Nerdy comments about measuring disparate impact
For the past few days I’ve been contemplating how the Consumer Financial Protection Bureau (CFPB), or anyone for that matter, might attempt to measure disparate impact. This is timely because the CFPB is trying to nail auto dealers for racist practices, and an important part of those cases is measuring who should receive restitution and how much.
As I wrote last week, the CFPB has been under fire recently for using an imperfect methodology to guess at a consumer’s race with proxy information such as zip code and surname. Here’s their white paper on it. I believe the argument between the CFPB and the bankers they’re charging with disparate impact hinges on the probability threshold they use: too high, and you get a lot of false negatives (skipping payments to minority borrowers), too low and a lot of false positives (offering money to white borrowers).
Actually, though, the issue of who is what race is only one source of uncertainty among many. Said another way, even if we had a requirement that the borrowers specify their race on their loan application forms, like they do for mortgages because of a history of redlining (so why don’t we do it for other loans too?), we’d still have plenty of other questions to deal with statistically.
Here’s a short list of those concerns, again assuming we already know the minority status of borrowers:
- First, it has to be said that it’s difficult if not impossible to prove an individual case of racism. A given loan application might have terms that are specific to that borrower and their situation. So it is by nature a statistical thing – what terms and interest rates do the pool of minority applicants get on their loans compared to a similar pool of white applicants?
- Now assume the care dealerships have two locations. The different locations could have different processes. Maybe one of them, location A is fairer than the other, location B. But if the statistics are pooled, the overall disparate impact will be estimated as smaller than it should be for location B but bigger for location A.
- Of course, it could also be that different car dealers in the same location treat their customers differently, so the same thing could be happening in one location.
- Also, over time you could see different treatment of customers. Maybe some terrible dude retires. So there’s a temporal issue to consider as well.
- The problem is, if you try to “account” for all these things, at least in the obvious way where you cut down your data, you end up looking at a restricted location, for a restricted time window, maybe for a single car dealer, and your data becomes too thin and your error bars become too large.
- The good thing about pooling is that you have more data and thus smaller error bars; it’s easier to make the case that disparate impact has taken place beyond a reasonable statistical doubt.
- Then again, the way you end up doing it exactly will obviously depend on choices you make – you might end up deciding that you really need to account for location, and it gives you enough data to have reasonably small error bars, but another person making the same model decides to account for time instead. Both might be reasonable choices.
- And so we come to the current biggest problem the CFPB is having, namely gaming between models. Because there are various models that could be used, such as I’ve described, there’s always one model that ends up costing the bank the least. They will always argue for that one, and claim the CFPB is using the wrong model with “overestimates” the disparate impact.
- They even have an expert consultant who works both for the CFPB and the banks and helps them game the models in this way.
For this reason, I’d suggest we have some standards for measuring disparate impact, so that the “gaming between models” comes to an end. Sure, the model you end up choosing won’t be perfect, and it might be itself gameable, but I’m guessing the extent of gaming will be smaller overall. And, going back to the model which guesses at someone’s minority status, I think the CFPB needs to come up with a standard threshold for that, and for the same reason: not because it’s perfect, but because it will prevent banks from complaining that other banks get treated better.




“Sure, the model you end up choosing won’t be perfect, and it might be itself gameable, but I’m guessing the extent of gaming will be smaller overall.”
Sort of like picking a standard set of tests for emissions would prevent auto manufacturers from gaming the tests?
If you have a group of models with disparate results but with equally good arguments for their methodology then the way to prevent gaming is in each case to choose a model randomly. Then the only way to game the system would be to game all the models simultaneously, which we can assume would be extraordinarily difficult if not impossible.
LikeLike
Or, we could say “the model” consists of passing all of those models.
On Wed, Oct 7, 2015 at 9:30 AM, mathbabe wrote:
>
LikeLike
Let’s say that a bank did not want to have a disparate impact. What steps could they take?
I’m not talking about gaming the models or reducing their penalty, I’m talking about honest-to-goodness sincere effort to comply with the law.
