Columbia Data Science course, week 13: MapReduce
The week in Rachel Schutt’s Data Science course at Columbia we had two speakers.
The first was David Crawshaw, a Software Engineer at Google who was trained as a mathematician, worked on Google+ in California with Rachel, and now works in NY on search.
David came to talk to us about MapReduce and how to deal with too much data.
Thought Experiment
Let’s think about information permissions and flow when it comes to medical records. David related a story wherein doctors estimated that 1 or 2 patients died per week in a certain smallish town because of the lack of information flow between the ER and the nearby mental health clinic. In other words, if the records had been easier to match, they’d have been able to save more lives. On the other hand, if it had been easy to match records, other breaches of confidence might also have occurred.
What is the appropriate amount of privacy in health? Who should have access to your medical records?
Comments from David and the students:
- We can assume we think privacy is a generally good thing.
- Example: to be an atheist is punishable by death in some places. It’s better to be private about stuff in those conditions.
- But it takes lives too, as we see from this story.
- Many egregious violations happen in law enforcement, where you have large databases of license plates etc., and people who have access abuse it. In this case it’s a human problem, not a technical problem.
- It’s also a philosophical problem: to what extent are we allowed to make decisions on behalf of other people?
- It’s also a question of incentives. I might cure cancer faster with more medical data, but I can’t withhold the cure from people who didn’t share their data with me.
- To a given person it’s a security issue. People generally don’t mind if someone has their data, they mind if the data can be used against them and/or linked to them personally.
- It’s super hard to make data truly anonymous.
MapReduce
What is big data? It’s a buzzword mostly, but it can be useful. Let’s start with this:
You’re dealing with big data when you’re working with data that doesn’t fit into your compute unit. Note that’s an evolving definition: big data has been around for a long time. The IRS had taxes before computers.
Today, big data means working with data that doesn’t fit in one computer. Even so, the size of big data changes rapidly. Computers have experienced exponential growth for the past 40 years. We have at least 10 years of exponential growth left (and I said the same thing 10 years ago).
Given this, is big data going to go away? Can we ignore it?
No, because although the capacity of a given computer is growing exponentially, those same computers also make the data. The rate of new data is also growing exponentially. So there are actually two exponential curves, and they won’t intersect any time soon.
Let’s work through an example to show how hard this gets.
Word frequency problem
Say you’re told to find the most frequent words in the following list: red, green, bird, blue, green, red, red.
The easiest approach for this problem is inspection, of course. But now consider the problem for lists containing 10,000, or 100,000, or 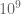
The simplest approach is to list the words and then count their prevalence. Here’s an example code snippet from the language Go:

Since counting and sorting are fast, this scales to ~100 million words. The limit is now computer memory – if you think about it, you need to get all the words into memory twice.
We can modify it slightly so it doesn’t have to have all words loaded in memory. keep them on the disk and stream them in by using a channel instead of a list. A channel is something like a stream: you read in the first 100 items, then process them, then you read in the next 100 items.
Wait, there’s still a potential problem, because if every word is unique your program will still crash; it will still be too big for memory. On the other hand, this will probably work nearly all the time, since nearly all the time there will be repetition. Real programming is a messy game.
But computers nowadays are many-core machines, let’s use them all! Then the bandwidth will be the problem, so let’s compress the inputs… There are better alternatives that get complex. A heap of hashed values has a bounded size and can be well-behaved (a heap seems to be something like a poset, and I guess you can throw away super small elements to avoid holding everything in memory). This won’t always work but it will in most cases.
Now we can deal with on the order of 10 trillion words, using one computer.
Now say we have 10 computers. This will get us 100 trillion words. Each computer has 1/10th of the input. Let’s get each computer to count up its share of the words. Then have each send its counts to one “controller” machine. The controller adds them up and finds the highest to solve the problem.
We can do the above with hashed heaps too, if we first learn network programming.
Now take a hundred computers. We can process a thousand trillion words. But then the “fan-in”, where the results are sent to the controller, will break everything because of bandwidth problem. We need a tree, where every group of 10 machines sends data to one local controller, and then they all send to super controller. This will probably work.
But… can we do this with 1000 machines? No. It won’t work. Because at that scale one or more computer will fail. If we denote by 
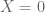
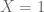

But this means, when you have 1000 computers, that the chance that no computer is broken is 


We address this problem by talking about fault tolerance for distributed work. This usually involves replicating the input (the default is to have three copies of everything), and making the different copies available to different machines, so if one blows another one will still have the good data. We might also embed checksums in the data, so the data itself can be audited for erros, and we will automate monitoring by a controller machine (or maybe more than one?).
