Archive
Statisticians aren’t the problem for data science. The real problem is too many posers
Crossposted on Naked Capitalism
Cosma Shalizi
I recently was hugely flattered by my friend Cosma Shalizi’s articulate argument against my position that data science distinguishes itself from statistics in various ways.
Cosma is a well-read broadly educated guy, and a role model for what a statistician can be, not that every statistician lives up to hist standard. I’ve enjoyed talking to him about data, big data, and working in industry, and I’ve blogged about his blogposts as well.
That’s not to say I agree with absolutely everything Cosma says in his post: in particular, there’s a difference between being a master at visualizations for the statistics audience and being able to put together a power point presentation for a board meeting, which some data scientists in the internet start-up scene definitely need to do (mostly this is a study in how to dumb stuff down without letting it become vapid, and in reading other people’s minds in advance to see what they find sexy).
And communications skills are a funny thing; my experience is communicating with an academic or a quant is a different kettle of fish than communicating with the Head of Product. Each audience has its own dialect.
But I totally believe that any statistician who willingly gets a job entitled “Data Scientist” would be able to do these things, it’s a self-selection process after all.
Statistics and Data Science are on the same team
I think that casting statistics as the enemy of data science is a straw man play. The truth is, an earnest, well-trained and careful statistician in a data scientist role would adapt very quickly to it and flourish as well, if he or she could learn to stomach the business-speak and hype (which changes depending on the role, and for certain data science jobs is really not a big part of it, but for others may be).
It would be a petty argument indeed to try to make this into a real fight. As long as academic statisticians are willing to admit they don’t typically spend just as much time (which isn’t to say they never spend as much time) worrying about how long it will take to train a model as they do wondering about the exact conditions under which a paper will be published, and as long as data scientists admit that they mostly just redo linear regression in weirder and weirder ways, then there’s no need for a heated debate at all.
Let’s once and for all shake hands and agree that we’re here together, and it’s cool, and we each have something to learn from the other.
Posers
What I really want to rant about today though is something else, namely posers. There are far too many posers out there in the land of data scientists, and it’s getting to the point where I’m starting to regret throwing my hat into that ring.
Without naming names, I’d like to characterize problematic pseudo-mathematical behavior that I witness often enough that I’m consistently riled up. I’ll put aside hyped-up, bullshit publicity stunts and generalized political maneuvering because I believe that stuff speaks for itself.
My basic mathematical complaint is that it’s not enough to just know how to run a black box algorithm. You actually need to know how and why it works, so that when it doesn’t work, you can adjust. Let me explain this a bit by analogy with respect to the Rubik’s cube, which I taught my beloved math nerd high school students to solve using group theory just last week.
Rubiks
First we solved the “position problem” for the 3-by-3-by-3 cube using 3-cycles, and proved it worked, by exhibiting the group acting on the cube, understanding it as a subgroup of 
I did this three times, with the three classes, and each time a student would ask me if the algorithm is efficient. No, it’s not efficient, it takes about 4 minutes, and other people can solve it way faster, I’d explain. But the great thing about this algorithm is that it seamlessly generalizes to other problems. Using similar sign arguments and basic 3-cycle moves, you can solve the 7-by-7-by-7 (or any of them actually) and many other shaped Rubik’s-like puzzles as well, which none of the “efficient” algorithms can do.
Something I could have mentioned but didn’t is that the efficient algorithms are memorized by their users, are basically black-box algorithms. I don’t think people understand to any degree why they work. And when they are confronted with a new puzzle, some of those tricks generalize but not all of them, and they need new tricks to deal with centers that get scrambled with “invisible orientations”. And it’s not at all clear they can solve a tetrahedron puzzle, for example, with any success.
Democratizing algorithms: good and bad
Back to data science. It’s a good thing that data algorithms are getting democratized, and I’m all for there being packages in R or Octave that let people run clustering algorithms or steepest descent.
But, contrary to the message sent by much of Andrew Ng’s class on machine learning, you actually do need to understand how to invert a matrix at some point in your life if you want to be a data scientist. And, I’d add, if you’re not smart enough to understand the underlying math, then you’re not smart enough to be a data scientist.
I’m not being a snob. I’m not saying this because I want people to work hard. It’s not a laziness thing, it’s a matter of knowing your shit and being for real. If your model fails, you want to be able to figure out why it failed. The only way to do that is to know how it works to begin with. Even if it worked in a given situation, when you train on slightly different data you might run into something that throws it for a loop, and you’d better be able to figure out what that is. That’s your job.
As I see it, there are three problems with the democratization of algorithms:
- As described already, it lets people who can load data and press a button describe themselves as data scientists.
- It tempts companies to never hire anyone who actually knows how these things work, because they don’t see the point. This is a mistake, and could have dire consequences, both for the company and for the world, depending on how widely their crappy models get used.
- Businesses might think they have awesome data scientists when they don’t. That’s not an easy problem to fix from the business side: posers can be fantastically successful exactly because non-data scientists who hire data scientists in business, i.e. business people, don’t know how to test for real understanding.
