Archive
Occupy in the Financial Times
Lisa Pollack just wrote about Occupy yesterday in this article entitled “Occupy is Increasingly Well-informed”.
It was mostly about Alternative Banking‘s sister working group in London, Occupy Economics, and their recent event this past Monday at which Andy Haldane, Executive Director of Financial Stability at the Bank of England spoke and at which Lisa Pollack chaired the discussion. For more on that event see Lisa’s article here.
Lisa interviewed me yesterday for the article, and asked me (over the screaming of my three sons who haven’t had school in what feels like months), if I had a genie and one try, what would I wish for with respect to Occupy and Alt Banking. I decided that my wish would be that there’s no reason to meet anymore, that the regulators, politicians, economists, lobbyists and bank CEO’s, so the stewards or our financial system and the economy, all got together and decided to do their jobs (and the lobbyists just found other jobs).
Does that count as one wish?
I’m digging these events where Occupiers get to talk one-on-one with those rare regulators and insiders who know how the system works, understand that the system is rigged, and are courageous enough to be honest about it. Alternative Banking met with Sheila Bar a couple of months ago and we’ve got more very exciting meetings coming up as well.
The definitive visualization for Hurricane Sandy, if you’re a parent of small children
 Two small quibbles: it should be centered a much larger area, and “wine” should be replaced by “vodka”.
Two small quibbles: it should be centered a much larger area, and “wine” should be replaced by “vodka”.
An AMS panel to examine public math models?
On Saturday I gave a talk at the AGNES conference to a room full of algebraic geometers. After introducing myself and putting some context around my talk, I focused on a few models:
- VaR,
- VAM,
- Credit scoring,
- E-scores (online version of credit scores), and
- The h-score model (I threw this in for the math people and because it’s an egregious example of a gameable model).
I wanted to formalize the important and salient properties of a model, and I came up with this list:
- Name – note the name often gives off a whiff of political manipulation by itself
- Underlying model – regression? decision tree?
- Underlying assumptions – normal distribution of market returns?
- Input/output – dirty data?
- Purported/political goal – how is it actually used vs. how its advocates claim they’ll use it?
- Evaluation method – every model should come with one. Not every model does. A red flag.
- Gaming potential – how does being modeled cause people to act differently?
- Reach – how universal and impactful is the model and its gaming?
In the case of VAM, it doesn’t have an evaluation method. There’s been no way for teachers to know if the model that they get scored on every year is doing a good job, even as it’s become more and more important in tenure decisions (the Chicago strike was largely related to this issue, as I posted here).
Here was my plea to the mathematical audience: this is being done in the name of mathematics. The authority that math is given by our culture, which is enormous and possibly not deserved, is being manipulated by people with vested interests.
So when the objects of modeling, the people and the teachers who get these scores, ask how those scores were derived, they’re often told “it’s math and you wouldn’t understand it.”
That’s outrageous, and mathematicians shouldn’t stand for it. We have to get more involved, as a community, with how mathematics is wielded on the population.
On the other hand, I wouldn’t want mathematicians as a group to get co-opted by these special interest groups either and become shills for the industry. We don’t want to become economists, paid by this campaign or that to write papers in favor of their political goals.
To this end, someone in the audience suggested the AMS might want to publish a book of ethics for mathematicians akin to the ethical guidelines that are published for the society of pyschologists and lawyers. His idea is that it would be case-study based, which seems pretty standard. I want to give this some more thought.
We want to make ourselves available to understand high impact, public facing models to ensure they are sound mathematically, have reasonable and transparent evaluation methods, and are very high quality in terms of proven accuracy and understandability if they are used on people in high stakes situations like tenure.
One suggestion someone in the audience came up with is to have a mathematician “mechanical turk” service where people could send questions to a group of faceless mathematicians. Although I think it’s an intriguing idea, I’m not sure it would work here. The point is to investigate so-called math models that people would rather no mathematician laid their eyes on, whereas mechanical turks only answer questions someone else comes up with.
In other words, there’s a reason nobody has asked the opinion of the mathematical community on VAM. They are using the authority of mathematics without permission.
Instead, I think the math community should form something like a panel, maybe housed inside the American Mathematical Society (AMS), that trolls for models with the following characteristics:
- high impact – people care about these scores for whatever reason
- large reach – city-wide or national
- claiming to be mathematical – so the opinion of the mathematical community matters, or should,
After finding such a model, the panel should publish a thoughtful, third-party analysis of its underlying mathematical soundness. Even just one per year would have a meaningful effect if the models were chosen well.
As I said to someone in the audience (which was amazingly receptive and open to my message), it really wouldn’t take very long for a mathematician to understand these models well enough to have an opinion on them, especially if you compare it to how long it would take a policy maker to understand the math. Maybe a week, with the guidance of someone who is an expert in modeling.
So in other words, being a member of such a “public math models” panel could be seen as a community service job akin to being an editor for a journal: real work but not something that takes over your life.
Now’s the time to do this, considering the explosion of models on everything in sight, and I believe mathematicians are the right people to take it on, considering they know how to admit they’re wrong.
Tell me what you think.
Columbia Data Science course, week 8: Data visualization, broadening the definition of data science, Square, fraud detection
This week in Rachel Schutt’s Columbia Data Science course we had two excellent guest speakers.
The first speaker of the night was Mark Hansen, who recently came from UCLA via the New York Times to Columbia with a joint appointment in journalism and statistics. He is a renowned data visualization expert and also an energetic and generous speaker. We were lucky to have him on a night where he’d been drinking an XXL latte from Starbucks to highlight his natural effervescence.
Mark started by telling us a bit about Gabriel Tarde (1843-1904).

Tarde was a sociologist who believed that the social sciences had the capacity to produce vastly more data than the physical sciences. His reasoning was as follows.
The physical sciences observe from a distance: they typically model or incorporate models which talk about an aggregate in some way – for example, biology talks about the aggregate of our cells. What Tarde pointed out was that this is a deficiency, basically a lack of information. We should instead be tracking every atom.
This is where Tarde points out that in the social realm we can do this, where cells are replaced by people. We can collect a huge amount of information about those individuals.
But wait, are we not missing the forest for the trees when we do this? Bruno Latour weighs in on his take of Tarde as follows:
“But the ‘whole’ is now nothing more than a provisional visualization which can be modified and reversed at will, by moving back to the individual components, and then looking for yet other tools to regroup the same elements into alternative assemblages.”
In 1903, Tarde even foresees the emergence of Facebook, although he refers to a “daily press”:
“At some point, every social event is going to be reported or observed.”
Mark then laid down the theme of his lecture using a 2009 quote of Bruno Latour:
“Change the instruments and you will change the entire social theory that goes with them.”
Kind of like that famous physics cat, I guess, Mark (and Tarde) want us to newly consider
- the way the structure of society changes as we observe it, and
- ways of thinking about the relationship of the individual to the aggregate.
Mark’s Thought Experiment:
As data become more personal, as we collect more data about “individuals”, what new methods or tools do we need to express the fundamental relationship between ourselves and our communities, our communities and our country, our country and the world? Could we ever be satisfied with poll results or presidential approval ratings when we can see the complete trajectory of public opinions, individuated and interacting?
What is data science?
Mark threw up this quote from our own John Tukey:
“The best thing about being a statistician is that you get to play in everyone’s backyard”
But let’s think about that again – is it so great? Is it even reasonable? In some sense, to think of us as playing in other people’s yards, with their toys, is to draw a line between “traditional data fields” and “everything else”.
It’s maybe even implying that all our magic comes from the traditional data fields (math, stats, CS), and we’re some kind of super humans because we’re uber-nerds. That’s a convenient way to look at it from the perspective of our egos, of course, but it’s perhaps too narrow and arrogant.
And it begs the question, what is “traditional” and what is “everything else” anyway?
Mark claims that everything else should include:
- social science,
- physical science,
- geography,
- architecture,
- education,
- information science,
- architecture,
- digital humanities,
- journalism,
- design,
- media art
There’s more to our practice than being technologists, and we need to realize that technology itself emerges out of the natural needs of a discipline. For example, GIS emerges from geographers and text data mining emerges from digital humanities.
In other words, it’s not math people ruling the world, it’s domain practices being informed by techniques growing organically from those fields. When data hits their practice, each practice is learning differently; their concerns are unique to that practice.
Responsible data science integrates those lessons, and it’s not a purely mathematical integration. It could be a way of describing events, for example. Specifically, it’s not necessarily a quantifiable thing.
Bottom-line: it’s possible that the language of data science has something to do with social science just as it has something to do with math.
Processing
Mark then told us a bit about his profile (“expansionist”) and about the language processing, in answer to a question about what is different when a designer takes up data or starts to code.
He explained it by way of another thought experiment: what is the use case for a language for artists? Students came up with a bunch of ideas:
- being able to specify shapes,
- faithful rendering of what visual thing you had in mind,
- being able to sketch,
- 3-d,
- animation,
- interactivity,
- Mark added publishing – artists must be able to share and publish their end results.
It’s java based, with a simple “publish” button, etc. The language is adapted to the practice of artists. He mentioned that teaching designers to code meant, for him, stepping back and talking about iteration, if statements, etc., of in other words stuff that seemed obvious to him but is not obvious to someone who is an artist. He needed to unpack his assumptions, which is what’s fun about teaching to the uninitiated.
He next moved on to close versus distant reading of texts. He mentioned Franco Moretti from Stanford. This is for Franco:

