Archive
HCSSiM Workshop day 10
This is a continuation of this, where I take notes on my workshop at HCSSiM.
Quadratic equations modulo p
We looked at the general quadratic equation 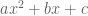
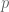

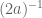

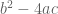
We then defined the Jacobi symbol 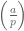

Cantor
We then reviewed some things we’d been talking about in terms of counting and cardinality, we defined the 



Then we used Cantor’s argument to show the power set of a set always has strictly bigger cardinality than the set.
Euler and planar graphs
At this point the CSO (Chief Silliness Officer) Josh Vekhter took over class and described a way of assessing risk for bank robbers. You draw out a map of a bank as a graph with vertices in the corners and edges as walls. It can look like a tree, he said, but it would be a pretty crappy bank. But no judgment. He decided that, from the perspective of a bank robber, corners are good (more places to hide), rooms are good (more places for money to be stashed) but walls are bad (more things you need to break through to get money.
With this system, and assigning a -1 to every wall and a 1 to every corner or room, the overall risk of a bank’s map consistently looks like 2. He proved this is always true using induction on the number of rooms.

How to lie with statistics, Merck style
In the pharmaceutical industry, where companies are making enormous bets with huge money and people’s lives, it makes sense that there are conflicting interests. The companies, who are in charge of testing their drugs for safety and for successful treatment, tend to want to emphasize the good and ignore the bad.
That’s why they are expected to describe beforehand how they are planning to do the tests. It stands to reason that, if they did a thousand tests and then only reported on the best ones, the public would get a biased view of the safety of their products.
For some reason, though, this standard doesn’t seem to be universally followed, and lying with statistics seems to be okay.
The newest example comes from Merck (see Pharmalot article here), which changed its statistical methods on testing Vioxx for Alzheimer’s patients from an intent-to-treat analysis to an on-treatment analysis even though their stipulated plans were the former. And even though the standard in the industry is the former.
Intent-to-treat means you choose people and stick with them, even if they get off the drug for some reason. And on-treatment only counts people that stay on the drug the whole time.
The difference is one of survivorship bias; there may be a good reason someone gets off the drug, and that may be because they got sick, and maybe they got sick because they were taking the drug.
What’s the difference in this case? From the article:
A subsequent intent-to-treat analysis found that as of April 11, 2002, when the FDA approved Vioxx labeling, there were 17 confirmed cardiovascular deaths on Vioxx compared with five on placebo in the same two trials.
With their on-treatment analysis, though, they didn’t see an elevated risk. So as it turns out the actual heart attacks happened a couple of weeks after people got off the pill.
So what happened there? Why were they allowed to change their stipulated method? Why were they allowed to not report their stipulated, gold-standard method? That’s complete bullshit and it must mean that someone at the FDA is either insanely stupid or very rich. Or both.
I’ve written about this issue before, specifically here. Just let me remind you of how we might assess the damage done by Merck through their statistical shenanigans:
Also on the Congress testimony I mentioned above is Dr. David Graham, who speaks passionately from minute 41:11 to minute 53:37 about Vioxx and how it is a symptom of a broken regulatory system. Please take 10 minutes to listen if you can.
He claims a conservative estimate is that 100,000 people have had heart attacks as a result of using Vioxx, leading to between 30,000 and 40,000 deaths (again conservatively estimated). He points out that this 100,000 is 5% of Iowa, and in terms people may understand better, this is like 4 aircraft falling out of the sky every week for 5 years.
According to this blog, the noticeable downwards blip in overall death count nationwide in 2004 is probably due to the fact that Vioxx was taken off the market that year.
Finally, I’d like to reiterate my question, why are pharmaceutical companies allowed to do their own trials?
HCSSiM Workshop day 9
A continuation of this, where I take notes on my workshop at HCSSiM.
First we had a few proofs from the previous night’s problem set, including a proof of Hall’s Marriage Problem using Dilworth’s Theorem.
Counting stuff
We then proved an uncountable set union a countable set is uncountable, with the help of Lior’s comment from yesterday.
Then we proved the Cantor-Schroeder-Bernstein Theorem, which states that if you have two injective maps 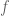

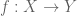

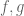


It doesn’t take much thinking to convince yourself that these orbits come in three forms: an infinite list in both directions, a finite loop, or an infinite forward path but a finite backwards path, where at some point you can’t pull back any more. In the last case you could get “stuck” in either 

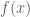



Now that I think of it, I’m pretty sure this proof uses the axiom of choice, and according to the wikipage on this theorem it doesn’t need to, but I don’t know a proof which avoids it. The truth is I can never tell. Please explain to me if you can, how you can verify if you’re using the axiom of choice in an argument where you make infinitely many decisions.
Homomorphisms
We defined a homomorphism of groups and wrote it in both additive and multiplicative notation, because it turns out some of the students were getting confused. We proved very basic properties that follow such as the fact that the identity element goes to the identity element under a homomorphism, and the image of the inverse of an element is the inverse of the image. We ended by asking them to consider the set of homomorphisms between a cyclic group of 6 elements and itself, or between a cyclic group of 6 elements to a cyclic group of 7 elements.
Fermat and Wilson
Next we whipped out some theorems modulo a prime 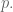