In general we need to develop a system that detects errors, and restarts work automatically when it detects them. To add efficiency, when some machines finish, we should use the excess capacity to rerun work, checking for errors.
Q: Wait, I thought we were counting things?! This seems like some other awful rat’s nest we’ve gotten ourselves into.
A: It’s always like this. You cannot reason about the efficiency of fault tolerance easily, everything is complicated. And note, efficiency is just as important as correctness, since a thousand computers are worth more than your salary. It’s like this:
- The first 10 computers are easy,
- The first 100 computers are hard, and
- The first 1,000 computers are impossible.
There’s really no hope. Or at least there wasn’t until about 8 years ago. At Google I use 10,000 computers regularly.
In 2004 Jeff and Sanjay published their paper on MapReduce (and here’s one on the underlying file system).
MapReduce allows us to stop thinking about fault tolerance; it is a platform that does the fault tolerance work for us. Programming 1,000 computers is now easier than programming 100. It’s a library to do fancy things.
To use MapReduce, you write two functions: a mapper function, and then a reducer function. It takes these functions and runs them on many machines which are local to your stored data. All of the fault tolerance is automatically done for you once you’ve placed the algorithm into the map/reduce framework.
The mapper takes each data point and produces an ordered pair of the form (key, value). The framework then sorts the outputs via the “shuffle”, and in particular finds all the keys that match and puts them together in a pile. Then it sends these piles to machines which process them using the reducer function. The reducer function’s outputs are of the form (key, new value), where the new value is some aggregate function of the old values.
So how do we do it for our word counting algorithm? For each word, just send it to the ordered with the key that word and the value being the integer 1. So
red —> (“red”, 1)
blue —> (“blue”, 1)
red —> (“red”, 1)
Then they go into the “shuffle” (via the “fan-in”) and we get a pile of (“red”, 1)’s, which we can rewrite as (“red”, 1, 1). This gets sent to the reducer function which just adds up all the 1’s. We end up with (“red”, 2), (“blue”, 1).
Key point: one reducer handles all the values for a fixed key.
Got more data? Increase the number of map workers and reduce workers. In other words do it on more computers. MapReduce flattens the complexity of working with many computers. It’s elegant and people use it even when they “shouldn’t” (although, at Google it’s not so crazy to assume your data could grow by a factor of 100 overnight). Like all tools, it gets overused.
Counting was one easy function, but now it’s been split up into two functions. In general, converting an algorithm into a series of MapReduce steps is often unintuitive.
For the above word count, distribution needs to be uniform. It all your words are the same, they all go to one machine during the shuffle, which causes huge problems. Google has solved this using hash buckets heaps in the mappers in one MapReduce iteration. It’s called CountSketch, and it is built to handle odd datasets.
At Google there’s a realtime monitor for MapReduce jobs, a box with “shards” which correspond to pieces of work on a machine. It indicates through a bar chart how the various machines are doing. If all the mappers are running well, you’d see a straight line across. Usually, however, everything goes wrong in the reduce step due to non-uniformity of the data – lots of values on one key.
The data preparation and writing the output, which take place behind the scenes, take a long time, so it’s good to try to do everything in one iteration. Note we’re assuming distributed file system is already there – indeed we have to use MapReduce to get data to the distributed file system – once we start using MapReduce we can’t stop.
Once you get into the optimization process, you find yourself tuning MapReduce jobs to shave off nanoseconds 10^{-9} whilst processing petabytes of data. These are order shifts worthy of physicists. This optimization is almost all done in C++. It’s highly optimized code, and we try to scrape out every ounce of power we can.
Josh Wills
Our second speaker of the night was Josh Wills. Josh used to work at Google with Rachel, and now works at Cloudera as a Senior Director of Data Science. He’s known for the following quote:
Data Science (n.): Person who is better at statistics than any software engineer and better at software engineering than any statistician.
Thought experiment
How would you build a human-powered airplane? What would you do? How would you form a team?
Student: I’d run an X prize. Josh: this is exactly what they did, for $50,000 in 1950. It took 10 years for someone to win it. The story of the winner is useful because it illustrates that sometimes you are solving the wrong problem.