LikeLike
If you actually don’t want to have disparate impact in your own processes, one possible method is to decorrelate your data from the problematic attribute (in this case, race). There’s a body of work on ‘algorithmic repair’ that attempts to do this. One approach for example (disclaimer: I work on this problem and have recent work on it) is to merge the conditional distributions on features (conditioned on the problematic attribute) so that information-theoretically you will not be able to incur bias.
LikeLike
Can you send me your stuff?
LikeLike
Sure. the paper appeared in KDD this past August, and a full version is here: http://arxiv.org/abs/1412.3756
LikeLike
Prof. Venkatasubramanian: to me, the key problem with your paper (and I point I was hoping Cathy would address) is the definition of “disparate impact”. You define an algorithm as fair if:
(bottom of page 6 of the PDF).
However, in real life we can already predict the race of the applicants given the inputs of the algorithm. In that case any correlations in the output may very well be due to general problems of society and not due to any bad behaviour by the algorithm. In particular, given the existing inequality of our society, you often do want the outcome of the algorithm to correlate with race — not for a fundamental reason (racism) but for in the contingent sense that (for example) you think credit should be extended based on objective ability-to-pay and unfortunately ability-to-pay correlates with race in our society.
Accordingly I think the correct notion of fairness should be
.
LikeLike
So, Lior is correct in saying that we can’t blame a car dealer if a given customer is poor and therefore gets a shitty loan; we can, however, blame a car dealer for giving an extra shitty loan to a minority poor person over a white poor person.
However, I think Suresh’s paper is attempting to address this question. Suresh, do you want to explain it?
LikeLike
I don’t know if that’s a true statement. I understood disparate to include direct or indirect. Crazy example, what if you decided to charge Democratic voters more than Republican voters. Democratic voters have a higher % of protected minorities than Republican voters. But there are white democratic voters that will pay more as well. The policy still has a disparate impact on minorities or am I wrong?
LikeLike
Hi Lior
Thanks for the comment. You make a very good overall point about fairness that I will address below. But first let me try to clarify what we’re doing. First of all, we start with the working legal definition of disparate impact: namely a large disparity in outcomes between protected and unprotected groups. The question we then ask is: if a black box is deciding the outcomes, and we can’t tell what it does, is there a way to determine a *potential* for disparate impact, even if the blackbox is not using the protected attribute.
The intuition for our answer is simple: if there’s sufficient information in the remaining attributes to reconstruct the protected attribute (a la what the CFPB was trying to do), then it’s possible for an adversary (which the black box could be) to run such a reconstruction procedure, extract the protected attribute, and then discriminate based on it, regardless of what they promise.
How can we measure “sufficient information” ? Well by actually trying to build a classifier to do such a reconstruction ! And that’s where the definition you refer to enters the fray. We establish a quantitative link between the error rate of such a classifier and the legal threshold for a determination of disparate impact.
Notice that under this mechanism, it doesn’t quite matter whether the reconstruction apparatus uses the outcome or not. One can imagine that the “tester” here is testing the internal process before the outcomes are actually declared.
Your point about society as-is (versus what we’d like it to be) is a good one. Much of the literature on discrimination works from an unstated assumption that “all else being equal” there is no intrinsic difference in ability between groups, and that any perceived differences are the result of institutional/systemic or direct bias. If one rejects this assumption, then what we’re proposing (and indeed the very idea of “repair”) doesn’t make sense.
This comment is getting too long :), but there’s a larger point there about what it means for a process to be “fair”.
LikeLike
Oh my god, this is the conversation I’ve always waited for.
There are two really different concepts of fairness going on here, and it’s really interesting. I am going to think further about it. Thanks to both of you!
LikeLike
(sorry, this is a long comment, also, nothing in it is original, but I think this needs to be said)
Suresh: I think you are confirming my understanding that you are thinking about equality of outcome, not equality of opportunity: your “working legal definition of disparate impact” is “a large disparity in outcomes between protected and unprotected groups”. Numerically (your Definition 1.1) following the EEOC you consider “disparate impact” to occur if, on average among all applicants, blacks (say) are approved at 80% the rate of whites or less. This is so even if the black applicants should, for objective reasons, be less successful.