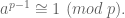

Next, we wondered, what was that product of all those non-zero numbers mod
Mathematicians know how to admit they’re wrong
One thing I discussed with my students here at HCSSiM yesterday is the question of what is a proof.
They’re smart kids, but completely new to proofs, and they often have questions about whether what they’ve written down constitutes a proof. Here’s what I said to them.
A proof is a social construct – it is what we need it to be in order to be convinced something is true. If you write something down and you want it to count as a proof, the only real issue is whether you’re completely convincing.
Having said that, there are plenty of methods of proof that have been standardized and will help you in your arguments. There are things like proof by contradiction, or the pigeon hole principle, or proof by induction, or taking cases.
But in the end you still need to convince me; if you say there are three cases to consider, and I find a fourth, then I’ve blown away your proof, even if your three cases looked solid. If you try to prove something by induction, but your inductive step argument fails going from the case n=16 to n=17, then it’s not a proof.
Ultimately, then, a proof is a description of why you think something is true. The first half of your training is to problem solve (so, come up with a reason something is true) and construct a really convincing argument.
Coming at it from the other side, how can you check that what you’ve got is really a proof if you’ve written down the reason you think it’s true? That’s when the other half of your training comes in, to poke holes in arguments.
To be a really good mathematician you need to be a skeptic and to walk around with a metaphorical gun to shoot holes in other people’s arguments. Every time you hear a reasoned explanation, you look for the cases it doesn’t cover or the assumptions it’s making.
And you do the same thing with your own proofs to help yourself realize your mistakes before looking like a fool. Because putting out a proof of something is tantamount to asking for other people to shoot holes in your argument.
For that reason, every proof that one of these young kids offers up is an act of courage. They don’t know exactly how to explain their thinking, nor do they yet know exactly how to shoot holes in arguments, including their own. It’s an exercise in being wrong and admitting it. They are being trained to get shot down, to admit their mistake, and then immediately get back up again with better reasoning. The goal is to get so good at being wrong that it doesn’t hurt, that it’s not taken personally, and that it’s even fun to be wrong and to improve your argument.
Not every person gets trained in being wrong and admitting it. I’d wager that most people in the world, for most of their professional lives, are trained to do the opposite in the face of being wrong: namely, to wriggle out of it or deflect criticism. Most disciplines spend more time arguing they’re right, or at least not as wrong, or at least they have different mistakes, than other related fields. In math, you can at the most argue that what you’re doing is more interesting or somehow more important than some other field.
[I’ve never understood why people would think certain math is more important than other math. It’s almost never on the basis of having applications in the real world, or helping people in some way. It’s just some arbitrary snobbery, or at least that’s how it’s seemed. For my part I can’t explain why I love number theory more than analysis, it’s pure sense of smell.]
Most people never even say something that’s provably wrong in the first place. And that makes it harder to prove they’re wrong, of course, but it doesn’t mean they’re always right. Since they’ve not let themselves get pinned down on a provably wrong thing, they tend to stick with their wrong ideas for way too long.
I’m a huge fan of skepticism, and I think it’s generally undervalued. People who run companies, or universities, or government agencies, typically say they like healthy skepticism but actually want people to drink the kool aid. People who are skeptical are misinterpreted as being negative, but there’s a huge difference: negative means you’re not trying to solve the problem, skeptical means you care enough about the problem to want to solve it for real.
Now that I’ve thought about the training I’ve received as a mathematician, though, and that I’m now giving that training to these new students, I’ll add this to my defense of skepticism: I’m also a huge fan of people being able to admit they’re wrong. It’s the flip side of skepticism, and it’s why things get better instead of stay wrong.
By the way, one caveat: I’m not claiming that mathematicians are any better at admitting they’re wrong outside a strictly logical sphere.
HCSSiM Workshop day 8
A continuation of this, where I take notes on my workshop at HCSSiM.
We first saw presentations from the students from last night’s problem set. One was a four line proof that the last two digits of 
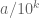

Dillworth’s Theorem Revisited
After going over examples of chains and antichains, and making sure we knew that there must be at least as many chains as there are elements in an anti-chains if we want the chains to cover our set, we set up a proof by induction on the number of elements in our set. The base case is easy (one element, one chain, one element in a maximal anti-chain) and then to reduce to a smaller case we remove any maximal element 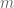

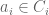

We then stated two lemmas. The first is that any maximal anti-chain must have a unique element in each chain $C_i$, and the second is that, after defining the elements 
Now we put back the removed point 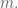
In the first case, we have an anti-chain of size 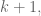
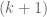
In the second case, 