The first few teams spent years planning and then their planes crashed within seconds. The winning team changed the question to: how do you build an airplane you can put back together in 4 hours after a crash? After quickly iterating through multiple prototypes, they solved this problem in 6 months.
Josh had some observations about the job of a data scientist:
- I spend all my time doing data cleaning and preparation. 90% of the work is data engineering.
- On solving problems vs. finding insights: I don’t find insights, I solve problems.
- Start with problems, and make sure you have something to optimize against.
- Parallelize everything you do.
- It’s good to be smart, but being able to learn fast is even better.
- We run experiments quickly to learn quickly.
Data abundance vs. data scarcity
Most people think in terms of scarcity. They are trying to be conservative, so they throw stuff away.
I keep everything. I’m a fan of reproducible research, so I want to be able to rerun any phase of my analysis. I keep everything.
This is great for two reasons. First, when I make a mistake, I don’t have to restart everything. Second, when I get new sources of data, it’s easy to integrate in the point of the flow where it makes sense.
Designing models
Models always turn into crazy Rube Goldberg machines, a hodge-podge of different models. That’s not necessarily a bad thing, because if they work, they work. Even if you start with a simple model, you eventually add a hack to compensate for something. This happens over and over again, it’s the nature of designing the model.
Mind the gap
The thing you’re optimizing with your model isn’t the same as the thing you’re optimizing for your business.
Example: friend recommendations on Facebook doesn’t optimize you accepting friends, but rather maximizing the time you spend on Facebook. Look closely: the suggestions are surprisingly highly populated by attractive people of the opposite sex.
How does this apply in other contexts? In medicine, they study the effectiveness of a drug instead of the health of the patients. They typically focus on success of surgery rather than well-being of the patient.
When I graduated in 2001, we had two options for file storage.
1) Databases:
- structured schemas
- intensive processing done where data is stored
- somewhat reliable
- expensive at scale
2) Filers:
- no schemas
- no data processing capability
- reliable
- expensive at scale
Since then we’ve started generating lots more data, mostly from the web. It brings up the natural idea of a data economic indicator, return on byte. How much value can I extract from a byte of data? How much does it cost to store? If we take the ratio, we want it to be bigger than one or else we discard.
Of course this isn’t the whole story. There’s also a big data economic law, which states that no individual record is particularly valuable, but having every record is incredibly valuable. So for example in any of the following categories,
- web index
- recommendation systems
- sensor data
- market basket analysis
- online advertising
one has an enormous advantage if they have all the existing data.
A brief introduction to Hadoop
Back before Google had money, they had crappy hardware. They came up with idea of copying data to multiple servers. They did this physically at the time, but then they automated it. The formal automation of this process was the genesis of GFS.
There are two core components to Hadoop. First is the distributed file system (HDFS), which is based on the google file system. The data stored in large files, with block sizes of 64MB to 256MB. As above, the blocks are replicated to multiple nodes in the cluster. The master node notices if a node dies.
Data engineering on hadoop
Hadoop is written in java, Whereas Google stuff is in C++.
Writing map reduce in the java API not pleasant. Sometimes you have to write lots and lots of map reduces. However, if you use hadoop streaming, you can write in python, R, or other high-level languages. It’s easy and convenient for parallelized jobs.
Cloudera
Cloudera is like Red hat for hadoop. It’s done under aegis of the Apache Software Foundation. The code is available for free, but Cloudera packages it together, gives away various distributions for free, and waits for people to pay for support and to keep it up and running.
Apache hive is a data warehousing system on top of hadoop. It uses an SQL-based query language (includes some map reduce -specific extensions), and it implements common join and aggregation patterns. This is nice for people who know databases well and are familiar with stuff like this.
Workflow
- Using hive, build records that contain everything I know about an entity (say a person) (intensive mapReduce stuff)
- Write python scripts to process the records over and over again (faster and iterative, also mapReduce)
- Update the records when new data arrives
Note phase 2 are typically map-only jobs, which makes parallelization easy.
I prefer standard data formats: text is big and takes up space. Thrift, Avro, protobuf are more compact, binary formats. I also encourage you to use the code and metadata repository Github. I don’t keep large data files in git.
-
December 1, 2012 at 9:40 pmBig Data Quotes of the Week: December 1, 2012 | What's The Big Data?
-
December 3, 2012 at 8:34 amDiophantus and the math arXiv « mathbabe
-
April 8, 2013 at 8:47 amTweenage angst, RSS feeds, and upcoming talks | mathbabe



