The one great thing about unfair algorithms
People who make their living writing and deploying algorithms like to boast that they are fair and objective simply because they are algorithmic and mathematical. That’s bullshit, of course.
For example, there’s this recent Washington Post story about an algorithm trained to detect “resting bitch face,” or RBF, which contains the following line (hat tip Simon Rose):
FaceReader, being a piece of software and therefore immune to gender bias, proved to be the great equalizer: It detected RBF in male and female faces in equal measure. Which means that the idea of RBF as a predominantly female phenomenon has little to do with facial physiology and more to do with social norms.
While I agree that social norms have created the questions RBF phenomenon, no algorithm is going to prove that without further inquiry. For that matter, I don’t even understand how the algorithm can claim to understand neutrality of faces at all; what is their ground truth if some people look non-neutral when they are, by definition, neutral? The answer entirely depends on how the modeler creates the model, and those choices could easily contain gender bias.
So, algorithms are not by their nature fair. But sometimes their specific brand of unfairness might still be an improvement, because it’s at least measurable. Let me explain.
Take, for example, this recent Bloomberg piece on the wildly random nature of bankruptcy courts (hat tip Tom Adams). The story centers on Heritage, a Texas LLC, which bought up defaulted mortgages and sued 210 homeowners in court, winning about half. Basically that was their business plan, a bet that they’d be able to get lucky with some judges and the litigation courts because they knew how to work the system, even though in at least one case it was decided they didn’t even have standing. Here’s the breakdown:
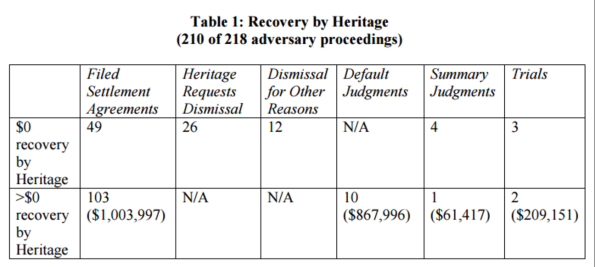
Now imagine that this entire process was embedded in an algorithm. I’m not saying it would be automatically fair, but it would be much more auditable than what we currently have. It would be a black box that we could play with. We could push through a case and see what happens, and if we did that we might create a system that made more sense, or at least became more consistent. If we found that one case didn’t have standing, we might be able to dismiss all similar cases.
I’m not claiming we want everything to become an algorithm; we already have algorithmized too many things too quickly, and it’s brought us into a world where “big data blacklisting” is a thing (one big reason: the current generation of algorithms often work for people in power).
Algorithms represent decision processes that are vulnerable to inspection more than most human-led processes are. And although we are not taking advantage of this yet, we could and should do so soon. We need to start auditing our algorithms, at least the ones that are widespread and high impact.




Mmm. Black-boxes might behave differently when observed/under test. See Volkswagen.
LikeLike
I’d argue that that specific black box was not audited at all. An audit is a serious undertaking.
LikeLike
This is a really good example of social science in action, but perhaps not for the reasons you may think. For instance, did Heritage LLC deliberately select poorer, low-income mortgage defaulters on the basis that they would have less access to legal help and would therefore be more likely to lose the case? Did Heritage select more ‘plaintiff friendly’ courts and justices who would be more likely to find for them, or was the selection random (got this from John Grisham..)?
You can feed such prejudicial pre-engineering factors into this situation *if* the person constructing the algorithm knows about them and can make reasonable assumptions about the likely probabilities arising from Heritage end-loading the probability of success.
But if the program engineer is unaware of these things (and there are a lot of reasons why Heritage isn’t going to tell him/her!) then I defy any algorithm to produce anything that isn’t just random background noise…
LikeLike
When those dictionary folks do their “word of the year” thing again, I think “algorithmized” (or should it be “algorithmitized”) ought be in the mix. 😉
LikeLike
Good point and we are as I stated a few years ago under the Attack of the Killer Algorithms. I put videos from yourself and others that help educate if folks go there to watch them on that page. Being I report on health care, another instance of what drives me crazy too is the marketing of such. Silicon Valley when they delve into healthcare, tend to tell folks they have a new “diagnosis” when in fact what they have created is just another risk assessment with little or no science.
Risk assessments, of course make money as we all get “scored” and those scores and the data gets sold. It’s a big money making tool with selling data and scores worth over $180 billion a year. The prescription game of “scoring” you, huge as every time you get a prescription filled, you are scored with data and the algorithms do their thing. If there’s not enough data, you default to non compliant and are labeled an outlier so if you pay cash and don’t put your prescriptions on a credit card where they can track it, you end up by default as being non compliant. The risk scoring algorithms were first introduced by a company named Ingenix, a subsidiary of United Healthcare. The former CEO of Ingenix is none other than Andy Slavitt who nows runs Medicare, so in essence we have a quant running CMS.
HHS secretary Burwell was Bob Rubin’s chief of staff who was working for him and helped create the Securities Modernization Act of 2000, so sure she wanted a quant in that job to do all her modeling. Anyway back on track here. take a look at the manipulating algorithms flowing out of Silicon Valley, not creating new tech and algorithms that are really helpful, but rather tons of algorithms in apps that score you so that data can be sold and big money gets made. In healthcare, they get around HIPAA all the time by selling a score versus the actual data. Insurance companies buy them up in groves.
http://ducknetweb.blogspot.com/2016/01/silicon-valley-is-at-it-again-confusing.html
LikeLike
Turns out that there were some pretty unfair people running some of those algorithms:
http://www.nydailynews.com/news/national/king-toyota-caught-racist-interest-rate-practices-article-1.2520118
LikeLike
Wow! Thank you.
LikeLike