Franco thinks about “distant reading”, which means trying to get a sense of what someone’s talking about without reading line by line. This leads to PCA-esque thinking, a kind of dimension reduction of novels.
In other words, another cool example of how data science should integrate the way the experts in various fields figure it out. We don’t just go into their backyards and play, maybe instead we go in and watch themplay and formalize and inform their process with our bells and whistles. In this way they can teach us new games, games that actually expand our fundamental conceptions of data and the approaches we need to analyze them.
Mark’s favorite viz projects
1) Nuage Vert, Helen Evans & Heiko Hansen: a projection onto a power plant’s steam cloud. The size of the green projection corresponds to the amount of energy the city is using. Helsinki and Paris.

2) One Tree, Natalie Jeremijenko: The artist cloned trees and planted the genetically identical seeds in several areas. Displays among other things the environmental conditions in each area where they are planted.

3) Dusty Relief, New Territories: here the building collects pollution around it, displayed as dust.

4) Project Reveal, New York Times R&D lab: this is a kind of magic mirror which wirelessly connects using facial recognition technology and gives you information about yourself. As you stand at the mirror in the morning you get that “come-to-jesus moment” according to Mark.

5) Million Dollar Blocks, Spatial Information Design Lab (SIDL): So there are crime stats for google maps, which are typically painful to look at. The SIDL is headed by Laura Kurgan, and in this piece she flipped the statistics. She went into the prison population data, and for every incarcerated person, she looked at their home address, measuring per home how much money the state was spending to keep the people who lived there in prison. She discovered that some blocks were spending $1,000,000 to keep people in prison.

Moral of the above: just because you can put something on the map, doesn’t mean you should. Doesn’t mean there’s a new story. Sometimes you need to dig deeper and flip it over to get a new story.
New York Times lobby: Moveable Type
Mark walked us through a project he did with Ben Rubin for the NYTimes on commission (and he later went to the NYTimes on sabbatical). It’s in the lobby of their midtown headquarters at 8th and 42nd.

It consists of 560 text displays, two walls with 280 on each, and the idea is they cycle through various “scenes” which each have a theme and an underlying data science model.
For example, in one there are waves upon waves of digital ticker-tape like scenes which leave behind clusters of text, and where each cluster represents a different story from the paper. The text for a given story highlights phrases which make a given story different from others in some information-theory sense.
In another scene the numbers coming out of stories are highlighted, so you might see on a given box “18 gorillas”. In a third scene, crossword puzzles play themselves with sounds of pencil and paper.
The display boxes themselves are retro, with embedded linux processors running python, and a sound card on each box, which makes clicky sounds or wavy sounds or typing sounds depending on what scene is playing.

The data taken in is text from NY Times articles, blogs, and search engine activity. Every sentence is parsed using Stanford NLP techniques, which diagrams sentences.
Altogether there are about 15 “scenes” so far, and it’s code so one can keep adding to it. Here’s an interview with them about the exhibit:
Project Cascade: Lives on a Screen
Mark next told us about Cascade, which was joint work with Jer Thorp data artist-in-residence at the New York Times. Cascade came about from thinking about how people share New York Times links on Twitter. It was in partnerships with bitly.
The idea was to collect enough data so that we could see someone browse, encode the link in bitly, tweet that encoded link, see other people click on that tweet and see bitly decode the link, and then see those new people browse the New York Times. It’s a visualization of that entire process, much as Tarde suggested we should do.
There were of course data decisions to be made: a loose matching of tweets and clicks through time, for example. If 17 different tweets have the same url they don’t know which one you clicked on, so they guess (the guess actually seemed to involve probabilistic matching on time stamps so it’s an educated guess). They used the Twitter map of who follows who. If someone you follow tweets about something before you do then it counts as a retweet. It covers any nytimes.com link.

Here’s a NYTimes R&D video about Project Cascade:
Note: this was done 2 years ago, and Twitter has gotten a lot bigger since then.
Cronkite Plaza
Next Mark told us about something he was working on which just opened 1.5 months ago with Jer and Ben. It’s also news related, but this is projecting on the outside of a building rather than in the lobby; specifically, the communications building at UT Austin, in Cronkite Plaza.

The majority of the projected text is sourced from Cronkite’s broadcasts, but also have local closed-captioned news sources. One scene of this project has extracted the questions asked during local news – things like “how did she react?” or “What type of dog would you get?”. The project uses 6 projectors.
Goals of these exhibits
They are meant to be graceful and artistic, but should also teach something. At the same time we don’t want to be overly didactic. The aim is to live in between art and information. It’s a funny place: increasingly we see a flattening effect when tools are digitized and made available, so that statisticians can code like a designer (we can make things that look like design) and similarly designers can make something that looks like data.
What data can we get? Be a good investigator: a small polite voice which asks for data usually gets it.
eBay transactions and books
Again working jointly with Jer Thorp, Mark investigated a day’s worth of eBay’s transactions that went through Paypal and, for whatever reason, two years of book sales. How do you visualize this? Take a look at the yummy underlying data:

Here’s how they did it (it’s ingenious). They started with the text of Death of a Salesman by Arthur Miller. They used a mechanical turk mechanism to locate objects in the text that you can buy on eBay.
When an object is found it moves it to a special bin, so “chair” or “flute” or “table.” When it has a few collected buy-able objects, it then takes the objects and sees where they are all for sale on the day’s worth of transactions, and looks at details on outliers and such. After examining the sales, the code will find a zipcode in some quiet place like Montana.
Then it flips over to the book sales data, looks at all the books bought or sold in that zip code, picks a book (which is also on Project Gutenberg), and begins to read that book and collect “buyable” objects from that. And it keeps going. Here’s a video:
Public Theater Shakespeare Machine
The last thing Mark showed us is is joint work with Rubin and Thorp, installed in the lobby of the Public Theater. The piece itself is an oval structure with 37 bladed LED displays, set above the bar.
There’s one blade for each of Shakespeare’s plays. Longer plays are in the long end of the oval, Hamlet you see when you come in.