Dihedral Groups
After reviewing the formal definition of a Karafiol (group), we used rotations and flips of a folder and then of a regular 5-gon to come up with a non-commutative group. We defined a subgroup and explored the different subgroups of the dihedral group as well as other examples we’d seen coming from modular arithmetic.
Euler’s Totient function
We introduced the number of positive integers less than 

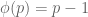
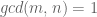
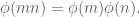




We ended by proving Euler’s formula by induction on the number of distinct prime factors:

HCSSiM Workshop day 7
A continuation of this, where I take notes on my workshop at HCSSiM.
The real numbers are uncountable
Today we used Cantor’s diagonal argument to prove that the real numbers aren’t countable. Namely, we assumed they were, and that we had a bijection 



Then we wanted to show that 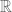

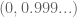
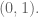
So then we decided to instead consider the set of decimal expansions, which is a bit bigger than the reals, and there the splicing map works. We reduced it to this case and are leaving it to homework to prove that the set of decimal expansions has the same cardinality as the reals. Although I don’t actually know how to do this without Cantor-Schroder-Bernstein, which we haven’t proven yet.
The Chinese Remainder Theorem
We stated and proved the Chinese (Llama) Remainder Theorem. It was a nice example of a constructive proof that assumes it’s possible and then, when you follow your nose, it’s possible to completely characterize what the solution must look like, and then it falls out. We showed it described a bijection of sets 
Dilworth’s Theorem on chains and anti-chains in posets
We started the proof of Dilworth’s Theorem but didn’t finish yet (to be continued tomorrow). Turns out that this problem is really hard and that, moreover, there are lots of ways to convince yourself it’s true but be wrong about. The inductive proof in wikipedia, for example, is incomplete, but can be extended to a complete proof.
As an example, try to cover the following poset on the power set of five letters with 10 chains:

In particular you can see we solve a matching problem on the way, between subsets of size two and subsets of size 3 in the set of five letters, which isn’t the normal “take the complement” match, but rather is an inclusion of one in the other. I’m still wondering if there’s a more direct way to do this.
Center for Popular Economics Summer Institute 2012
I’ll going to be giving a plenary talk on Tuesday, July 24th at the CPE Summer Institute 2012, which is being held this summer at Columbia the week of July 23rd – July 27th. I’ll be joined by Richard Wolff, an economist, radio show host, and author of multiple books, most recently Occupy the Economy. You can register for the Institute here (sliding scale).
The Summer Institute open to non-experts to teach them about the financial system and economics. They have two core courses, one based in the U.S. and the other international. From their web page:
The U.S. Economy/ Topics include
» Roots of the economic meltdown and solutions
» Speculation, finance and housing bubbles
» Economy, race, class and gender
» Economic histories – from personal to global
» Labor and jobs
» Democratizing the Federal Reserve and banks.
» Economic alternatives, socialism and the solidarity economy
The International Economy/ Topics include
» Roots of the economic meltdown and solutions
» Brief history of the global economy
» International trade, production and finance
» The IMF, World Bank, WTO
» Global climate change and the environment
» Creating a new world economy
In addition to hosting this cool and open Summer Institute, the Center for Popular Economics also recently came out with a booklet explaining some economic history of the U.S. written for the non-expert; take a look here.
I’m about halfway through, and I’ve spotted things you usually don’t see in economics texts you might read in high school, such as the following phrase:
So What Caused This Crisis?
Neoliberal capitalism has had three features that both explain how it promoted 25 years of economic expansions and why it led to a massive crisis in 2008. First, inequality grew rapidly, as profits rose while workers’ wages actually fell. From 1979 to 2007, the average inflation-corrected hourly wage of non-supervisory workers declined by 1 percent, while inflation-corrected nonfinancial corporate profits after taxes rose by a remarkable 255 percent. While surging profits pleased the capitalists, it brought a problem: who could buy the growing output that comes with economic expansion? The solution was debt. Somehow, people would have to borrow more and more if a form of capitalism that brings skyrocketing profits and falling wages was to function.
I think it would be cool to have a typical high school “history of economics” text side by side with this one, and have students read both and argue them.
I’m going to try to go to as much of the Summer Institute as I can as a student. I hope I see you there!
Toilet paper rant
I’ve been here at HCSSiM for almost exactly a week now, and I’ve been exclusively blogging about what mathematics we’ve been teaching this year’s brilliant crop of high school kids. Considering the fact that I usually have lots of opinions on important subjects such as financial reform, data science, and the incorrigible misuse of statistics, you might think I’m dying to also post about such things now that it’s Sunday and I’ve finally had time to catch up on some sleep.
You’d be wrong.
What I really need to vent about this afternoon is toilet paper dispensers. You see, I’ve been using lots of bathrooms with stalls and with those new-fangled huge toilet paper dispensers.
Do you remember in the olden days when a toilet paper dispensing system was relatively easy to understand? There’d be room for at most two rolls, the normal smallish kind, and if that wasn’t enough there’d be extra rolls somewhere for you to use. Granted, sometimes there weren’t, and sometimes there were but they got wet or dirty rolling on the floor.
Nowadays there are they enormous plastic cases which contain about 4 huge rolls of toilet paper, and I guess it’s a good thing in terms of how often toilet paper runs out, although it’s not an excellent idea in terms of the overall cleanliness of the bathroom, since you can mostly fill those fuckers up and leave for vacation.
But I’m not here to complain about dirty bathrooms. What I’d like to complain about is that these huge toilet paper dispensers, which are now about 3 feet in diameter, are for some reason always placed at the same level, at their center, as their older counterparts which contained two small rolls and opened up in the front.
The old dispenser would allow you to get toilet paper at approximately shoulder level. It was a pretty good system.
But these new ones dispense out at the bottom, so now we’re immediately talking about having to bend down to even find a corner of paper, usually blind. God forbid if it’s a new roll.
And once you catch hold of the ephemeral toilet paper corner, you have to then pull out some paper, which sounds easy, but your natural inclination is to pull on the paper by pulling towards yourself. This causes your tiny little corner of toilet paper to be immediately cut off by the serrated edge of the dispenser mouth.
So what you need to do, unless you are satisfied with one square inch of toilet paper (which I am not, in general), is you need to devise a two-handed system of pulling where one hand acts as a soft corner, almost like a ball bearing pulley, directly below the dispenser mouth, and the other hand pulls on it, at first straight down and then around the other hand and up.

