Updating your big data model
When you are modeling for the sake of real-time decision-making you have to keep updating your model with new data, ideally in an automated fashion. Things change quickly in the stock market or the internet, and you don’t want to be making decisions based on last month’s trends.
One of the technical hurdles you need to overcome is the sheer size of the dataset you are using to first train and then update your model. Even after aggregating your model with MapReduce or what have you, you can end up with hundreds of millions of lines of data just from the past day or so, and you’d like to use it all if you can.
The problem is, of course, that over time the accumulation of all that data is just too unwieldy, and your python or Matlab or R script, combined with your machine, can’t handle it all, even with a 64 bit setup.
Luckily with exponential downweighting, you can update iteratively; this means you can take your new aggregated data (say a day’s worth), update the model, and then throw it away altogether. You don’t need to save the data anywhere, and you shouldn’t.
As an example, say you are running a multivariate linear regression. I will ignore bayesian priors (or, what is an example of the same thing in a different language, regularization terms) for now. Then in order to have an updated coefficient vector 



So the problem simplifies to, how can we update
As I described before in this post for example, you can use exponential downweighting. Whereas before I was expounding on how useful this method is for helping you care about new data more than old data, today my emphasis is on the other convenience, which is that you can throw away old data after updating your objects of interest.
So in particular, we will follow the general rule in updating an object $T$ that it’s just some part old, some part new:
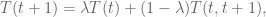
where by 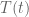
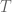
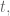


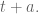
The speed at which I forget data is determined by my choice of 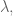
Specifically, I want to give an example of this update rule for the covariance matrix 
Namely, I claim that after updating 
Just to be really dumb, start with a univariate regression example, so where we have a single signal 

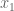


Now we get a new piece of data 
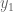

![[\mu x_1 x_2]](https://s0.wp.com/latex.php?latex=%5B%5Cmu+x_1+x_2%5D&bg=ffffff&fg=555555&s=0&c=20201002)

where by 
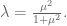
Things to convince yourself of:
- This works when we move from
pieces of data to
pieces of data.
- This works when we move from a univariate regression to a multivariate regression and we’re actually talking about square matrices.
- Same goes for the
- We don’t really have to worry about scaling; this uses the fact that everything in sight is quadratic in
, the downweighting scalar, and the final product we care about is
where, if we did decide to care about scalars, we would mutliply
- We don’t have to update one data point at a time. We can instead compute the `new part’ of the covariance matrix and the other thingy for a whole day’s worth of data, downweight our old estimate of the covariance matrix and other thingy, and then get a new version for both.
- We can also incorporate bayesian priors into the updating mechanism, although you have decide whether the prior itself needs to be downweighted or not; this depends on whether the prior is coming from a fading prior belief (like, oh I think the answer is something like this because all the studies that have been done say something kind of like that, but I’d be convinced otherwise if the new model tells me otherwise) or if it’s a belief that won’t be swayed (like, I think newer data is more important, so if I use lagged values of the quarterly earnings of these companies then the more recent earnings are more important and I will penalize the largeness of their coefficients less).

End result: we can cut our data up into bite-size chunks our computer can handle, compute our updates, and chuck the data. If we want to maintain some history we can just store the `new parts’ of the matrix and column vector per day. Then if we later decide our downweighting was too aggressive or not sufficiently aggressive, we can replay the summation. This is much more efficient as storage than holding on to the whole data set, because it depends only on the number of signals in the model (typically under 200) rather than the number of data points going into the model. So for each day you store a 200-by-200 matrix and a 200-by-1 column vector.




I wrote a quick placeholder note to remind myself to write a more detailed post about challenges with this method and changes in variance.
LikeLike
let’s hear it!
LikeLike