The data input is the text of each play. Each scene does something different – for example, it might collect noun phrases that have something to do with body from each play, so the “Hamlet” blade will only show a body phrase from Hamlet. In another scene, various kinds of combinations or linguistic constructs are mined:
- “high and might” “good and gracious” etc.
- “devilish-holy” “heart-sore” “ill-favored” “sea-tossed” “light-winged” “crest-fallen” “hard-favoured” etc.
Note here that the digital humanities, through the MONK Project, offered intense xml descriptions of the plays. Every single word is given hooha and there’s something on the order of 150 different parts of speech.
As Mark said, it’s Shakespeare so it stays awesome no matter what you do, but here we see we’re successively considering words as symbols, or as thematic, or as parts of speech. It’s all data.
Ian Wong from Square
Next Ian Wong, an “Inference Scientist” at Square who dropped out of an Electrical Engineering Ph.D. program at Stanford talked to us about Data Science in Risk.
He conveniently started with his takeaways:
- Machine learning is not equivalent to R scripts. ML is founded in math, expressed in code, and assembled into software. You need to be an engineer and learn to write readable, reusable code: your code will be reread more times by other people than by you, so learn to write it so that others can read it.
- Data visualization is not equivalent to producing a nice plot. Rather, think about visualizations as pervasive and part of the environment of a good company.
- Together, they augment human intelligence. We have limited cognitive abilities as human beings, but if we can learn from data, we create an exoskeleton, an augmented understanding of our world through data.
Square
Square was founded in 2009. There were 40 employees in 2010, and there are 400 now. The mission of the company is to make commerce easy. Right now transactions are needlessly complicated. It takes too much to understand and to do, even to know where to start for a vendor. For that matter, it’s too complicated for buyers as well. The question we set out to ask is, how do we make transactions simple and easy?
We send out a white piece of plastic, which we refer to as the iconic square. It’s something you can plug into your phone or iPad. It’s simple and familiar, and it makes it easy to use and to sell.
It’s even possible to buy things hands-free using the square. A buyer can open a tab on their phone so that they can pay by saying their name.. Then the merchant taps your name on their screen. This makes sense if you are a frequent visitor to a certain store like a coffee shop.
Our goal is to make it easy for sellers to sign up for Square and accept payments. Of course, it’s also possible that somebody may sign up and try to abuse the service. We are therefore very careful at Square to avoid losing money on sellers with fraudulent intentions or bad business models.
The Risk Challenge
At Square we need to balance the following goals:
- to provide a frictionless and delightful experience for buyers and sellers,
- to fuel rapid growth, and in particular to avoid inhibiting growth through asking for too much information of new sellers, which adds needless barriers to joining, and
- to maintain low financial loss.
Today we’ll just focus on the third goal through detection of suspicious activity. We do this by investing in machine learning and viz. We’ll first discuss the machine learning aspects.
Part 1: Detecting suspicious activity using machine learning
First of all, what’s suspicious? Examples from the class included:
- lots of micro transactions occurring,
- signs of money laundering,
- high frequency or inconsistent frequency of transactions.
Example: Say Rachel has a food truck, but then for whatever reason starts to have $1000 transactions (mathbabe can’t help but insert that Rachel might be a food douche which would explain everything).
On the one hand, if we let money go through, Square is liable in the case it was unauthorized. Technically the fraudster, so in this case Rachel would be liable, but our experience is that usually fraudsters are insolvent, so it ends up on Square.
On the other hand, the customer service is bad if we stop payment on what turn out to be real payments. After all, what if she’s innocent and we deny the charges? She will probably hate us, may even sully our reputation, and in any case our trust is lost with her after that.
This example crystallizes the important challenges we face: false positives erode customer trust, false negatives make us lose money.
And since Square processes millions of dollars worth of sales per day, we need to do this systematically and automatically. We need to assess the risk level of every event and entity in our system.
So what do we do?
First of all, we take a look at our data. We’ve got three types:
- payment data, where the fields are transaction_id, seller_id, buyer_id, amount, success (0 or 1), timestamp,
- seller data, where the fields are seller_id, sign_up_date, business_name, business_type, business_location,
- settlement data, where the fields are settlement_id, state, timestamp.
Important fact: we settle to our customers the next day so we don’t have to make our decision within microseconds. We have a few hours. We’d like to do it quickly of course, but in certain cases we have time for a phone call to check on things.
So here’s the process: given a bunch (as in hundreds or thousands) of payment events, we throw each through the risk engine, and then send some iffy looking ones on to a “manual review”. An ops team will then review the cases on an individual basis. Specifically, anything that looks rejectable gets sent to ops, which make phone calls to double check unless it’s super outrageously obviously fraud.
Also, to be clear, there are actually two kinds of fraud to worry about, seller-side fraud and buyer-side fraud. For the purpose of this discussion, we’ll focus on the former.
So now it’s a question of how we set up the risk engine. Note that we can think of the risk engine as putting things in bins, and those bins each have labels. So we can call this a labeling problem.
But that kind of makes it sound like unsupervised learning, like a clustering problem, and although it shares some properties with that, it’s certainly not that simple – we don’t reject a payment and then merely stand pat with that label, because as we discussed we send it on to an ops team to assess it independently. So in actuality we have a pretty complicated set of labels, including for example:
- initially rejected but ok,
- initially rejected and bad,
- initially accepted but on further consideration might have been bad,
- initially accepted and things seem ok,
- initially accepted and later found to be bad, …
So in other words we have ourselves a semi-supervised learning problem, straddling the worlds of supervised and unsupervised learning. We first check our old labels, and modify them, and then use them to help cluster new events using salient properties and attributes common to historical events whose labels we trust. We are constantly modifying our labels even in retrospect for this reason.
We estimate performance using precision and recall. Note there are very few positive examples so accuracy is not a good metric of success, since the “everything looks good” model is dumb but has good accuracy.
Labels are what Ian considered to be the “neglected half of the data” (recall T = {(x_i, y_i)}). In undergrad statistics education and in data mining competitions, the availability of labels is often taken for granted. In reality, labels are tough to define and capture. Labels are really important. It’s not just objective function, it is the objective.
As is probably familiar to people, we have a problem with sparsity of features. This is exacerbated by class imbalance (i.e., there are few positive samples). We also don’t know the same information for all of our sellers, especially when we have new sellers. But if we are too conservative we start off on the wrong foot with new customers.
Also, we might have a data point, say zipcode, for every seller, but we don’t have enough information in knowing the zipcode alone because so few sellers share zipcodes. In this case we want to do some clever binning of the zipcodes, which is something like sub model of our model.
Finally, and this is typical for predictive algorithms, we need to tweak our algorithm to optimize it- we need to consider whether features interact linearly or non-linearly, and to account for class imbalance.. We also have to be aware of adversarial behavior. An example of adversarial behavior in e-commerce is new buyer fraud, where a given person sets up 10 new accounts with slightly different spellings of their name and address.
Since models degrade over time, as people learn to game them, we need to continually retrain models. The keys to building performance models are as follows:
- it’s not a black box. You can’t build a good model by assuming that the algorithm will take care of everything. For instance, I need to know why I am misclassifying certain people, so I’ll need to roll up my sleeves and dig into my model.
- We need to perform rapid iterations of testing, with experiments like you’d do in a science lab. If you’re not sure whether to try A or B, then try both.
- When you hear someone say, “So which models or packages do you use?” then you’ve got someone who doesn’t get it. Models and/or packages are not magic potion.
Mathbabe cannot resist paraphrasing Ian here as saying “It’s not about the package. it’s about what you do with it.” But what Ian really thinks it’s about, at least for code, is:
- readability
- reusability
- correctness
- structure
- hygiene
So, if you’re coding a random forest algorithm and you’ve hardcoded the number of trees: you’re an idiot. put a friggin parameter there so people can reuse it. Make it tweakable. And write the tests for pity’s sake; clean code and clarity of thought go together.
At Square we try to maintain reusability and readability — we structure our code in different folders with distinct, reusable components that provide semantics around the different parts of building a machine learning model: model, signal, error, experiment.
We only write scripts in the experiments folder where we either tie together components from model, signal and error or we conduct exploratory data analysis. It’s more than just a script, it’s a way of thinking, a philosophy of approach.
What does such a discipline give you? Every time you run an experiment your should incrementally increase your knowledge. This discipline helps you make sure you don’t do the same work again. Without it you can’t even figure out the things you or someone else has already attempted.
For more on what every project directory should contain, see Project Template, written by John Myles White.
We had a brief discussion of how reading other people’s code is a huge problem, especially when we don’t even know what clean code looks like. Ian stayed firm on his claim that “if you don’t write production code then you’re not productive.”
In this light, Ian suggests exploring and actively reading Github’s repository of R code. He says to try writing your own R package after reading this. Also, he says that developing an aesthetic sense for code is analogous to acquiring the taste for beautiful proofs; it’s done through rigorous practice and feedback from peers and mentors. The problem is, he says, that statistics instructors in schools usually do not give feedback on code quality, nor are they qualified to.
For extra credit, Ian suggests the reader contrasts the implementations of the caret package (poor code) with scikit-learn (clean code).
Important things Ian skipped
- how is a model “productionized”?
- how are features computed in real-time to support these models?
- how do we make sure “what we see is what we get”, meaning the features we build in a training environment will be the ones we see in real-time. Turns out this is a pretty big problem.
- how do you test a risk engine?
Next Ian talked to us about how Square uses visualization.
Data Viz at Square
Ian talked to us about a bunch of different ways the Inference Team at Square use visualizations to monitor the transactions going on at any given time. He mentioned that these monitors aren’t necessarily trying to predict fraud per se but rather provides a way of keeping an eye on things to look for trends and patterns over time and serves as the kind of “data exoskeleton” that he mentioned at the beginning. People at Square believe in ambient analytics, which means passively ingesting data constantly so you develop a visceral feel for it.
After all, it is only by becoming very familiar with our data that we even know what kind of patterns are unusual or deserve their own model. To go further into the philosophy of this approach, he said two thing:
“What gets measured gets managed,” and “You can’t improve what you don’t measure.”
He described a workflow tool to review users, which shows features of the seller, including the history of sales and geographical information, reviews, contact info, and more. Think mission control.
In addition to the raw transactions, there are risk metrics that Ian keeps a close eye on. So for example he monitors the “clear rates” and “freeze rates” per day, as well as how many events needed to be reviewed. Using his fancy viz system he can get down to which analysts froze the most today and how long each account took to review, and what attributes indicate a long review process.
In general people at Square are big believers in visualizing business metrics (sign-ups, activations, active users, etc.) in dashboards; they think it leads to more accountability and better improvement of models as they degrade. They run a kind of constant EKG of their business through ambient analytics.
Ian ended with his data scientist profile. He thinks it should be on a logarithmic scale, since it doesn’t take very long to be okay at something (good enough to get by) but it takes lots of time to get from good to great. He believes that productivity should also be measured in log-scale, and his argument is that leading software contributors crank out packages at a much higher rate than other people.
Ian’s advice to aspiring data scientists
- play with real data
- build a good foundation in school
- get an internship
- be literate, not just in statistics
- stay curious
Ian’s thought experiment
Suppose you know about every single transaction in the world as it occurs. How would you use that data?
On my way to AGNES
I’m putting the finishing touches on my third talk of the week, which is called “How math is used outside academia” and is intended for a math audience at the AGNES conference.