A metaphorical second hand when desperately grasping for toilet paper
But mind you, you’re already stooping over to get the paper. So at this point you are basically on hands and knees trying to get more than one square inch of goddamned toilet paper.
People. People. People who install bathrooms, I’m talking to you right now.
Don’t you ever go to the bathroom yourself? Can’t you modify your installation procedure now that these big toilet roll dispensers have been around now for 10 years? Can we get them to dispense at shoulder level some time in the near future? Is this some way of keeping people from using too much toilet paper? If so, it’s not working. I always take too much because I always figure, “what the hell, now that I’ve constructed a pulley system I might as well see what she can do. I’ma gonna let her rip.”
HCSSiM Workshop day 6
A continuation of this, where I take notes on my workshop at HCSSiM.
What is a group
We talked about sets with addition laws and what that really means. We noted that associativity seems to be a common condition and that some weird operations aren’t associative. Example: define 
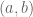
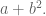
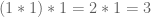
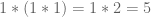
We decided those things would make them crappy generalized addition operators. We ended up by defining what a group is, although we call it a “Karafiol” so that when our final senior staff member P.J. Karafiol arrives in a couple of weeks he will already be famous.
We showed that 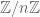

Graphs
We had already talked about graphs (“Visual Representations”) as defined by vertices and edges. Today we talked about being able to put vertices in different groups depending on how the edges go between groups, so we ended up talking about bipartite and tripartite graphs. We ended up being convinced that the complete bipartite graph on 6 vertices (so 3 on each side) is not planar. But we haven’t proven it yet.
Special Lecture
Saturday morning we have only two hours of normal class, instead of 4, and we have a special event for the late morning. Yesterday Johan was visiting so he talked to them about the projective plane over a finite field, and how every line has the same number of points. He talked to them a bit about his REU at Columbia and his Stacks Project and the graph of theorems t-shirt that he wore to the talk. I think it’s cool to show the students this kind of thing because they are the next generation of mathematicians and it’s great to get them into online collaborative math as soon as possible. They were impressed that the Stack Project is more than 3000 pages.

HCSSiM Workshop day 5
A continuation of this, where I take notes on my workshop at HCSSiM.
Modular arithmetic
We examined finite sets with addition laws and asked whether they were the “same”, which for now meant their addition table looked the same except for relabeling. Of course we’d need the two sets to have the same size, so we compared 
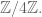
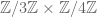

We essentially finished by proving the base case of the Chinese Remainder Theorem for two moduli, which for some ridiculous reason we are calling the Llama Remainder Theorem. Actually the reason is that one of the junior staff (Josh Vekhter) declared my lecture to be insufficiently silly (he designated himself the “Chief Silliness Officer”) and he came up with a story about a llama herder named Lou who kept track of his llamas by putting them first in groups of n and then in groups of m and in both cases only keeping track of the remaining left-over llamas. And then he died and his sons were in a fight over whether someone stole some llamas and someone had to be called in to arbitrate. Plus the answer is only well-defined up to a multiple of mn, but we decided that someone in town would have noticed if an extra mn llamas had been stolen.
Cardinality
After briefly discussing finite sets and their sizes, we defined two sets to have the same cardinality if there’s a bijection from one to the other. We showed this condition is reflexive, symmetric, and transitive.
Then we stopped over at the Hilbert Hotel, where a rather silly and grumpy hotel manager at first refused to let us into his hotel even though he had infinitely many rooms, because he said all his rooms were full. At first when we wanted to just add us, so a finite number of people, we simply told people to move down a few times and all was well. Then it got more complicated, when we had an infinite bus of people wanting to get into the hotel, but we solved that as well by forcing everyone to move to the hotel room number which was double their first. Then finally we figured out how to accommodate an infinite number of infinite buses.
We decided we’d proved that 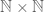
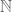