But this definition is (in my opinion) wrong, since this disparity can be caused by factors that are completely outside the algorithm’s control (such as inequality in the society, or choices among the pool of applicants). Moreover, the only way to “fix” this kind of impact is to explicitly consider race. If applying an evenhanded procedure can lead to legal liability when the outcomes are unequal, then the only way to avoid legal liability is reverse racial discrimination: replacing the evenhanded algorithm with one that explicitly considers race (in the case of the auto loans we started with, approve black applicants just because they are black). In other words, this notion of “disparate impact” leads to the perverse situation that the only way to avoid legal liability for racial discrimination is to engage in outright racial discrimination where applicants are considered separately by race.
In fact, as far as I can tell this is exactly what your paper is proposing — to “grade on a curve” where we fit each population to the curve separately. Suppose the bank will decide on loans using a credit score algorithm that, to the best ability of honest an unbiased economists, most predicts ability to pay using the information provided on the applications. One such piece of information is the incomes, so suppose that our two classes of applicants have income distributions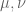 respectively. Your proposal in section 5 is to take the distribution
respectively. Your proposal in section 5 is to take the distribution  which is the midpoint between the two in the
which is the midpoint between the two in the  Kantorovich metric, consider
Kantorovich metric, consider  as the new “income scale” and use the mass transport rules to map incomes for each class separately to the new scale, after which you’ll run the credit score calculation using the scaled incomes.
as the new “income scale” and use the mass transport rules to map incomes for each class separately to the new scale, after which you’ll run the credit score calculation using the scaled incomes.
You say that this “removes the correlation with the characteristic” and “strongly preserves rank” — but (correct me if I’m wrong on this) these statements are trivial since (1) by “strongly preserves rank” you mean “preserves rank within each class“, and (2) of course if I remap the distribution of each race to the same distribution the correlation to race disappears (aside: when there are multiple input variables this wouldn’t the “decorrelation” fail due to cross-correlation? perhaps if you consider the input distributions on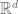 where
where 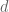 is the number of input variables and take the median in Kantorovich distance there rather than working in each coordinate separately might work — but then you’ll need to explain the relative weights you use for the coordinates).
is the number of input variables and take the median in Kantorovich distance there rather than working in each coordinate separately might work — but then you’ll need to explain the relative weights you use for the coordinates).
Returning to my objections, your curving removes the important information of ranking across classes! What you are doing is exactly saying “we’ll have two income scales; applicants of type 1 with income X will be considered together with applicants of type 2 with (usually lower) income Y”. Moreover, you have tampered with the correlation between credit score and ability-to-pay: because you have remapped the incomes, the predictions of ability-to-pay will be off — too low for one class, too high for the other.
When the bank originally honestly only cared about ability-to-pay the result is incredibly unfair — it is unfair to everyone! To the bank, because now loan terms are not computed by ability-to-pay; to the “majority class” applicants because they now get worse terms that they’d have gotten otherwise, but also to the marginal “minority class” applicants: while they are now being approved for loans they wouldn’t have gotten otherwise, they are being offered loans when the bank honestly believes they wouldn’t be able to pay them. In fact, when they default at high rates and suffer the consequences the bank could very well be accused of discriminating against them by setting them up to fail!
Now you might say that it is fair to ask the relatively well-to-do members of the majority class to accept somewhat worse loan terms in order to subsidize the preferred loan terms offered to the relatively worse-off members of the minority class. But again these are justifications for reverse discrimination, not for a situation where the results are “decorrelated” from race.
