Archive
Pussyhats and the activist knitter
I finally got around to knitting my first pussyhat yesterday, during the inauguration. It took less than two hours because I was using super bulky yarn and because I had lots of anxious energy to tap into.

I got the yarn last Saturday, when I went to a Black Lives Matter march in the morning (you can see my butt multiple times in the embedded video) and then afterwards to Vogue Knitting Live in the Times Square Marriott Marquis.


And here’s the thing, I thought I was going to enjoy the juxtaposition of activist-to-insane hobbiest, but I was wrong – knitters were activists too! Here’s what I saw:

Pink yarn everywhere.

Pussyhats everywhere

Not only women of course! Alex looks dashing with his ombre pussyhat.

Karida Collins doesn’t have a pussyhat on but she’s still killing it.
Since last weekend, I’ve been seeing pussyhats everywhere. You go into a yarn store and here’s what you see.

Or you happen upon an airplane full of women heading to D.C. and here’s what you see.

I’m pretty sure half those women have knitting needles in their laps.
My favorite way to measure this phenomenon is directly, at the source. I am of course referring to Ravelry, the online social media website for knitters and crafters. The pussyhat project has spawned all sorts of creative ideas, of course.
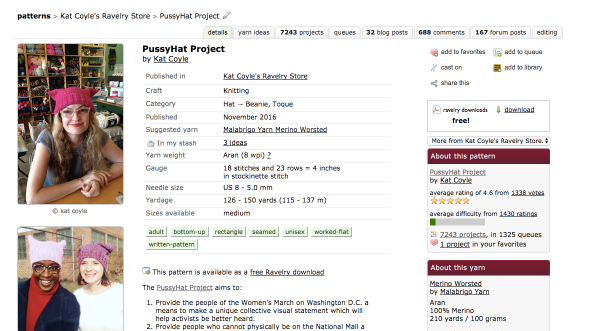
The original pattern has thousands of associated projects
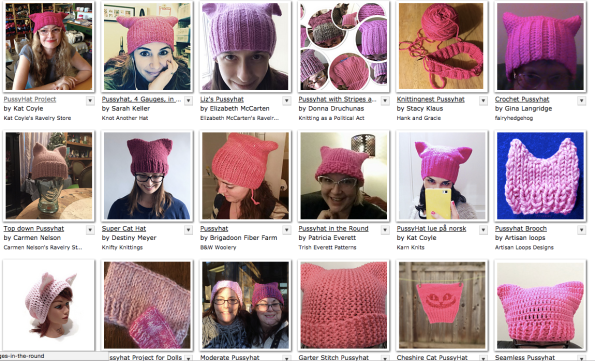
Lots of variations have been invented of course

Here’s a great example

Not particularly cat-like but I like it
Now that it’s happened, it’s obvious that knitters are a perfect community for activism. We’re friendly, community-oriented, and desperate for an opportunity to make something and give it away. Because it gives us an excuse to buy more yarn.
Anyhoo, I’m going to the Women’s March NYC today with mine, and I’m going to try to knit at least one more before I leave at 11am. See you there!


Two out of three “fairness” criteria can be satisfied
This is a continuation of a discussion I’ve been having with myself about the various definition of fairness in scoring systems. Yesterday I mentioned a recent paper entitled Inherent Trade-Offs in the Fair Determination of Risk Scores that has a proof of the following statement:
You cannot simultaneously ask for a model to be well-calibrated, to have equal false positive rates for blacks and whites, and to have equal false negative rates unless you are in the presence of equal “base rates” or a perfect predictor.
The good news is that you can ask for two out of three of these. Here’s a picture of a specific example of this, where I’ve simplified the situation so there are two groups of people being scores, B and W, and they each can be scored as either empty or full, and then the reality is that could either be empty or full. They have different “base rates,” which is to say that in reality, a different proportion of the B group is empty (70%) than the W group (50%). We insist, moreover, that the labeling scheme is “well-calibrated”, so the right proportion of them are labeled empty or full. I’ve drawn 10 “perfect representatives” from each group here:

In my picture, I’ve assumed there was some mislabeling – there’s a full in the empty bin and there are empties in the full bin. Because we are assuming the model is well-calibrated, every time we have one kind of mistake we have to make up for that mistake with exactly one of the other type. In the picture there’s exactly one of each mistake for both the W group and the B group, so that’s fine.
Quick calculation: in the picture above, the “false full rate”, which we can think of as the “false positive rate,” for B is 1/3 = 33% but the “false positive rate” for W is 1/5 = 20%, even though they each have only one mislabeled representative each.
Now it’s obvious that, theoretically, the scoring system could adjust the false positive rate for B to match that of W, which would mean having 3/5 of a representative be mislabeled. But again, that’d mean we would need only 3/5 of a representative be mislabeled in the empty bin as well.
That’s a false negative rate for B of 3/35 = 8.6% (note it used to be 1/7 = 14.3%). By contrast the false negative rate for A stays fixed at 1/5 = 20%.
If you think about it, what we’ve done is sacrificed some false negative rate balance for a perfect match on the false positive rate, while keeping the model well-calibrated.
Applying this to recidivism scores, we can ask for the high scores to reflect base rates for the populations, and we can ask for similar false positive rates for populations, but we cannot also ask for false negative rates to be equal. That might be better overall, though, because the harm that comes from unequal false positive rate – sending someone to jail for longer – is arguably more toxic than an unequal false negative rate, which means certain groups are let off the hook more often than the others.
By the way, I want to be clear that I don’t think recidivism risk algorithms should actually be the goal, summed up in this conversation I had with Tom Slee. I’m not even sure why their use is constitutional, to tell the truth. But given that they are in use, I think it makes sense to try to make them as good as possible, and to investigate what “good” means in this context.
Two clarifications
First, I think I over-reacted to automated pricing models (thanks to my buddy Ernie Davis who made me think harder about this). I don’t think immediate reaction to price changes is necessarily odious. I do think it changes the dynamics of price optimization in weird ways, but upon reflection I don’t see how they’d necessarily be bad for the general consumer besides the fact that Amazon will sometimes have weird disruptions much like the flash crashes we’ve gotten used to on Wall Street.
Also, in terms of the question of “accuracy versus discrimination,” I’ve now read the research paper that I believe is under consideration, and it’s more nuanced than my recent blog posts would suggest (thanks to Solon Barocas for help on this one).
In particular, the 2011 paper I referred defines discrimination crudely, whereas this new article allows for different “base rates” of recidivism. To see the different, consider a model that assigns a high risk score 70% of the time to blacks and 50% to whites. Assume that, as a group, blacks recidivate at a 70% rate and whites at a 50% rate. The article I referred to would define this as discriminatory, but the newer paper refers to this as “well calibrated.”
Then the question the article tackles is, can you simultaneously ask for a model to be well-calibrated, to have equal false positive rates for blacks and whites, and to have equal false negative rates? The answer is no, at least not unless you are in the presence of equal “base rates” or a perfect predictor.
Some comments:
- This is still unsurprising. The three above conditions are mathematical constraints, and there’s no reason to expect that you can simultaneously require a bunch of really different constraints. The authors do the math and show that intuition is correct.
- Many of my comments still hold. The most important one is the question of why the base rates for blacks and whites are so different. If it’s because of police practice, at least in part, or overall increased surveillance of black communities, then I’d argue “well-calibrated” is insufficient.
- We need to be putting the science into data science and examining questions like this. In other words, we cannot assume the data is somehow fixed in stone. All of this is a social construct.
This question has real urgency, by the way. New York Governor Cuomo announced yesterday the introduction of recidivism risk scoring systems to modernize bail hearings. This could be great if fewer people waste time in jail pending their hearings or trials, but if the people chosen to stay in prison are chosen on the basis that they’re poor or minority or both, that’s a problem.
Algorithmic collusion and price-fixing
There’s a fascinating article on the FT.com (hat tip Jordan Weissmann) today about how algorithms can achieve anti-competitive collusion. Entitled Policing the digital cartels and written by David J Lynch, it profiles a classic cinema poster seller that admitted to setting up algorithms for pricing with other poster sellers to keep prices high.
That sounds obviously illegal, and moreover it took work to accomplish. But not all such algorithmic collusion is necessarily so intentional. Here’s the critical paragraph which explains this issue:
As an example, he cites a German software application that tracks petrol-pump prices. Preliminary results suggest that the app discourages price-cutting by retailers, keeping prices higher than they otherwise would have been. As the algorithm instantly detects a petrol station price cut, allowing competitors to match the new price before consumers can shift to the discounter, there is no incentive for any vendor to cut in the first place.
We also don’t seem to have the legal tools to address this:
“Particularly in the case of artificial intelligence, there is no legal basis to attribute liability to a computer engineer for having programmed a machine that eventually ‘self-learned’ to co-ordinate prices with other machines.
How to fix recidivism risk models
Yesterday I wrote a post about the unsurprising discriminatory nature of recidivism models. Today I want to add to that post with an important goal in mind: we should fix recidivism models, not trash them altogether.