How do we purge the posers?
We need to come up with a plan to purge the posers, they are annoying and making a bad name for data science.
One thing that will be helpful in this direction is Rachel Schutt’s Data Science class at Columbia next semester, which is going to be a much-needed bullshit free zone. Note there’s been a time change that hasn’t been reflected on the announcement yet, namely it’s going to be once a week, Wednesdays for three hours starting at 6:15pm. I’m looking forward to blogging on the contents of these lectures.
Columbia Data Science Institute: it’s gonna happen
So Bloomberg finally got around to announcing the Columbia Data Science Institute is really going to happen. The details as we know them now:
- It’ll be at the main campus, not Manhattanville.
- It’ll hire 75 faculty over the next decade (specifically, 30 new faculty by launch in August 2016 and 75 by 2030, so actually more than a decade but who’s counting?).
- It will contain a New Media Center, a Smart Cities Center, a Health Analytics Center, a Cybersecurity Center, and a Financial Analytics Center.
- The city is pitching in $15 million whereas Columbia is ponying up $80 million.
- Columbia Computer Science professor Kathy McKeown will be the Director and Civil Engineering professor Patricia Culligan will be the Institute’s Deputy Director.
The douche burger, and putting a ruler to the dick.
I have been pretty hardcore and serious for a few weeks, and today I want to lighten it up for a change.
Douchery
First, I want everyone to read this article about a New York City food truck that sells douche burgers. From the article:
For just $666 you can purchase a foie gras-stuffed Kobe patty covered in Gruyere cheese that’s been melted with champagne steam and topped with lobster, truffles, caviar, and a BBQ sauce made with Kopi Luwak coffee beans that have been pooped out by some sort of animal called the Asian palm civet. The whole thing is then served in a gold-leaf wrapper.

Two things I like about this article, first that it’s hilarious and over the top satire, which is always excellent, and second that the world is picking up on my idea of calling people douches when they get really into esoteric stuff.
If you don’t believe me, read my previous post My friend the coffee douche. It’s one of my favorites.
Putting a ruler to the dick
Next, speaking of using language in a funny but pointed way, are you with me that “opening the kimono” is an offensive and sexist phrase? Well, how about we replace it with a better, more offensive, and more sexist phrase that’s even more fun to say, namely “putting a ruler to the dick”??
This was my friend Laura Strausfeld’s idea, and I love it. It’s gonna be the buzzword (buzzphrase) of the year, we just know it.
Here’s how it works in context:
guy A: “So do you think you’ll invest in those guys? They seemed really excited about that new technique they’ve developed!”
guy B: “I don’t know. They talked a big game, but until I can put a ruler to the dick I’m not putting my money there.”
Does mathematics have a place in higher education?
A recent New York Times Opinion piece (hat tip Wei Ho), Is Algebra Necessary?, argues for the abolishment of algebra as a requirement for college. It was written by Andrew Hacker, an emeritus professor of political science at Queens College, City University of New York. His concluding argument:
I’ve observed a host of high school and college classes, from Michigan to Mississippi, and have been impressed by conscientious teaching and dutiful students. I’ll grant that with an outpouring of resources, we could reclaim many dropouts and help them get through quadratic equations. But that would misuse teaching talent and student effort. It would be far better to reduce, not expand, the mathematics we ask young people to imbibe. (That said, I do not advocate vocational tracks for students considered, almost always unfairly, as less studious.)
Yes, young people should learn to read and write and do long division, whether they want to or not. But there is no reason to force them to grasp vectorial angles and discontinuous functions. Think of math as a huge boulder we make everyone pull, without assessing what all this pain achieves. So why require it, without alternatives or exceptions? Thus far I haven’t found a compelling answer.
For an interesting contrast, there’s a recent Bloomberg View Piece, How Recession Will Change University Financing, by Gary Shilling (not to be confused with Robert Shiller). From Shilling’s piece:
Most thought that a bachelor’s degree was the ticket to a well-paid job, and that the heavy student loans were worth it and manageable. And many thought that majors such as social science, education, criminal justice or humanities would still get them jobs. They didn’t realize that the jobs that could be obtained with such credentials were the nice-to-have but nonessential positions of the boom years that would disappear when times got tough and businesses slashed costs.
Some of those recent graduates probably didn’t want to do, or were intellectually incapable of doing, the hard work required to major in science and engineering. After all, afternoon labs cut into athletic pursuits and social time. Yet that’s where the jobs are now. Many U.S.-based companies are moving their research-and-development operations offshore because of the lack of scientists and engineers in this country, either native or foreign-born.
For 34- to 49-year-olds, student debt has leaped 40 percent in the past three years, more than for any other age group. Many of those debtors were unemployed and succumbed to for-profit school ads that promised high-paying jobs for graduates. But those jobs seldom materialized, while the student debt remained.
Moreover, many college graduates are ill-prepared for almost any job. A study by the Pew Charitable Trusts examined the abilities of U.S. college graduates in three areas: analyzing news stories, understanding documents and possessing the math proficiency to handle tasks such as balancing a checkbook or tipping in a restaurant.
