical analysis to demonstrate that the “Broken Windows” theory of policing is flawed. From their Recommendations, page 72:
OIG-NYPD found no evidence that the drop in felony crime observed over the past six years was related to quality-of-life summonses or quality-of-life misdemeanor arrests. This suggests that there are other strategies that may be driving down crime. Between 2010 and 2015, quality-of-life enforcement rates – in particular, quality-of-life summons rates – have dramatically declined, but there has been no commensurate increase in felony crime. While the stagnant or declining felony crime rates observed in this six-year time frame may perhaps be attributable to NYPD’s other disorder reduction strategies, OIG-NYPD finds no evidence to suggest that crime control can be directly attributed to quality-of-life summonses and misdemeanor arrests. Whatever has contributed to the observed drop in felony crime remains an open question worthy of further analysis.
The report goes on to say that the NYPD should take a more data driven approach to deciding what’s actually working and what isn’t, and should “conduct an analysis to determine whether quality-of-life enforcement disproportionately impacts black and Hispanic residents, males aged 15-20, and NYCHA residents.”
Very happy about this report, it’s been a super long time coming. The NYPD has said the report is flawed, and will come back with a response within 90 days. I’m looking forward to that as well.
Gerrymandering algorithms
I’ve been thinking about gerrymandering recently, specifically how to design algorithms to gerrymander and to detect gerrymandering.
Whence “Gerrymander”?
First thing’s first. According to wikipedia (and my friend Michael Thaddeus), the term “Gerrymander” is a mash-up of a dude named Elbridge Gerry and the word “salamander.” It was concocted when Gerry got made fun of for his crazy districting of Massachusetts back in 1812 to push out the power of the Federalists:
It’s true, this is depicted as a dragon. But believe me, someone thought it looked like a salamander.
How To Gerrymander
Think about it. In this crazy pseudo-democratic world of ours, we’re still voting locally and asking delegates to ride their horses to a centralized location to cast a vote for the group. The system was invented well before the internet, and it is a ridiculous and unnecessary artifact from the days when information didn’t travel well. In particular, it means you can manipulate voting at the local level, by gaming the definition of the district boundaries.
So, let’s imagine you’re in charge of drawing up districts, and you want to rig it for your party. That means you’d like your party to win as often as possible and lose as seldom as possible per district. If you think about it for a while, you’ll come up with the following observation: you should win by a thin margin but lose huge.
Theoretically that would mean building districts – a lot of them – that are 51% in your favor, and then other districts that are 100% against you.
In reality, you can’t count on anything these days, so you might want to create slightly wider margins, of maybe 55% your party, and there might be rules about how connected districts must be, so you’ll never achieve 100% loss districts.
Although clearly not very hard and fast rules.
How Not To Gerrymander
On the other side of the same question, we might ask ourselves, is there a better way? And the answer is, absolutely yes. Besides just counting all votes equally, we could draw up districts to contain similar numbers of voters and to be more or less “compact.”
If you don’t know what that really means, you can go look at the work of a computer nerd named Brian Olsen, who built a program to do just this.

Before and after Brian Olsen gets his hands on Pennsylvania
Detecting Gerrymandering
The concept of compactness is pretty convincing, and has led some to define gerrymandering to be, in effect, a measurement of the compactness of districts. More formally, there’s a so-called “Gerrymander Score” that is defined as the ratio of the perimeter to the area of districts, with some fudge factor which allows for things like rivers and coastlines.
Another approach is a “Gerrymander statistical bias” test, namely the difference between the mean and the median. Here you take the results of an election by district, and you rank them from lowest to highest for your party. So there might be a district that only voted 4% for your party, and it might go on the left end, and on the other end the district that voted 95% for your party would be on the other end. Now look at the “middle” district, and see how much that district voted for your party. Say it’s 47%. Then, if your party won 55% of the vote overall in the state – the mean in this case is 55% – there’s a big difference between 55 and 47, and you can perhaps cry foul.
I mean, this seems like a pretty good test, since if you think back to what we would do to gerrymander, in the ideal world (for us) we’d get a bunch of districts with 45% for the other side and then a few with 99% for the other side, and the median would be 45% even if the other side had way more voters overall.
Problems With Gerrymandering Detection
There’s a problem, though, which was detected by, among other people, political scientists Jowei Chen and Jonathan Rodden. Namely, if you run scenarios on non-gerrymandered, compact districts, you don’t get very “fair” results as defined by the above statistical bias test.
This is because, in reality, Democrats are more clustered than Republicans. Democrats are quite concentrated in cities and college towns, and then they are more sparse elsewhere. They, in essence, gerrymander themselves.
Said another way, if you build naive districts that are compact (so their Gerrymander Scores are good) then there will be automatic “Gerrymander statistical bias” problems. Oy vey.
Which is not to say that there isn’t actual effective and nasty Gerrymandering going on. There is, in North Carolina, Florida, Pennsylvania, Texas and Michigan for the Republicans and in California, Maryland and Illinois for the Democrats.
But what it means overall is that there’s no reason to believe we’ll ever get out of this stupid districting system, because it gives an inherent advantage to Republicans. So why would they agree to tossing it?