LikeLike
Lior few points. First off I agree I think a good system would explicitly consider race. When I received a quote for home insurance that I knew was higher than State averages, I asked the company how can I be assured that there process isn’t discriminatory to minorities? There response was first off they don’t ever ask for race. In their mind that prevents them from discriminating. But in my mind it prevents me from seeing if discrimination is taking place. Because when I look at my neighbor and we are similar and every single was except or skin color I have to wonder why I am paying more? Also there is a major assumption that we are making that may not be true and needs to be scrutinized: “credit score algorithm that, to the best ability of honest an unbiased economists, most predicts ability to pay” – How do we know this is true, when indeed it is a black box proprietary algorithm? What if perhaps that system is biased? Also in the case of the car business, like I mentioned before, dealers can mark up bank loans for extra revenue..ie the buy rate on a loan can be 18% from the bank, and the dealership can offer to the buyer, a 21% deal ( 3% mark up). Maybe for a more “qualified “applicant gets a 4% buy rate from the bank and the dealership offers a 5% loan only a 1% mark up. If you think about this, the mark up is purely based on what the dealer can get away with. Loan interest rates are based on risk, ie the higher perceived risk the higher the expected reward in the form of interest. The mark up the dealer places is not based on risk it is arbitrary and purely based on bias and information asymmetry. Knowing the race is the only way to prevent this, and I don’t like the term reverse discrimination. Its more like a discrimination adjustment.
LikeLike
Brandon: I fully agree that it is often right to consider race explicitly, in my opinion primarily in one of two situations (1) to correct a known bias (2) to get social benefits at the cost of some unfairness. The first of those is “discrimination adjustment”, but the second is definitely reverse discrimination (which doesn’t mean it’s not a good idea).
For example, we know that letters of recommendations for women tend to be written differently than letters of recommendation for men. The only way to deal with it in the short term is to interpret letters for women and men differently. Separately, we can decide that the social benefits of admitting more black students to university are worth the costs both of rejecting better qualified Asian applicants and of the fact that (absent significant extra support) the marginal admitted students are less likely to succeed — and I personally believe this trade-off is a good idea (aside: US public universities can’t use this justification due to the Equal Protection Clause).
But “disparate impact” as defined by Suresh and the courts is a different animal altogether. As you say, the question is “how can I be assured that the process isn’t discriminatory to minorities?”, but their definition of discrimination is about the average outcome and not about the process. So I agree with you that considering race to fix a biased process would be “discrimination adjustment”, but I disagree that this is an appropriate label when race is used to fix the unfortunate outcomes of a fair process. In that case I think “reverse discrimination” is very descriptive.
You worry whether equally situated applicants would have the same results (you, compared with a person of a different race buying the same car, having the same income etc). But the legal notion of “disparate impact” embraces a completely different notion of discrimination — it defines discrimination by comparing _average_ outcomes of applicants from different races. Suppose 64% of white applicants get job offers, but only 38% of blacks and hispanics (see this famous case). Was the process discriminatory or were the white applicants better? According to definition 1.1 of Suresh’s paper, the mere fact that the success rate for non-whites was less than 80% of the success rate of whites should cause us to believe that the process is unfair.
I didn’t argue that banks or dealers or fire departments (thinking of Ricci v. DeStefano) never discriminate. Rather, I think it’s important to remember that often inequality of outcome is due to inequality in society rather than to any bias in the process. Seeing that applicants of race A are, on average, succeeding more than applicants of race B has (among others) the following two extreme explanations: (1) someone is purposefully choosing applicants primarily because of their race (2) the outcomes of a perfectly fair and even-handed procedure (“designed by perfect economists”) reflect differences in society. Simply comparing the success rates by race cannot distinguish the two explanations. I’m not arguing that actual procedures are designed by perfect economists, or that we can know that. I’m rather using this thought experiment to argue that that “disparate impact” as advanced by the courts is not a good notion of discrimination because even perfectly fair algorithms will lead to unequal outcomes.
Turning to the auto loan setting, as you say the dealer has full discretion to offer interest rates, and higher interest rates represent pure profit for the dealer. In this situation the dealer has every motivation to offer the highest interest rate she thinks the applicant will accept, and race (and sex) can be used to predict this latter value. For example, women are less likely to negotiate, so it would rational for the dealer to make them worse offers. Even though the dealer isn’t motivated by animus, I’m happy to declare his policy to have disparate impact.