We ended by asking whether the real numbers is lodgeable.
Complex Geometry
Here’s a motivating problem: you have an irregular hexagon inside a circle, where the alternate sides are the length of the radius. Prove the midpoints of those sides forms an equilateral triangle.
It will turn out that the circle is irrelevant, and that it’s easier to prove this if you actually Circle is entirely prove something harder.
We then explored the idea of size in the complex plane, and the operation of conjugation as reflection through the real line. Using this incredibly simple idea, plus the triangle inequality, we can prove that the polynomial
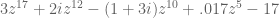
has no roots inside the unit circle.
Going back to the motivating problem. Take three arbitrary points A, B, C on the complex plane (i.e. three complex numbers), and a fourth point we will assume is at the origin. Now rotate those three points 60 degrees counterclockwise with respect to the origin – this is equivalent to multiplying the original complex numbers by 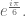
HCSSiM Workshop day 4
A continuation of this, where I take notes on my workshop at HCSSiM.
As usual, we started with the students showing us solutions to their problem sets. Today one of them showed a sharp lower bound on the Fibonacci numbers, although he hadn’t proved it was sharp.
Arithmetic modulo n
Then we talked more about how we can talk about addition, and now also multiplication, with a finite set of symbols 




Finally, we wrote down the subsets of 

Posets and graphs
We went back to the idea of a partial ordering, and came up with a bunch of examples (including the set of integers under “divides evenly into”). We talked for a while about how to represent partial orderings, and finally settled on a graph. We talked a bit about poset chains and antichains, and then we formally defined a graph (we voted and decided to call it a “visual representation”).
The complex plane
The founder and director of the program is David Kelly. The program has been going for 40 years now and for maybe the first time ever Kelly himself isn’t teaching a workshop, so I’ve invited him to do some guest lectures in my workshop on complex geometry. It’s always a treat to watch him teach.
Kelly came in and built on the idea of “modding out by an integer” by definine ![\mathbb{R}[x]/(x^2 +1),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5Bx%5D%2F%28x%5E2+%2B1%29%2C&bg=ffffff&fg=555555&s=0&c=20201002)

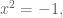

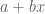
We then defined 


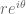

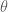
We heard a funny story Kelly told us about taking a test to get his pilot’s license. He was given 30 minutes and lots of suggestions once to compute a heading which involved a calculation in polar coordinates. Since he was a mathematician he was too proud to accept the props they offered him, and finished with 29 minutes to spare. Once aloft though he quickly realized his calculation simply couldn’t be correct, but fudged the test by eyeballing it and following a highway. Turns out that pilots use due north as the axis along which the angle is zero, and then they go clockwise from there. I’m not sure what the moral of the story is, but it’s something like, “don’t be arrogant unless it’s a clear day and you have a backup plan.”
Nim
Yesterday I gave a “Prime Time” talk here at HCSSiM, which is an hour long talk to the entire program. I talked about the game of Nim.
Nim is an old game (that’s the kind of in-depth historical information you’re gonna get from me) where you have a certain number of piles and each pile has a certain number of stones in it. There are two players and you take turns removing as many stones from any one pile as you want. The last person to remove a stone wins. Or, to anticipate my confusion later on, the person who gives back an empty game to their opponent wins.
You can play Nim online here with 3 or more piles and where the stones are matchsticks.
A bunch of the kids had never played so I got them to come to the board to play 2- and 3-pile Nim. Eventually it was discovered that, as long as you start out with uneven piles with 2-pile Nim, you have a winning strategy by making them even. But it wasn’t clear how to win with 3-pile Nim, so we put that question in our back pocket for later.
I then changed it up a bit and put a rook on a chessboard, and said the point was to land on the top left corner, and you could only go up and to the left. They quickly realized it was just two-pile Nim again and the winning strategy was to get the rook on the diagonal. Then I switched it up further and made it be a queen, not a rook, and allowed the piece to move up, left, and diagonally up and left. This was harder.
We then decided that, when you have a game like Nim which is two-player, and the players share the same pieces (so not chess) and moves, and when the game gets smaller every time someone makes a move, then every position can be considered either “winning” or “losing”, by growing the game up from smaller games. If you can only get to winning positions, then you’re at a losing position. If there’s an option to get to a losing position, then you’re at a winning position. A consequence of this way of thinking of things is that a “game” can be described by the options you have when given a chance to play (along with the rules that define the options).
We then discussed adding two games A and B, which just means you get to play from either A or B but not both. We decided that 2-pile Nim is already of the form A + A, where A is 1-pile Nim. And furthermore, 1-pile Nim is pretty dumb – the winning strategy is always to just take away all the stones. But in spite of this, 5 stones is not the same as 6 stones for 1-pile Nim, since you can get to 5 stones from 6 but not vice versa.
Then I defined A ~ B if for all other (impartial) games H, A + H always has the same winner as B + H. It’s easy to see ~ is an equivalence relation, and that G + G is always winning (again, by mimicking your opponent’s moves). It’s also pretty easy to see that if A is winning, then A + G ~ G for all G.
But it’s a bad definition of ~ in that it seems to take an infinite amount of work to decide if A ~ B, since you’d have to check something for all possible H. We decided to improve this by proving that G ~ G’ if and only if G + G’ is winning. It is pretty easy to do this.
Then it was time for action, namely to prove the Sprague-Grundy Theorem which states that:
Every impartial game G has G ~ [N] for some N, where [N] denotes 1-pile Nim with N stones.
We prove this by showing recursively on the size of the game that N above (also called the “Nimber” of the position) is just the “mex” function, which is the minimum excluded non-negative integer. In other words, we designate the winning position as having N = 0, and then we grow the game up from there. If a given position can get to a “0” position, then its Nimber is at least 0 – in fact it’s the minimum number that it can’t reach in one move.
In particular, if you are at a position with Nim number non-zero, you can get to a zero position (i.e. a winning position), as well as any smaller Nim position, and if you are at a position with Nim number zero, you can only get to non-zero positions. This is similar to the losing-winning dichotomy except slightly more nuanced.
We then drew a Nimber addition table, which is the same as the chessboard problem with a rook. We used this to reduce 3-pile Nim to 2-pile Nim and worked out a winning strategy for the 3-pile Nim game (2, 5, 3).
Next we drew a Nimber table for the queen on a chessboard problem. We decided we knew how to play that game plus a 3-pile Nim game.
I was running out of time by this time but I ended with showing them a fast way to find the Nimber of the sum of a bunch of games whose Nimbers you already know, namely the bitwise XOR function. I didn’t have time to prove it (it’s not hard to see with induction on the number of games you’re adding up) but it’s easy to see this recovers our “mimicking” strategy with two games.
HCSSiM Workshop day 3
A continuation of this, where I take notes on my workshop at HCSSiM.
Equivalence Relations and Partial Orderings
After going over many proofs of the geometry problem from last night’s problem set, I corrected the mistake in the “antisymmetric” property and we went through plenty of examples of equivalence relations and partial orderings. We ended with linear orderings, the real numbers, and the less than or equal relation.
Adding modulo n
Next we went back to the idea of maps 