I’m taking Amtrak up to Providence to deliver the talk at Brown this afternoon. After the talk there’s a break, another talk, and then we all go to the conference dinner and I get to hang with my math nerd peeps. I’m talking about you, Ben Bakker.

Since I’m going straight from a data conference to a math conference, I’ll just make a few sociological observations about the differences I expect to see.
- No name tags at AGNES. Everyone knows each other already from undergrad, grad school, or summer programs. Or all three. It’s a small world.
- Probably nobody standing in line to get anyone’s autograph at AGNES. To be fair, that likely only happens at Strata because along with the autograph you get a free O’Reilly book, and the autographer is the author. Still, I think we should figure out a way to add this to math conferences somehow, because it’s fun to feel like you’re among celebrities.
- No theme music at AGNES when I start my talk, unlike my keynote discussion with Julie Steele on Thursday at Strata. Which is too bad, because I was gonna request “Eye of the Tiger”.
For the nerds: what’s wrong with this picture?
h/t Dave:

(Update! Rachel Schutt blogged about this same sign on October 2nd! Great nerd minds think alike :))
Also from the subway:

As my 10-year-old son says, the green guys actually look more endangered since
- their heads are disconnected from their bodies, and
- they are balancing precariously on single rounded stub legs.
Strata: one down, one to go
Yesterday I gave a talk called “Finance vs. Machine Learning” at Strata. It was meant to be a smack-down, but for whatever reason I couldn’t engage people to personify the two disciplines and have a wrestling match on stage. For the record, I offered to be on either side. Either they were afraid to hurt a girl or they were afraid to lose to a girl, you decide.
Unfortunately I didn’t actually get to the main motivation for the genesis of this talk, namely the realization I had a while ago that when machine learners talk about “ridge regression” or “Tikhonov regularization” or even “L2 regularization” it comes down to the same thing that quants call a very simple bayesian prior that your coefficients shouldn’t be too large. I talked about this here.
What I did have time for: I talked about “causal modeling” in the finance-y sense (discussion of finance vs. statistician definition of causal here), exponential downweighting with a well-chosen decay, storytelling as part of feature selection, and always choosing to visualize everything, and always visualizing the evolution of a statistic rather than a snapshot statistic.
They videotaped me but I don’t see it on the strata website yet. I’ll update if that happens.
This morning, at 9:35, I’ll be in a keynote discussion with Julie Steele for 10 minutes entitled “You Can’t Learn That in School”, which will be live streamed. It’s about whether data science can and should be taught in academia.
For those of you wondering why I haven’t blogged the Columbia Data Science class like I usually do Thursday, these talks are why. I’ll get to it soon, I promise! Last night’s talks by Mark Hansen, data vizzer extraordinaire and Ian Wong, Inference Scientist from Square, were really awesome.
How to measure a tree
Yesterday I went to a DataKind datadive as part of the Strata big data conference. As you might remember, I was a data ambassador a few weeks ago when we looked at pruning data, and they decided to take another look at this with better and cleaner data yesterday.
One of the people I met there was Mark Headd, the data czar/king/sultan of Philadelphia (actually, he called himself something like the “data guy” but I couldn’t resist embellishing his title on the spot). He blogs at civic.io, which is a pretty sweet url.
Mark showed me a nice app called Philly Tree Map, which is an open-source app gives information like the location, species, size, and environmental impact of each tree in Philly; it also allows users to update information or add new trees, which is fun and makes it more interactive.