LikeLike
dear Prof. Venkatasubramanian,
I think the problem is that the notion of “prediction” used in theorem 4.1 of the paper is not the one that connects to the legal or informal concepts of discrimination.
The 4/5 rule is relative to the outcomes of a *given* process (a fixed classifier g(Y), in the terms of your paper). The theorem 4.1 in the paper quantifies over all g(Y) and merely claims that if an outcome triggers the 4/5 rule, there might exist some *other* process than the one really used, that in another universe could have led to the discrepancy.
LikeLike
That’s actually the point of what we’re doing. We’re dealing with a black box process for which we have no way of ascertaining what it MIGHT be doing. So all we can use are worst-case assumptions (which is what we customarily do when dealing with adversarial situations like this) about the black box. In one sense, we’re making arguments about information flow and using that to make arguments about what could POTENTIALLY be a problem. Conversely, what this also means is that if the algorithm does NOT find a potential problem, then there’s no way the black box can be problematic (of course with appropriate numerical thresholds in place of “does not” and “no way” and “problematic”)
LikeLike
I agree that it’s the crux of the paper (that’s why I mentioned it). The difficulty I am getting at is that the
definitions used in the paper defeat any obvious connection to situations where the legal or informal concept of discrimination is at issue.
The worst-case analysis is relevant only to the Accuser side of this adversarial game. The Discriminator side knows what class of algorithms he might use, and can test them directly against the 4/5 rule. To run the analysis, Accuser needs a data set that includes sensitive personal variables X (race, gender, age, citizenship etc) together with whatever other variables Y are known to be potentiaily used in the decision (such as income, vocation, zipcode, medical history). Typically the Y variables correlate with the X and are subject to the same access restrictions. How is it possible to have that kind of rich data in hand, but not know the outcomes and not be aware of any restriction on the universe of algorithms? if we are talking about
outcomes that don’t exist yet, Accuser could use a mock data set from other sources, but then he would also have mock outcomes at hand to run the 4/5 rule.
Where would the proxy of a classifier become relevant?
LikeLike
Hi Lior, (and Cathy, feel free to tell us to take it offline if we’re clogging your comments :))
1) on the definition of DI: recall that this is not “our” definition. This is the legal definition. You’re entitled to disagree over whether it’s reasonable, but it is what it is.
2) Regardless, the discussion of whether it’s “wrong” hinges as I said on different ideas of what is fair, and what we believe to be baseline assumptions about society at large. It’s not possible to debate the tools if there is basic disagreement on the assumptions. And I emphasize that I’m not claiming that one side is “wrong”.
3) Legal liability is not automatic if a finding of disparate impact is made. There’s a ‘business justification’ clause: if the entity can show that there’s a solid business justification for its process, it’s off the hook. In practice, this actually makes WINNING a discrimination case quite difficult: the courts have been sympathetic to business justification claims, partly for the reasons you mention.
4) you’re right that we remove information that might potentially prove to be “useful”. And this is the fairness-utility tradeoff we discuss in the paper. What makes this discussion harder than say the privacy-utility tradeoffs that show up in the privacy literature is that we don’t have a good working definition of utility. We define “utility” as “what we did before all this masking”. But if that set of outcomes is benefiting from biased decision making, then saying that we want to preserve the “quality” of that characterization sets an unfair standard. On the other hand, maybe it isn’t, and we should preserve it. Either way, we don’t really know and that makes this hard to address. In the paper, we punted on this by accepting pre-repair outcomes as the benchmark to match.
Hope this helps. I suspect we’re at the point where email might be a better way to discuss this. But I thank you for your comments thus far. They are very pertinent.
LikeLike
I skimmed through your blog and am very impressed. I wish I had more time to fully digest your points. As a minority this issue is close to my heart. I think you do what you said you can’t do. The available data is for everyone, that is your known. You can aggregate by the different terms and interest rates(interest rates by the way is part of the problem, most people don’t know dealerships mark up the interest rates), and by location. Then you have to look on an individual basis. IE someone who has made a complaint. I think what you will find is exactly what CFPB is getting under fire for, the locations in the hood will always offer worse deals than in areas where the people are used to getting good deals.