![[n] = \{1, 2, 3, \dots, n\}](https://s0.wp.com/latex.php?latex=%5Bn%5D+%3D+%5C%7B1%2C+2%2C+3%2C+%5Cdots%2C+n%5C%7D&bg=ffffff&fg=555555&s=0&c=20201002)
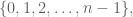
![[n]](https://s0.wp.com/latex.php?latex=%5Bn%5D&bg=ffffff&fg=555555&s=0&c=20201002)
Pigs-in-hole Principle
We introduced the pigeonhole principle (but since our camp mascot is a yellow, pig, we call it pigs-in-hole). We actually defined the slightly more general idea that, if you have 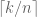
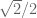
Greatest Common Divisor
We asked the kids what the greatest common divisor of 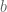

Eventually we thought of a trick to reduce the problem, namely the division algorithm. Actually Edwin thought of the trick, and it eventually became the Edwinian Algorithm (not like it’s usually called, namely the Euclidean Algorithm). Edwin observed that 

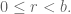
Once we had the Edwinian Algorithm, we realized we could go backwards and express 


So it turns out I’m not going to be able to make the homeworks public, but we had an awesome problem set with lots of pigeon hole problems and Edwinian Algorithm problems. We asked them to decide which approach to calculating 
HCSSiM Workshop day 2
A continuation of this, where I take notes on my workshop at HCSSiM.
The watermelon cutting problem revisited
We prove that the maximum number of pieces of watermelon you can cut with 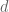

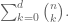
First we proved it with a combinatorial argument, then with induction. I decided the first one is better because you figure out the answer as you go, whereas the induction route requires that you already know the formula. They both require you to use the recursion relation we talked about yesterday, and the first one involved writing a 2-d chart and showing how to unpack the value of 
All pigs are yellow
Next we proved, using induction, that all pigs are the same color, and then we exhibited a yellow pig so a corollary was that all pigs are yellow. The base case is that a single pig is the same color as itself, and then assuming we have n pigs of the same color, we get to the statement that n+1 pigs are all the same color by first putting one pig in the barn, and then some other pig in the barn, and the leftover pigs are the same color as each of those so they’re all the same color.
This argument, of course, doesn’t work when you’re moving from “1 pig” to “2 pigs” and exhibits how careful you have to be with working through enough base cases so that your inductive step actually applies.
Strong Induction
We then went to using the Principle of Strong Induction (after showing that there’s no Principle of Induction over the real numbers). We proved that all numbers can be written as the sum of powers of 2, that the Fibonacci numbers grow exponentially, that every positive integer at least 2 is divisible by a prime, and that every planar polygon can be diagonalized using strong induction.
Notation
Incidentally, instead of “Strong Induction” the students voted to call it “Thor Induction”, and instead of the standard end-of-proof symbol, which is a box with an “x” inside, we voted to use the symbol “(see next page)”. They had lots of fun with that one. As a corollary, they decided that if they wanted someone to actually see the next page, they’d use the “Q.E.D.” symbol.
Cross product of Sets
Finally, we talked about the notation 