They’re also using it in San Diego, and I don’t see why they can’t use it in New York as well, since I believe Parks has the tree census data.
I always love it when people get really into something (as described in my coffee douche post here), so I wanted to share with you guys the absolute tree-douchiest video ever filmed, namely the hilarious cult classic “How to Measure a Tree“, available on the FAQ page of the Philly tree map:
We’re not just predicting the future, we’re causing the future
My friend Rachel Schutt, a statistician at Google who is teaching the Columbia Data Science course this semester that I’ve been blogging every Thursday morning, recently wrote a blog post about 10 important issues in data science, and one of them is the title of my post today.
This idea that our predictive models cause the future is part of the modeling feedback loop I blogged about here; it’s the idea that, once we’ve chosen a model, especially as it models human behavior (which includes the financial markets), then people immediately start gaming the model in one way or another, both weakening the effect that the model is predicting as well as distorting the system itself. This is important and often overlooked when people build models.
How do we get people to think about these things more carefully? I think it would help to have a checklist of properties of a model using best practices.
I got this idea recently as I’ve been writing a talk about how math is used outside academia (which you guys have helped me on). In it, I’m giving a bunch of examples of models with a few basic properties of well-designed models.
It was interesting just composing that checklist, and I’ll likely blog about this in the next few days, but needless to say one thing on the checklist was “evaluation method”.
Obvious point: if you have a model which has no well-defined evaluation model then you’re fucked. In fact, I’d argue, you don’t really even have a model until you’ve chosen and defended your evaluation method (I’m talking to you, value-added teacher modelers).
But what I now realize is that part of the evaluation method of the model should consist of an analysis of how the model can or will be gamed and how that gaming can or will distort the ambient system. It’s a meta-evaluation of the model, if you will.
Example: as soon as regulators agree to measure a firm’s risk with 95% VaR on a 0.97 decay factor, there’s all sorts of ways for companies to hide risk. That’s why the parameters (95, 0.97) cannot be fixed if we want a reasonable assessment of risk.
This is obvious to most people upon reflection, but it’s not systemically studied, because it’s not required as part of an evaluation method for VaR. Indeed a reasonable evaluation method for VaR is to ask whether the 95% loss is indeed breached only 5% of the time, but that clearly doesn’t tell the whole story.
One easy way to get around this is to require a whole range of parameters for % VaR as well as a whole range of decay factors. It’s not that much more work and it is much harder to game. In other words, it’s a robustness measurement for the model.
Are healthcare costs really skyrocketing?
Yesterday we had a one-year anniversary meeting of the Alternative Banking group of Occupy Wall Street. Along with it we had excellent discussions of social security, Medicare, and ISDA, including details descriptions of how ISDA changes the rules to suit themselves and the CDS market, acting as a kind of independent system of law, which in particular means it’s not accountable to other rules of law.
Going back to our discussion on Medicare, I have a few comments and a questions for my dear readers:
I’ve been told by someone who should know that the projected “skyrocketing medical costs” which we hear so much about from politicians are based on a “cost per day in the hospital” number, i.e. as that index goes up, we assume medical costs will go up in tandem.
There’s a very good reason to consider this a biased proxy for medical costs, however. Namely, lots of things that used to be in-patient procedures (think gallbladder operations, which used to require a huge operation and many days of ICU care) are now out-patient procedures, so they don’t require a full day in the hospital.
This is increasingly true for various procedures – what used to take many days in the hospital recovering now takes fewer (or they kick you out sooner anyway). The result is that, on average, you only get to stay a whole day in the hospital if something’s majorly wrong with you, so yes the costs there are much higher. Thus the biased proxy.
A better index of cost would be: the cost of the average person’s medical expenses per year.
First question: Is this indeed how people calculate projected medical costs? It’s surprisingly hard to find a reference. That’s a bad sign. I’d really love a reference.
Next, I have a separate pet theory on why we are so willing to believe whatever we’re told about medical costs.
I’ve been planning for months to write a venty post about medical bills and HMO insurance paper mix-ups (update: wait, I did in fact write this post already). Specifically, it’s my opinion that the system is intentionally complicated so that people will end up paying stuff they shouldn’t just because they can’t figure out who to appeal to.
Note that even the idea of appealing to authority for a medical bill presumes that you’ve had a good education and experience dealing with formality. As a former customer service representative at a financial risk software company, I’m definitely qualified, but I can’t believe that the average person in this country isn’t overwhelmed by the prospect. It’s outrageous.
Part of this fear and anxiety stems from the fact that the numbers on the insurance claims are so inflated – $1200 to be seen for a dislocated finger being put into a splint, things like that. Why does that happen? I’m not sure, but I believe those are fake numbers that nobody actually pays, or at least nobody with insurance.
Second question: Why are the numbers on insurance claims so inflated? Who pays those actual numbers?
On to my theory: by extension of the above byzantine system of insurance claims and inflated prices for everything, we’re essentially primed for the line coming from politicians, who themselves (of course) lean on experts who “have studied this,” that health care costs are skyrocketing and that we can’t possibly allow “entitlements” to continue to grow the way they have been. A couple of comments:
- As was pointed out here (hat tip Deb), the fact that the numbers are already inflated so much, especially in comparison to other countries, should mean that they will tend to go down in the future, not up, as people travel away from our country to pay less. This is of course already happening.
- Even so, psychologically, we are ready for those numbers to say anything at all. $120,000 for a splint? Ok, sounds good, I hope I’m covered.
- Next, it’s certainly true that with technological advances come expensive techniques, especially for end-of-life and neonatal procedures. But on the other hand technology is also making normal, mid-life procedures (gallbladders removal) much cheaper.
- I would love to see a few histograms on this data, based on age of patient or prevalence of problem.
- I’d guess such histograms would show us the following: the overall costs structure is becoming much more fat-tailed, as the uncommon but expensive procedures are being used, but the mean costs could easily be going down, or could be projected to go down once more doctors and hospitals have invested in these technologies. Of course I have no idea if this is true.
Third question: Anyone know where such data can be found so I can draw me some histograms?
Final notes:
- The baby boomers are a large group, and they’re retiring and getting sick. But they’re not 10 times bigger than other generations, and the “exponential growth” we’ve been hearing about doesn’t get explained by this alone.
- Assume for a moment that medical costs are rising but not skyrocketing, which is my guess. Why would people (read: politicians) be so eager to exaggerate this?
Amazon’s binder reviews
If you go to amazon.com and search for “binder” or “3-ring binder” (h/t Dan), the very first hit will take you to the sale page for Avery’s Economy Binder with 1-Inch Round Ring, Black, 1 Binder (3301). The reviews are hilarious and subversive, including this one entitled “A Legitimate Binder”:
I am so excited to order this binder! My husband said that I’ve been doing such a great job of cutting out of work early to serve him meat and potatoes all these years, and he’s finally letting me upgrade from a 2-ring without pockets to a binder with 3 rings and two pockets! The pockets excite me the most. I plan to use the left pocket to hold my resume which will highlight my strongest skills which include but are not limited to laughing while eating yogurt. The right pocket will be great for keeping my stash of aspirin, in case of emergencies when I need to hold it between my knees.
Here’s another, entitled “Doesn’t work as advertised“:
Could’t bind a single damn woman with it! Most women just seem vaguely annoyed when I put it on them and it falls right off. Am I missing something? How’d Mitt do it?
Or this one, called “Such a bargain!“:
I am definitely buying this binder full of women, because even though it works the same as other male binders, you only have to pay $.77 on the dollar for it!
But my favorite one is this (called “Great with Bic lady pens”), partly because it points me to another subversive Amazon-rated product:
I’ve been having a hard time finding a job recently, and realized it was because I wasn’t in a binder. I thought the Avery Economy Binder would be perfect. It needs some tweaks, though. It kicks me out at 5pm so I can cook dinner for a family I don’t have. I also don’t seem to be making as much as the binderless men. And sometimes the rings will snag the lady parts, so maybe mine is defective.
By the way, the BIC pens for Her are a great complement to this binder. I wondered why the normal pens just didn’t feel right. It turns out, I was using man pens. The pink and purple also affirms me as a woman. You can find them here.
I know it says “for her” on the package but I, like many, assumed it was just a marketing ploy seeking to profit off of archaic gender constructs and the “war of the sexes”. Little did I realize that these pens really are for girls, and ONLY girls. Non-girls risk SERIOUS side effects should they use this product. I lent one to my 13-year-old brother, not thinking anything of it, and woke up the next morning to the sound of whinnying coming from the room across the hall. I got out of bed and went to his room to find that my worst fears had been realized:
MY LITTLE BROTHER IS NOW A UNICORN and it’s all my fault. Sure, you’d think that having a unicorn for a little brother would be great but my parents are FURIOUS – I’ve been grounded for a MONTH!!! They made an appointment for him with our family practitioner, but I’m not sure it’ll do any good, and they told me that if it couldn’t be fixed I’d have to get a job to help pay for his feed and lodging D:I repeat, boys, DO NOT USE THIS PEN. Unless you want to be a unicorn, and even then be careful because there’s no telling that you’ll suffer the same side effects.SERIOUSLY BIC IT’S REALLY REALLY IRRESPONSIBLE FOR YOU TO PUT OUT THIS PRODUCT WITHOUT A CLEAR WARNING OF THE RISK IT POSES TO NON-GIRLS. Just saying it’s “For Her” is not enough!!!!
(I’m giving it two stars because even though they got me grounded, the pens still write really nice and bring out my eyes)
Birdwatching
Today I’m posting my friend Becky’s poem about wasting time on a hobby you love. I spent the day at a yarn festival admiring hand-spun, dyed, and knit sweaters that cost about 5 times as much money and infinitely more time than the machine-made ones you can buy in any clothing store. I believe there’s no economic theory that could possibly explain why thousands of other people were just as excited as I was to be there.
——
What pastime could be less economically productive?
Owl swivels her tufted attention,
fixing her severity
on a silent stirring
in the fraying field
a mute meditation
just beyond
my upturned incomprehension.
What activity could be of less social value?
Hawk tears into hare
with his Swiss Army face,
unblinkingly slices
the limp sinew of snow,
a leap of fur
a moment before.
What hobby could be of less measurable benefit?
Egret unfolds her fistful of light,
lifts her improbable wings,
no metaphor for an angel
but the real deal –
You can see for yourself
how Spirit fancies feathers.
What avocation could be a more fervent waste of time?
Only Prayer –
Hummingbird’s eggs are a pair of pearl earrings
nestled in a pocket of lichen and silk –
and Love,
Loon’s lone lament.
What’s a fair price?
My readers may be interested to know that I am currently composing an acceptance letter to be on the board of Goldman Sachs.
Not that they’ve offered it, but Felix Salmon was kind enough to suggest me for the job yesterday and I feel like I should get a head start. Please give me suggestions for key phrases: how I’d do things differently or not, why I would be a breath of fresh air, how it’s been long enough having the hens guard the fox house, etc., that kind of thing.
But for now, I’d like to bring up the quasi-modeling, quasi-ethical topic (my favorite!) of setting a price. My friend Eugene sent me this nice piece he read yesterday on recommendation engines describing the algorithms used by Netflix and Amazon among others, which is strangely similar to my post yesterday coming out of Matt Gattis’s experience working at hunch. It was written by Computer Science professors Joseph A. Konstan and John Riedl from the University of Minnesota, and it does a nice job of describing the field, although there isn’t as much explicit math and formulae.
One thing they brought up in their article is the idea of a business charging certain people more money for items they expect them to buy based on their purchase history. So, if Fresh Direct did this to me, I’d have to pay more every week for Amish Country Farms 1% milk, since we go through about 8 cartons a week around here. They could basically charge me anything they want for that stuff, my 4-year-old is made of 95% milk and 5% nutella.