The truth is, the current justice system is fundamentally unfair, so throwing out algorithms because they are also unfair is not a solution. Instead, let’s improve the algorithms and then see if judges are using them at all.
The great news is that the paper I mentioned yesterday has three methods to do just that, and in fact there are plenty of papers that address this question with various approaches that get increasingly encouraging results. Here are brief descriptions of the three approaches from the paper:
- Massaging the training data. In this approach the training data is adjusted so that it has less bias. In particular, the choice of classification is switched for some people in the preferred population from + to -, i.e. from the good outcome to the bad outcome, and there are similar switches for some people in the discriminated population from – to +. The paper explains how to choose these switches carefully (in the presence of continuous scorings with thresholds).
- Reweighing the training data. The idea here is that with certain kinds of models, you can give weights to training data, and with a carefully chosen weighting system you can adjust for bias.
- Sampling the training data. This is similar to reweighing, where the weights will be nonnegative integer values.
In all of these examples, the training data is “preprocessed” so that you can train a model on “unbiased” data, and importantly, at the time of usage, you will not need to know the status of the individual you’re scoring. This is, I understand, a legally a critical assumption, since there are anti-discrimination laws which forbid you to “consider” the race of someone when deciding whether to hire them or so on.
In other words, we’re constrained by anti-discrimination law to not use all the information that might help us avoid discrimination. This constraint, generally speaking, prevents us from doing as good a job as possible.
Remarks:
- We might not think that we need to “remove all the discrimination.” Maybe we stratify the data by violent crime convictions first, and then within each resulting bin we work to remove discrimination.
- We might also use the racial and class discrepancies in recidivism risk rates as an opportunity to experiment with interventions that might lower those discrepancies. In other words, why are there discrepancies, and what can we do to diminish them?
- In other words, I do not claim that this is a trivial process. It will in fact require lots of conversations about the nature of justice and the goals of sentencing. Those are conversations we should have.
- Moreover, there’s the question of balancing the conflicting goals of various stakeholders which makes this an even more complicated ethical question.
Recidivism risk algorithms are inherently discriminatory
A few people have been sending me, via Twitter or email, this unsurprising article about how recidivism risk algorithms are inherently racist.
I say unsurprising because I’ve recently read a 2011 paper by Faisal Kamiran and Toon Calders entitled Data preprocessing techniques for classification without discrimination, which explicitly describes the trade-off between accuracy and discrimination in algorithms in the presence of biased historical data (Section 4, starting on page 8).
In other words, when you have a dataset that has a “favored” group of people and a “discriminated” group of people, and you’re deciding on an outcome that has historically been awarded to the favored group more often – in this case, it would be a low recidivism risk rating – then you cannot expect to maximize accuracy and keep the discrimination down to zero at the same time.
Discrimination is defined in the paper as the difference in percentages of people who get the positive treatment among all people in the same category. So if 50% of whites are considered low-risk and 30% of blacks are, that’s a discrimination score of 0.20.
The paper goes on to show that the trade-off between accuracy and discrimination, which can be achieved through various means, is linear or sub-linear depending on how it’s done. Which is to say, for every 1% loss of discrimination you can expect to lose a fraction of 1% of accuracy.
It’s an interesting paper, well written, and you should take a look. But in any case, what it means in the case of recidivism risk algorithms is that any algorithm that is optimized for “catching the bad guys,” i.e. accuracy, which these algorithms are, and completely ignores the discrepancy between high risk scores for blacks and for whites, can be expected to be discriminatory in the above sense, because we know the data to be biased*.
* The bias is due to the history of heightened scrutiny of black neighborhoods by police which we know as broken windows policing, which makes blacks more likely to be arrested for a given crime, as well as the inherent racism and classism in our justice system itself that was so brilliantly explained out by Michelle Alexander in her book The New Jim Crow, which makes them more likely to be severely punished for a given crime.
2017 Resolutions: switch this shit up
Don’t know about you, but I’m sick of New Year’s resolutions, as a concept. They’re flabby goals that we’re meant not only to fail to achieve but to feel bad about personally. No, I didn’t exercise every single day of 2012. No, I didn’t lose 20 pounds and keep it off in 1988.
What’s worst to me is how individual and self-centered they are. They make us focus on how imperfect we are at a time when we should really think big. We don’t have time to obsess over details, people! Just get your coping mechanisms in place and do some heavy lifting, will you?
With that in mind, here are my new-fangled resolutions, which I full intend to keep:
- Let my kitchen get and stay messy so I can get some goddamned work done.
- Read through these papers and categorize them by how they can be used by social justice activists. Luckily the Ford Foundation has offered me a grant to do just this.
- Love the shit out of my kids.
- Keep up with the news and take note of how bad things are getting, who is letting it happen, who is resisting, and what kind of resistance is functional.
- Play Euclidea, the best fucking plane geometry app ever invented.
- Form a cohesive plan for reviving the Left.
- Gain 10 pounds and start smoking.
Now we’re talking, amIright?
Kindly add your 2017 resolutions as well so I’ll know I’m not alone.