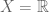
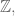

HCSSiM workshop day 1
So I’ve decided to try to explain what we’re doing in class here at mathcamp. This is both for your benefit and mine, since this way I won’t have to find my notes next time I do this.
Notetakers
We started the math, after intros, by assigning note-takers. In one row we wrote down the students’ names (14 of them), and in the other we wrote down the numbers 1 through 14. We drew lines from names down to numbers. These were the assigments for the days they’d take notes.
But to make it more interesting, we added pipes between different vertical lines. The pipes can be curly (my favorite ones were loopedy-loop) but have to start at one vertical line and end at another at “T” crosses.
Then the algorithm to get from a name to a number was this: start at the name, go down the vertical line til you hit a “T”, follow the “T” pipe til you hit another vertical line, and then go down.
This ends up matching people with numbers in a one-to-one fashion, but why? We promised to prove this by the end of the workshop.
Map of Math
We next had the kids talk about what “math” is. We had them throw up terms and we drew a collage on the board with everything they said. We circled the topics and connected them with lines if we could make the case they were related fields. We drew lines from the terms to the topics that used that a lot – like the symbol 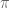
Cutting Watermelons
Next, we asked the kids how many pieces you can cut a watermelon into with 17 cuts. Imagine the watermelon plays nice and stays the shape of a watermelon as you continue cuts, and you can’t rearrange the watermelon’s pieces either.
If you do a few cuts it quickly gets hard to imagine.
So go down to a 2-dimensional watermelon, which could be called a pizza or a flattermelon. We called it a flattermelon. In this case you’re trying to see how many pieces you can achieve with 17 cuts. But also you may notice that a single slice of a 3-d watermelon looks, to the knife’s edge, like you are spanning a flattermelon.
Similarly, you may notice that a cut of the flattermelon looks like a 1-dimensional watermelon, otherwise known as a flatterermelon. And there the problem is easy: if you have a one dimensional watermelon, i.e. a line, then n cuts gives you maximum n+1 pieces. But going back to a pizza a.k.a. flattermelon, any cut looks from the point of view of the knife like a 1-d watermelon, which is to say it is cutting n+1 regions into half assuming the lines are in general position. So we get a recursion. If we denote by 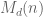

Since we know 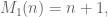
Notation
Next, I went on at length about the utility and frustration of notation. Namely, notation is only useful if everyone agrees on what it means. I like standard notation because it’s more, well, useful, but Hampshire is a place where kids absolutely adore making up their own notation. As long as we are consistent it’s ok with me, and I like the fact that they own it. So instead of the standard notation for “n choose k” we are using a pacman symbol with n inside the pacman and k being eaten by the pacman. We call it “n chews k”.
Combinatorial Argument
We talked about putting balls in baskets, and defined that pacman figure to be the number of ways we can do it. Then we proved the pascal’s triangle recursion relation using the argument where you isolate one basket and talk about the two cases, one where there’s a ball inside it and the other when there’s not. Then we identified Pascal’s triangle as being equivalent to this concept of counting. I described this as an example of a combinatorial argument, which I like because it doesn’t involve formulas and I’m lazy.
Induction
Finally, I introduced Mathematical Induction and did the standard first proof, namely to show the sum of the first n positive integers is
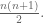
How much of data science is busy work?
I’m at math camp, about to start the first day (4 hours of teaching a day, 3 hours of problem session) with my three junior staff (last year I only had one!). I expect I’ll be blogging quite a bit in the next few days about math camp stuff but today I wanted to respond to this blog post, entitled “The Fallacy of the Data Scientist Shortage”. I found this on Data Science Central which I had never known about but looks to be a good resource.
The author, Neil Radan, makes the point that, although we seem to have a shortage of data scientists, mostly what they do can be done by non-specialists. Just as you waste your time during a plane trip on things like security, waiting to board, and taxiing, the average data scientist spends most of her time cleaning data and moving it around.
If I understand this post correctly, they are saying that, because data scientists don’t spend that much time doing creative stuff, they can be replaced by someone who is good with data.
Hmm… let’s first go back to the idea that data scientists spend most of their time cleaning and moving data. This is true, but what do we conclude from it? It’s something like saying concert cellists spend most of their time practicing scales and rosining their bows, and don’t do all that much actual performing. Or, you could compare it to math professors who spend most of their time meeting (or avoiding) students and not much time proving new theorems.
My point is that this fact of time management is maybe a universal rule. Or even better, it may be a universal rule for creative endeavors. If you’re a truck driver then you can fairly said you worked the whole time you drove across the country, at a pretty consistent pace. But if you’re doing something that requires thought and puzzling then the nature of things is that it isn’t an 8-hour-a-day activity.
It’s more like, as a data scientist, you work hard to see the data in a certain way, which takes lots of time depending on how much data you have, then you make a decision based on what you’ve seen, then you set up the next test.
And I don’t think this can be done by someone who is strictly good at moving around data but isn’t trained as a modeler or statistician or the like. Because the hard part isn’t the data munging, it’s the part where you decide what test to perform that will give you the maximum information, and also the part where you look at the results and decipher them – decide whether they are what you expected, and if not, what could explain what you’re seeing.
I do think that data scientists can and should be paired with people who are experts at data moving and cleaning, because then the whole process is more efficient. Maybe data scientists can be brought in as 2-hour-per-day consultants or something, and the rest of the time there can be some engineers working on their tests. That might work.
Mixing colors: pigment vs. light
Today we will address another topic in a list of “things I’m kind of ashamed I don’t understand considering I am a professional scientist of sorts” (please make suggestions!).
Why is it that when you mix light blue (cyan) and yellow paint you get green paint, but when you mix cyan and yellow light you get white light?
Unlike with yesterday’s analemma post, where I couldn’t find a satisfactory write-up on another blog, today’s blog is actually pretty nicely explained and beautifully illustrated here. I will crib their illustrations and summarize the explanations but it’s really out-and-out plagiarism for the moment.
First, you’ve got the so-called “hue wheel” (which sounds more sophisticated than “color wheel”, don’t you agree?):