Except, no, they couldn’t do that. I’d just shop somewhere else for it, somewhere nobody knew my history. It would be a pain to go back to the grocery store but I’d do it anyway, because I’d feel cheated by that system. I’d feel unfairly singled out. For me it would be an ethical decision, and I’d vocally and publicly try to shame the company that did that to me.
It reminds me of arguments I used to have at D.E. Shaw with some of my friends and co-workers who were self-described libertarians. I don’t even remember how they’d start, but they’d end with my libertarian friend positing that rich people should be charged more for the same item. I have some sympathy with some libertarian viewpoints but this isn’t one of them.
First of all, I’d argue, people don’t walk around with a sign on their face saying how much money they have in the bank (of course this is become less and less true as information is collected online). Second of all, even if Warren Buffett himself walked into a hamburger joint, there’s no way they’re going to charge him $1000 for a burger. Not because he can’t afford it, and not even because he could go somewhere else for a cheaper burger (although he could), but because it’s not considered fair.
In some sense rich people do pay more for things, of course. They spend more money on clothes and food than poor people. But on the other hand, they’re also getting different clothes and different food. And even if they spend more money on the exact same item, a pound of butter, say, they’re paying rent for the nicer environment where they shop in their pricey neighborhood.
Now that I write this, I realize I don’t completely believe it. There are exceptions when it is considered totally fair to charge rich people more. My example is that I visited Accra, Ghana, and the taxi drivers consistently quoted me prices that were 2 or 3 times the price of the native Ghanaians, and neither of us thought it was unfair for them to do so. When my friend Jake was with me he’d argue them down to a number which was probably more like 1.5 times the usual price, out of principle, but when I was alone I didn’t do this, possibly because I was only there for 2 weeks. In this case, being a white person in Accra, I basically did have a sign on my face saying I had more money and could afford to spend more.
One last thought on price gouging: it happens all the time, I’m not saying it doesn’t, I am just trying to say it’s an ethical issue. If we are feeling price gouged, we are upset about it. If we see someone else get price gouged, we typically want to expose it as unfair, even if it’s happening to someone who can afford it.
Columbia Data Science course, week 7: Hunch.com, recommendation engines, SVD, alternating least squares, convexity, filter bubbles
Last night in Rachel Schutt’s Columbia Data Science course we had Matt Gattis come and talk to us about recommendation engines. Matt graduated from MIT in CS, worked at SiteAdvisor, and co-founded hunch as its CTO, which recently got acquired by eBay. Here’s what Matt had to say about his company:
Hunch
Hunch is a website that gives you recommendations of any kind. When we started out it worked like this: we’d ask you a bunch of questions (people seem to love answering questions), and then you could ask the engine questions like, what cell phone should I buy? or, where should I go on a trip? and it would give you advice. We use machine learning to learn and to give you better and better advice.
Later we expanded into more of an API where we crawled the web for data rather than asking people direct questions. We can also be used by third party to personalize content for a given site, a nice business proposition which led eBay to acquire us. My role there was doing the R&D for the underlying recommendation engine.
Matt has been building code since he was a kid, so he considers software engineering to be his strong suit. Hunch is a cross-domain experience so he doesn’t consider himself a domain expert in any focused way, except for recommendation systems themselves.
The best quote Matt gave us yesterday was this: “Forming a data team is kind of like planning a heist.” He meant that you need people with all sorts of skills, and that one person probably can’t do everything by herself. Think Ocean’s Eleven but sexier.
A real-world recommendation engine
You have users, and you have items to recommend. Each user and each item has a node to represent it. Generally users like certain items. We represent this as a bipartite graph. The edges are “preferences”. They could have weights: they could be positive, negative, or on a continuous scale (or discontinuous but many-valued like a star system). The implications of this choice can be heavy but we won’t get too into them today.

So you have all this training data in the form of preferences. Now you wanna predict other preferences. You can also have metadata on users (i.e. know they are male or female, etc.) or on items (a product for women).
For example, imagine users came to your website. You may know each user’s gender, age, whether they’re liberal or conservative, and their preferences for up to 3 items.
We represent a given user as a vector of features, sometimes including only their meta data, sometimes including only their preferences (which would lead to a sparse vector since you don’t know all their opinions) and sometimes including both, depending on what you’re doing with the vector.
Nearest Neighbor Algorithm?
Let’s review nearest neighbor algorithm (discussed here): if we want to predict whether a user A likes something, we just look at the user B closest to user A who has an opinion and we assume A’s opinion is the same as B’s.
To implement this you need a definition of a metric so you can measure distance. One example: Jaccard distance, i.e. the number of things preferences they have in common divided by the total number of things. Other examples: cosine similarity or euclidean distance. Note: you might get a different answer depending on which metric you choose.
What are some problems using nearest neighbors?
- There are too many dimensions, so the closest neighbors are too far away from each other. There are tons of features, moreover, that are highly correlated with each other. For example, you might imagine that as you get older you become more conservative. But then counting both age and politics would mean you’re double counting a single feature in some sense. This would lead to bad performance, because you’re using redundant information. So we need to build in an understanding of the correlation and project onto smaller dimensional space.
- Some features are more informative than others. Weighting features may therefore be helpful: maybe your age has nothing to do with your preference for item 1. Again you’d probably use something like covariances to choose your weights.
- If your vector (or matrix, if you put together the vectors) is too sparse, or you have lots of missing data, then most things are unknown and the Jaccard distance means nothing because there’s no overlap.
- There’s measurement (reporting) error: people may lie.
- There’s a calculation cost – computational complexity.
- Euclidean distance also has a scaling problem: age differences outweigh other differences if they’re reported as 0 (for don’t like) or 1 (for like). Essentially this means that raw euclidean distance doesn’t explicitly optimize.
- Also, old and young people might think one thing but middle-aged people something else. We seem to be assuming a linear relationship but it may not exist
- User preferences may also change over time, which falls outside the model. For example, at Ebay, they might be buying a printer, which makes them only want ink for a short time.
- Overfitting is also a problem. The one guy is closest, but it could be noise. How do you adjust for that? One idea is to use k-nearest neighbor, with say k=5.
- It’s also expensive to update the model as you add more data.
Matt says the biggest issues are overfitting and the “too many dimensions” problem. He’ll explain how he deals with them.
Going beyond nearest neighbor: machine learning/classification
In its most basic form, we’ve can model separately for each item using a linear regression. Denote by 


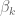


Remember, this model only works for one item. We need to build as many models as we have items. We know how to solve the above per item by linear algebra. Indeed one of the drawbacks is that we’re not using other items’ information at all to create the model for a given item.
This solves the “weighting of the features” problem we discussed above, but overfitting is still a problem, and it comes in the form of having huge coefficients when we don’t have enough data (i.e. not enough opinions on given items). We have a bayesian prior that these weights shouldn’t be too far out of whack, and we can implement this by adding a penalty term for really large coefficients.
This ends up being equivalent to adding a prior matrix to the covariance matrix. how do you choose lambda? Experimentally: use some data as your training set, evaluate how well you did using particular values of lambda, and adjust.
Important technical note: You can’t use this penalty term for large coefficients and assume the “weighting of the features” problem is still solved, because in fact you’re implicitly penalizing some coefficients more than others. The easiest way to get around this is to normalize your variables before entering them into the model, similar to how we did it in this earlier class.
The dimensionality problem
We still need to deal with this very large problem. We typically use both Principal Component Analysis (PCA) and Singular Value Decomposition (SVD).
To understand how this works, let’s talk about how we reduce dimensions and create “latent features” internally every day. For example, we invent concepts like “coolness” – but I can’t directly measure how cool someone is, like I could weigh them or something. Different people exhibit pattern of behavior which we internally label to our one dimension of “coolness”.
We let the machines do the work of figuring out what the important “latent features” are. We expect them to explain the variance in the answers to the various questions. The goal is to build a model which has a representation in a lower dimensional subspace which gathers “taste information” to generate recommendations.
SVD
Given a matrix 

Here 



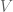

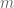

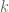
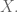
The rows of 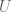

Important properties:
- The columns of
- So we can order the columns by singular values.
- We can take lower rank approximation of X by throwing away part of
In this way we might have
- There is an important interpretation to the values in the matrices
For example, we can see, by using SVD, that “the most important latent feature” is often something like seeing if you’re a man or a woman.
[Question: did you use domain expertise to choose questions at Hunch? Answer: we tried to make them as fun as possible. Then, of course, we saw things needing to be asked which would be extremely informative, so we added those. In fact we found that we could ask merely 20 questions and then predict the rest of them with 80% accuracy. They were questions that you might imagine and some that surprised us, like competitive people v. uncompetitive people, introverted v. extroverted, thinking v. perceiving, etc., not unlike MBTI.]
More details on our encoding:
- Most of the time the questions are binary (yes/no).
- We create a separate variable for every variable.
- Comparison questions may be better at granular understanding, and get to revealed preferences, but we don’t use them.
Note if we have a rank 