LikeLike
Re: your #7, I think you’d be interested in this exercise in “crowdstorming” a dataset:
http://andrewgelman.com/2015/01/27/crowdsourcing-data-analysis-soccer-referees-give-red-cards-dark-skin-toned-players/
Briefly, a bunch of analytical teams were given the same dataset on red cards in soccer and asked to test the “same” hypothesis (dark-skinned players get more red cards) in whatever manner they deemed best. The teams made different analytical decisions and got quite different answers, although not radically different. Which of course means that, technically, they didn’t all end up testing *exactly* the “same” hypothesis.
I thought this was a nice illustration of how the choice of *exactly* what question to ask and *exactly* how to answer it can have big effects on one’s statistical results. Even when one has no obvious bias or axe to grind (contra the auto dealers in your example), and when all choices of how to define the question and answer it are prima facie reasonable.
LikeLike
Fantastic example, thanks!
LikeLike
To the CFPB’s credit, they did release their (Stata) code to GitHub so that anyone can use it; I ported some of it to R for my old job.
I think their imputation method is actually fairly sophisticated, at least compared to the rest of the testing process, which basically amounts to NHSTing race coefficients in a logistic regression with a few control variables such as seasonality.
There didn’t really seem to be any standard of which control variables to include or minimum effect sizes for the tests, that was mostly left as researcher degrees of freedom, nor were those models really ever developed with ‘big data’ in mind.
LikeLike
To begin to talk about measuring disparate impact, one needs to understand patterns by which measures tend to be affected by the frequency of an outcome, including the pattern whereby the rarer an outcome the greater tends to be the relative difference in experiencing it and the smaller tends to be the relative difference in avoiding it. Commonly observers measure disparate impact in terms of relative differences in favorable outcome like test passage (as with the four-fifths rule of the Uniform Guidelines on Employee Selection Procedures) or relative differences in adverse outcomes like test failure. But lowering a test cutoff, while tending to reduce relative difference in pass rates, tends to increase relative difference in failure rates. See Table 1 and Figure 1 of reference 1. Similarly, relaxing mortgage lending standards, while tending to reduce relative differences in mortgage approval rates, will tend to increase relative differences in mortgage rejection rates. Very few people, however, are aware that it is even possible for the two relative differences to change in opposite directions as the frequency of an outcome changes, much less that they tend to do so systematically. Thus, in many contexts the government encourages entities covered by civil rights laws to reduce the frequency of adverse outcomes while mistakenly believing that doing so will reduce relative differences in those outcomes. The exact opposite is the case. Even when one understands patterns by which measures tend to change as the frequency of an outcome changes, determining whether actions reduce or increase an impact can be very difficult. See reference 4 at 27-32 and its Appendix A (at 39).
1. Letter to American Statistical Association (Oct. 8, 2015)
Click to access Letter_to_American_Statistical_Association_Oct._8,_2015_.pdf
2. Letter to United States Department of Justice and City of Ferguson, Missouri (Mar. 9, 2015)
Click to access Letter_to_Department_of_Justice_and_City_of_Ferguson_Mar._9,_2015_.pdf
3. “Misunderstanding of Statistics Leads to Misguided Law Enforcement Policies,” Amstat News (Dec. 2012)
http://magazine.amstat.org/blog/2012/12/01/misguided-law-enforcement/
4. “The Mismeasure of Discrimination,” Faculty Workshop, University of Kansas School of Law (Sept. 20, 2013)
Paper: http://jpscanlan.com/images/Univ_Kansas_School_of_Law_Faculty_Workshop_Paper.pdf
LikeLike
As despicable as racism is, might I suggest that thoughts aren’t illegal. If banks or auto-dealers or whoever are not falsifying anything to minority applicants, then really no crime is committed that an agency of the likes of the CFPB can prosecute.
LikeLike
That might be your opinion but it’s not the law. That is to say, it’s against the law to treat black customers worse than white customers in the realm of credit.
LikeLike