Adding another layer of cynicism to the “smart” city revolution
There was an interesting essay by Jacob Silverman in the New York Times last week called Just How ‘Smart’ Do You Want Your Blender to Be? (hat tip Ernie Davis).
In it, Silverman makes a few really great points. First, that we are sold “smart” products like the Nest thermostat or the my.Flow tampon or cell phones, and all we really get is surveillance and a lack of control over our own stuff (because it’s called “hacking” if we try to fiddle with our phones). Plus he goes into the old English definition of smart – a verb meaning “causing sharp pain,” as in “that smarts!” – as another reason that we might not want a smart version of everything.
All true, but I think there’s a couple of important points missing in his narrative. Specifically, I don’t think he was being sufficiently cynical.
First of all, something very old-fashioned is going on. Namely, people are marketing things as “smart” because they want to claim they have new products so they can then claim they have a business.
In other words, I’m imagining 95% of the smart products were invented like this: hey, let’s figure out an old product we can add sensor technology to and then sell it like it’s a new product. Blenders? Tampons? Can we add sensors to tampons to figure out when the tampon is drenched in blood? WOULD PEOPLE PAY FOR THAT?
The answer is, generally, no fucking way, but there’s too much money in Silicon Valley for that answer to be heard. So these ridiculous companies keep making their ridiculous, unnecessary products.
The second and more cynical point is focused on the “smart city” fad. Silverman rightly points out that we now have free “smart” wifi kiosks all over NYC but we still don’t have public bathrooms. I’d add that we have “smart” tampons but still don’t make normal tampons available to, for example, homeless women or high school girls.
That’s totally fucked up in both cases, but it’s not because we are in love with the concept of “smart” technology. It’s because that’s where the money is.
Some entrepreneurs have decided that it’d be a smart shrewd investment to install a bunch of wifi kiosks in old telephone booths, grab everyone’s telephone data as they walk by, profile them, and then tailor advertisements to them. They expect to make a big profit from this investment, which you can infer reading the misleading answer to the question, “how is LinkNYC Funded?” on their website:

Can we all agree that’s not what most people mean when they ask, how is this funded? This is more like an answer to the question, how will this make money? Please tell me if you can figure out who actually funds LinkNYC.
Let’s think, by contrast, about how public bathrooms work. They cost money to build and to maintain. And yes, having a good public bathroom system would prevent a lot of nasty things from happening, like a bunch of arrests of people for being poor and having no place to pee, not to mention poop on the street. It’s the right thing to do. But, since we don’t think we will ever get more than half a billion dollars in revenue from them, no thanks.
Similarly, it’s not profitable to give poor women tampons, it’s merely the right thing to do (and it boosts attendance rates of poor girls).
The smart city fad is a boondoggle, a way of giving public space access to private advertising companies in exchange for a few nickels and a surveillance state. It’s kind of ingenious, because it’s in a sense selling a commodity – public space, and the concept of anonymity within a large city – that we didn’t even know we could measure, never mind commoditize. And in the meantime, we cannot expect actual ongoing problems to be addressed. Because we’re too busy being smart.
The US DOE’s sunk costs into for-profit colleges
There’s been a lot of squabbling around how to deal with student debt lately, especially the debt incurred by shitty for-profit colleges. I claim these are sunk costs and should be treated as such.
If you aren’t familiar with the for-profit college boondoggle, let me break it down for you: there’s a federal aid system that guarantees loans to poor students for accredited colleges. This system has been gamed by an industry that includes Corinthian College, ITT Tech, and University of Phoenix, among others. They get accreditation through slimy and questionable means, then they lie to potential students about how great their education will be, then they collect the money.
The issue that the Department of Education (DOE) is now grappling with is this: should those students, who were misled and manipulated, be forgiven their debt?
From the side of the students, it seems pretty clear the answer should be yes. They didn’t receive proper educations, they were lied to and manipulated, and they are, by construction, quite poor. This debt will be hanging over them, making it even harder for them to eke out a living.
From the side of the government, the answer is less obvious. After all, it’s very expensive to write off a bunch of debt. And it would set a dangerous precedent. When would it stop? What if someone who went to a reasonable community college wanted to stop paying their debt? Or what about a graduate from a private college?
I’d argue that this is a sunk cost. Which is to say, the DOE fucked up when it allowed accreditation when it should not have. Once you let your standards go that far, you are on the hook. And although it looks “expensive” to forgive this debt, there’s really no other option, because it’s never getting paid back. That’s what happens when you let a predatory industry prey on the most vulnerable.
So, sunk costs. What’s good about acknowledging sunk costs is that you can learn your lesson and fix the problem that got you into this mess. When you don’t acknowledge sunk costs, you’re in the wrong mindset, hoping against hope that somehow the money will be paid back. It won’t.
What would it mean to fix this problem? We need to turn off the federal aid spigot for bad colleges. We need higher standards for accreditation.
The good news is that the DOE has just come out with recommendations for doing just that. In particular, they’re closing down one of the worst accreditation offenders.
If only they’d just forgive the debt so we could move past this ugly chapter of educational history.