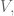
Note that the problem of sparsity or missing data is not fixed by the above SVD approach, nor is the computational complexity problem; SVD is expensive.
PCA
Now we’re still looking for 
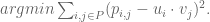
Let me explain. We denote by 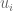



Then the dot product 

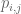

So, we want to find the best choices of
Now we have a parameter, namely the number 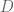
How do we choose 
But how do we actually find

Alternating Least Squares
This optimization doesn’t have a nice closed formula like ordinary least squares with one set of coefficients. Instead, we use an iterative algorithm like with gradient descent. As long as your problem is convex you’ll converge ok (i.e. you won’t find yourself at a local but not global maximum), and we will force our problem to be convex using regularization.
Algorithm:
- Pick a random
- Optimize
- Optimize
- Keep doing the above two steps until you’re not changing very much at all.
Example: Fix

The way we do this optimization is user by user. So for user

where
But wait a minute, this is the same as linear least squares, and has a closed form solution! In other words, set:

where 

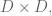
When you fix U and optimize V, it’s analogous; you only ever have to consider the users that rated that movie, which may be pretty large, but you’re only ever inverting a 
Another cool thing: since each user is only dependent on their item’s preferences, we can parallelize this update of
There are lots of different versions of this. Sometimes you need to extend it to make it work in your particular case.
Note: as stated this is not actually convex, but similar to the regularization we did for least squares, we can add a penalty for large entries in 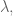

You can add new users, new data, keep optimizing U and V. You can choose which users you think need more updating. Or if they have enough ratings, you can decide not to update the rest of them.
As with any machine learning model, you should perform cross-validation for this model – leave out a bit and see how you did. This is a way of testing overfitting problems.
Thought experiment – filter bubbles
What are the implications of using error minimization to predict preferences? How does presentation of recommendations affect the feedback collected?
For example, can we end up in local maxima with rich-get-richer effects? In other words, does showing certain items at the beginning “give them an unfair advantage” over other things? And so do certain things just get popular or not based on luck?
How do we correct for this?
Growing old: better than the alternatives
I enjoyed this article in the Wall Street Journal recently entitled “The ‘New’ Old Age is No Way to Live”. In it the author rejects the idea of following his Baby Boomer brethren in continuing to exercise daily, being hugely productive, and just generally being in denial of their age. From the article:
We are advised that an extended life span has given us an unprecedented opportunity. And if we surrender to old age, we are fools or, worse, cowards. Around me I see many of my contemporaries remaining in their prime-of-life vocations, often working harder than ever before, even if they have already achieved a great deal. Some are writing the novels stewing in their heads but never attempted, or enrolling in classes in conversational French, or taking up jogging, or even signing up for cosmetic surgery and youth-enhancing hormone treatments.
The rest of the article is devoted to describing his trip to the Greek island of Hydra to research how to grow old. There are lots of philosophical references as well as counter-intuitive defenses of being set in your ways and how striving is empty-headed. Whatever, it’s his column. Personally, I like changing my mind about things and striving.
The point I want to make is this: there are far too few people coming out and saying that getting old can be a good thing. It can be a fun thing. Our culture is so afraid of getting old, it’s almost as bad as being fat on the list of no-nos.
I don’t get it. Why? Why can’t we be proud of growing old? It allows us, at the very least, to hold forth more, which is my favorite thing to do.
Since I turned 40 I’ve stopped dying my hair, which is going white, and I’ve taken to calling the people around me “honey”, “sugar”, or “baby”. I feel like I can get away with that now, which is fun. Honestly I’m looking forward to the stuff I can say and do when I’m 70, because I’m planning to be one of those outrageous old women full of spice and opinions. I’m going to make big turkey dinners with all the fixings even when it’s just October and invite my neighbors and friends to come over if my kids are too busy with their lives and family. But if they decide to visit, and if they have kids themselves, I’m going to spoil my grandkids rotten, because I’m totally allowed to do that when I’m the grandma.
Instead of lying about my age down, I’ve taken to lying about my age up. I feel like I am getting away with something if I can pass for 50. After all, why would I still want to be 30? I was close to miserable back then, and I’ve learned a ton in the past 10 years.
Update: my friend Cosma just sent me this poem by Jenny Joseph. For the record I’m wearing purple today:
Warning
When I am an old woman I shall wear purple
With a red hat which doesn’t go, and doesn’t suit me.
And I shall spend my pension on brandy and summer gloves
And satin sandals, and say we’ve no money for butter.
I shall sit down on the pavement when I’m tired
And gobble up samples in shops and press alarm bells
And run my stick along the public railings
And make up for the sobriety of my youth.
I shall go out in my slippers in the rain
And pick flowers in other people’s gardens
And learn to spit.
You can wear terrible shirts and grow more fat
And eat three pounds of sausages at a go
Or only bread and pickle for a week
And hoard pens and pencils and beermats and things in boxes.
But now we must have clothes that keep us dry
And pay our rent and not swear in the street
And set a good example for the children.
We must have friends to dinner and read the papers.
But maybe I ought to practice a little now?
So people who know me are not too shocked and surprised
When suddenly I am old, and start to wear purple.
Causal versus causal
Today I want to talk about the different ways the word “causal” is thrown around by statisticians versus finance quants, because it’s both confusing and really interesting.
But before I do, can I just take a moment to be amazed at how pervasive Gangnam Style has become? When I first posted the video on August 1st, I had no idea how much of a sensation it was destined to become. Here’s the Google trend graph for “Gangnam” versus “Obama”:

It really hit home last night as I was reading a serious Bloomberg article take on the economic implications of Gangnam Style whilst the song was playing in the background at the playoff game between the Cardinals and the Giants.
Back to our regularly scheduled program. I’m first going to talk about how finance quants think about “causal models” and second how statisticians do. This has come out of conversations with Suresh Naidu and Rachel Schutt.
Causal modeling in finance
When I learned how to model causally, it basically meant something very simple: I never used “future information” to make a prediction about the future. I was strictly using information from the past, or that was available and I had access to, to make predictions about the future. In other words, as I trained a model, I always had in mind a timestamp explaining what the “present time” is, and all data I had access to at that moment had timestamps of availability for before that present time so that I could use this information to make a statement about what I think would happen after that present time. If I did this carefully, then my model was termed “causal.” It respected time, and in particular it didn’t have great-looking predictive power just because it was peeking ahead.
Causal modeling in statistics
By contrast, when statisticians talk about a causal model, they mean something very different. Namely, they mean whether the model shows that something caused something else to happen. For example, if we saw certain plants in a certain soil all died but those in a different soil lived, then they’d want to know if the soil caused the death of the plants. Usually to answer this kind of questions, in an ideal situation, statisticians set up randomly chosen experiments where the only difference between the treatments is that one condition (i.e. the type of soil, but not how often you water it or the type of sunlight it gets). When they can’t set it up perfectly (say because it involves people dying instead of plants) they do the best they can.
The differences and commonalities
On the one hand both concepts refer and depend on time. There’s no way X caused Y to happen if X happened after Y. But whereas in finance we only care about time, in statistics there’s more to it.
So for example, if there’s a third underlying thing that causes both X and Y, but X happens before Y, then the finance people are psyched because they have a way of betting on the direction of Y: just keep an eye on X! But the statisticians are not amused, since there’s no way to prove causality in this case unless you get your hands on that third thing.
Although I understand wanting to know the underlying reasons things happen, I have a personal preference for the finance definition, which is just plain easier to understand and test, and usually the best we can do with real world data. In my experience the most interesting questions relate to things that you can’t set up experiments for. So, for example, it’s hard to know whether blue-collar presidents would be impose less elitist policy than millionaires, because we only have millionaires.
Moreover, it usually is interesting to know what you can predict for the future knowing what you know now, even if there’s no proof of causation, and not only because you can maybe make money betting on something (but that’s part of it).
Gaming the Google mail filter and the modeling feedback loop
The gmail filter
If you’re like me, a large part of your life takes place in your gmail account. My gmail address is the only one I use, and I am extremely vigilant about reading emails – probably too much so.
On the flip side, I spend quite a bit of energy removing crap from my gmail. When I have the time and opportunity, and if I receive an unwanted email, I will set a gmail filter instead of just deleting. This is usually in response to mailing lists I get on by buying something online, so it’s not quite spam. For obvious spam I just click on the spam icon and it disappears.
You see, when I check out online to pay for my stuff, I am not incredibly careful about making sure I’m not signing up to be on a mailing list. I just figure I’ll filter anything I don’t want later.
Which brings me to the point. I’ve noticed lately that, more and more often, the filter doesn’t work, at least on the automatic setting. If you open an email you don’t want, you can click on “filter messages like these” and it will automatically fill out a filter form with the “from” email address that is listed.