This is illustrating the following. There are three basic pigments: yellow, cyan and magenta. There are three basic colors of light, namely green, blue, and red. And if you mix the fundamental pigments pair-wise (as in, you get paints and mix them) you get the fundamental colors of lights.
And vice versa as well, although this time you’re mixing as in splicing them together but keeping them separate, like we use pixels on our screen. This means, specifically, that you can combine green and red to get yellow. That’s majorly unbelievable until you see this miraculous picture, also from this webpage:

See how that works? I just can’t get over this picture. The little piece of yellow on the left is just stripes of green and red. Really incredible. The purple I get because it’s blue and red just like it’s supposed to be.
So, why?
The first thing to understand is that this isn’t just a relationship between us and the object we are looking at. It is instead a three-part relationship between us (or more specifically, our eyes), the object, and the sun (or some other source of light, but it’s more traditional in explanations like this to use fundamental, macho objects of nature like the sun).
Nothing can happen without a source of light. Which begs the question, what is light anyway? Again a picture stolen from here:

The prism separates the white light into various wavelengths, where red is at 700 nanometers and violet at 400 nanometers. More on the visible spectrum here. Note that the hidden difficulty here is why a prism does this, which is explained here.
So when an apple looks red to us, we have to imagine white light from the sun hitting that apple, and the key is that the skin of the apple is absorbing everything except the red light:
 That thing on top is the sun, and the thing on bottom is your eyeball. The point is the red part of the light is reflected off the apple skin into your eye. And even though white light from the sun is the whole spectrum, we are denoting it when just the fundamental three colors of light because other colors can be made from those. And this can be corroborated by looking at your computer screen with a magnifying glass, where you will see that the white background is actually made up of little pixels of green, red, and blue.
That thing on top is the sun, and the thing on bottom is your eyeball. The point is the red part of the light is reflected off the apple skin into your eye. And even though white light from the sun is the whole spectrum, we are denoting it when just the fundamental three colors of light because other colors can be made from those. And this can be corroborated by looking at your computer screen with a magnifying glass, where you will see that the white background is actually made up of little pixels of green, red, and blue.
By the way, we are again sidestepping the actual hard part here, namely why some surfaces such as apple skins reflect some colors like red. I have no idea. But I don’t feel as guilty about not understanding that.
Finally, back to the first question, of why cyan and yellow paint make green whereas cyan and yellow light make white. Turns out the light one is actually easier, since our second picture above shows us that yellow light is actually a mix of red and green, and when you add cyan, you now have all three fundamental colors of light, which gives us white light.
If you have cyan paint, then it is reflecting blue and green light, so absorbing red light. If you have yellow paint then that’s a material which is reflecting both green and red, so absorbing blue. For some weird reason (a third moment of stuffing things under the rug), the mixture of the paint is additive on absorbing things, so absorbs both blue and red, leaving only green reflected.
In the end we get a kind of mini De Morgan’s Law for color.
I’ve convinced myself that, modulo the following three questions I understand this explanation:
- How does a prism separate white light into the colors really?
- How do different surfaces decide which lights to reflect and which to absorb? And a related question from Aaron, why do colors fade when they’ve been in the sun?
- Why is “absorbing light” an additive procedure when you mix materials? I feel like if I understood 2 then I’d get 3 for free.