More and more often, these quasi-spammers are getting around this somehow. I don’t know how they do it, because it’s not as simple as changing their “from” address every time, which would work pretty well. Somehow not even the email I’ve chosen to filter is actually deleted through this process.
I end up having to copy and paste the name of the product into a filter, but this isn’t a perfect solution either, since then if my friend emails me about this product I will automatically delete that genuine email.
The modeling feedback loop
This is a perfect example of the feedback loop of modeling; first there was a model which automatically filled out a filter form, then people in charge of sending out mailing lists for products realized they were being successfully filtered and figured out how to game the model. Now the model doesn’t work anymore.
The worst part of the gaming strategy is how well it works. If everybody uses the filter model, and you are the only person who games it, then you have a tremendous advantage over other marketers. So the incentive for gaming is very high.
Note this feedback loop doesn’t always exist: the stars and planets didn’t move differently just because Newton figured out his laws, and people don’t start writing with poorer penmanship just because we have machine learning algorithms that read envelopes at the post office.
But this feedback loop does seem to be associated with especially destructive models (think rating agency models for MBS’s and CDO’s). In particular, any model which is “gamed” to someone’s advantage probably exhibits something like this. It will work until the modelers strike back with a better model, in an escalation not unlike an arms race (note to ratings agency modelers: unless you choose to not make the model better even when people are clearly gaming it).
As far as I know, there’s nothing we can do about this feedback loop except to be keenly aware of it and be ready for war.
The investigative mathematical journalist
I’ve been out of academic math a few years now, but I still really enjoy talking to mathematicians. They are generally nice and nerdy and utterly earnest about their field and the questions in their field and why they’re interesting.
In fact, I enjoy these conversations more now than when I was an academic mathematician myself. Partly this is because, as a professional, I was embarrassed to ask people stupid questions, because I thought I should already know the answers. I wouldn’t have asked someone to explain motives and the Hodge Conjecture in simple language because honestly, I’m pretty sure I’d gone to about 4 lectures as a graduate student explaining all of this and if I could just remember the answer I would feel smarter.
But nowadays, having left and nearly forgotten that kind of exquisite anxiety that comes out of trying to appear superhuman, I have no problem at all asking someone to clarify something. And if they give me an answer that refers to yet more words I don’t know, I’ll ask them to either rephrase or explain those words.
In other words, I’m becoming something of an investigative mathematical journalist. And I really enjoy it. I think I could do this for a living, or at least as a large project.
What I have in mind is the following: I go around the country (I’ll start here in New York) and interview people about their field. I ask them to explain the “big questions” and what awesomeness would come from actually having answers. Why is their field interesting? How does it connect to other fields? What is the end goal? How would achieving it inform other fields?
Then I’d write them up like columns. So one column might be “Hodge Theory” and it would explain the main problem, the partial results, and the connections to other theories and fields, or another column might be “motives” and it would explain the underlying reason for inventing yet another technology and how it makes things easier to think about.
Obviously I could write a whole book on a given subject, but I wouldn’t. My audience would be, primarily, other mathematicians, but I’d write it to be readable by people who have degrees in other quantitative fields like physics or statistics.
Even more obviously, every time I chose a field and a representative to interview and every time I chose to stop there, I’d be making in some sense a political choice, which would inevitably piss someone off, because I realize people are very sensitive to this. This is presuming anybody every read my surveys in the first place, which is a big if.
Even so, I think it would be a contribution to mathematics. I actually think a pretty serious problem with academic math is that people from disparate fields really have no idea what each other is doing. I’m generalizing, of course, and colloquiums do tend to address this, when they are well done and available. But for the most part, let’s face it, people are essentially only rewarded for writing stuff that is incredibly “insider” for their field. that only a few other experts can understand. Survey of topics, when they’re written, are generally not considered “research” but more like a public service.
And by the way, this is really different from the history of mathematics, in that I have never really cared about who did what, and I still don’t (although I’m not against name a few people in my columns). The real goal here is to end up with a more or less accurate map of the active research areas in mathematics and how they are related. So an enormous network, with various directed edges of different types. In fact, writing this down makes me want to build my map as I go, an annotated visualization to pair with the columns.
Also, it obviously doesn’t have to be me doing all this: I’m happy to make it an open-source project with a few guidelines and version control. But I do want to kick it off because I think it’s a neat idea.
A few questions about my mathematical journalism plan.
- Who’s going to pay me to do this?
- Where should I publish it?
If the answers are “nobody” and “on mathbabe.org” then I’m afraid it won’t happen, at least by me. Any ideas?
One more thing. This idea could just as well be done for another field altogether, like physics or biology. Are there models of people doing something like that in those fields that you know about? Or is there someone actually already doing this in math?
Philanthropy can do better than Rajat Gupta
Last night I was watching a YouTube video in between playoff games (both of which disappointed). Conan O’Brien was accepting an honorary patronage at the philosophical society of the University of Dublin. His speech was hilarious, and there was an extended, intimate Q&A session afterwards.
One thing he mentioned was an amended version of the (to me, very moving) words he had closed his last NBC Tonight Show with, “If you work really hard and you’re kind then amazing things will happen.” Namely, he wanted to add this sentence: “If you work really hard and you’re a huge asshole, then you can make tons of money on Wall Street.”
These wise words came back to me this morning when I read about Bill Gates and Kofi Annan’s letters to Judge Jed Rakoff regarding Goldman Sachs insider trader Rajat Gupta. The letters were intended to reduce sentencing, considering how unbelievably philanthropical Gupta had been as he was stealing all this money.
I’m not doubting that the dude did some good things with his ill-gotten gains. After all, I don’t have a letter from Bill Gates about how I helped remove malaria from the world.
But wait a minute, maybe that’s because I didn’t steal money from taxpayers like he did to put myself into the position of spending millions of dollars doing good things! Because I’m thinking that if I had the money that Gupta had, I might well have spent good money doing good things.
And therein lies the problem with this whole picture. He did some good (I’ll assume), but then again he had the advantage of being someone in our society who could do good, i.e. he was loaded. Wouldn’t it make more sense for us to set up a system wherein people could do good who are good, who have good ideas and great plans?
Unfortunately, those people exist, but they’re generally poor, or stuck in normal jobs making ends meet for their family, and they don’t get their plans heard. In particular they aren’t huge assholes stealing money and then trying to get out of trouble by hiring hugely expensive lawyers and leaning on their philanthropy buds.
The current system of grant-writing doesn’t at all support the people with good ideas: it doesn’t teach these “social inventors” how to build a charitable idea into a business plan. So what happens is that the good ideas drift away without the important detailed knowledge of how to surround it with resources. And generally the people with really innovative ideas aren’t by nature detail-oriented people who can figure out how to start a business, they’re kind of nerdy.
I’m serious, I think the government should sponsor something like a “philanthropy institute” for entrepreneurial non-revenue generating ideas that are good for society. People could come to open meetings and discuss their ideas for improving stuff, and there’d be full-time staff and fellows, with the goal of seizing upon good ideas and developing them like business plans.
Personal privacy and institutional transparency
Ever noticed that it’s vulnerable individuals who are transparent about their data (i.e. public and open on Facebook and the like) whereas it’s for-profit institutions like pharmaceutical companies, charged with being stewards of public health, that get to be as down-low as they want?
Do you agree with me that that’s ass-backwards?
Well, there were two potentially good things mentioned in yesterday’s New York Times to ameliorate this mismatch. I say “potentially” because they are both very clearly susceptible to political spin-doctoring.
The first is that Big Pharma company GlaxoSmithKline has claimed they will be more transparent about their internal medical trials, even the ones that fail. This would be a huge step in the right direction if it really happens.
The second is that Senator John D. Rockefeller IV of West Virginia is spearheading an investigation into data brokers and the industry of information warehousing. A good step towards better legislation but this could just be a call for lobbyists money, so I’ll believe it when I see it.
What with the whole-genome DNA sequencing methods getting relatively cheap, modern privacy legislation is desperately needed so people won’t be afraid to use life-saving techniques for fear of losing their health insurance. Obama’s Presidential Commission for the Study of Bioethical Issues agrees with me.




{kind=link}