The first article is written by a professor, so it might not be surprising that, as he sees more and more students coming through, he feels their pain and wants their experience to not be excruciating. The easiest way to do that is to remove the stumbling block requirement of math. He also seems to think of higher education as something everyone is entitled to, which I infer based on how he dismisses vocational training.
The second article is written by a financial analyst, an economist, so we might not be surprised that he strictly sees college as a purely commoditized investment in future income, and wants it to be a good one. The easiest way to do that is to have way fewer students go through college to begin with, since having dumb or bad students get into debt but not learn anything and then not get a job afterwards doesn’t actually make sense.
And where the first author acts like math is only needed for a tiny minority of college students, the second author basically dismisses non-math oriented subjects as frivolous and leading to a life of joblessness and debt. These are vastly different viewpoints. I’m thinking of inviting them both to dinner to discuss.
By the way, I think that last line, where Hacker wonders what the pain of math-as-huge-boulder achieves, is more or less answered by Shilling. The goal of having math requirements is to have students be mathematically literate, which is to say know how to do everyday things like balancing checkbooks and reading credit card interest rate agreements. The fact that we aren’t achieving this goal is important, but the goal is pretty clear. In other words, I think my dinner party would be fruitful as well as entertaining.
If there’s one thing these two agree on, it’s that students are having an awful lot of trouble doing basic math. This makes me wonder a few things.
First, why is algebra such a stumbling block? Is it that the students are really that bad, or is the approach to teaching it bad? I suspect what’s really going on is that the students taking it have mostly not been adequately taught the pre-requisites. That means we need more remedial college math.
I honestly feel like this is the perfect place for online learning. Instead of charging students enormous fees while they get taught high-school courses they should already know, and instead of removing basic literacy requirements altogether, ask them to complete some free online math courses at home or in their public library, to get them ready for college. The great thing about computers is that they can figure out the level of the user, and they never get impatient.
Next, should algebra be replaced by a Reckoning 101 course? Where, instead of manipulating formulas, we teach students to figure out tips and analyze news stories and understand basic statistical statements? I’m sure this has been tried, and I’m sure it’s easy to do badly or to water down entirely. Please tell me what you know. Specifically, are students better at snarky polling questions if they’ve taken these classes than if they’ve taken algebra?
Finally, I’d say this (and I’m stealing this from my friend Kiri, a principal of a high school for girls in math and science): nobody ever brags about not knowing how to read, but people brag all the time about not knowing how to do math. There’s nothing to be proud of in that, and it’s happening to a large degree because of our culture, not intelligence.
So no, let’s not remove mathematical literacy as a requirement for college graduates, but let’s think about what we can do to make the path reasonable and relevant while staying rigorous. And yes, there are probably too many students going to college because it’s now a cultural assumption rather than a thought-out decision, and this lands young people in debt up to their eyeballs and jobless, which sucks (here’s something that may help: forcing for-profit institutions to be honest in advertising future jobs promises and high interest debt).
Something just occurred to me. Namely, it’s especially ironic that the most mathematically illiterate and vulnerable students are being asked to sign loan contracts that they, almost by construction, don’t understand. How do we address this? Food for thought and for another post.
Income distributions and misleading poll questions (#OWS)
Disingenuous, pseudo-quantitative arguments piss me off.
In this recent Bloomberg View article entitled “Making the rich poorer doesn’t enrich the middle class,” Caroline Baum argues that middle class people would rather get more money than take away money from rich people. From the article:
Polling by the Pew Research Center shows that people aren’t interested in taking money from the wealthy. They just want a chance to get rich themselves.
But that’s a misleading question. It seems like a zero sum game when you put it that way, equivalent to something like, “Would you rather gain $100 or have a rich person somewhere lose $100?”.
But if you pose the question differently, and more in line with actual numbers, not to mention contextualized to reality in other ways, then you’d probably get the opposite.
Let’s take a look at wealth distribution from 2007, which I got here:
 Let’s just say we’re being extreme and we take away all the wealth of the top 1% and give it to everybody equally (say we even give back some of it to those top 1%). That would mean that 34.6% get flattened out to 100 pots instead of one, which means that each of those percentiles gets about 0.35% more than they used to have. The middle 20% would grow from 4% of the overall wealth to (4 + 20*0.35)% = 11%. That’s still a lot less than 20%, but the wealth of the middle 20% is still nearly tripled by just this one percent re-distributing.
Let’s just say we’re being extreme and we take away all the wealth of the top 1% and give it to everybody equally (say we even give back some of it to those top 1%). That would mean that 34.6% get flattened out to 100 pots instead of one, which means that each of those percentiles gets about 0.35% more than they used to have. The middle 20% would grow from 4% of the overall wealth to (4 + 20*0.35)% = 11%. That’s still a lot less than 20%, but the wealth of the middle 20% is still nearly tripled by just this one percent re-distributing.
Said another way, it’s not tit-for-tat at all.
If we asked someone in the middle class which they want more, a 1% increase in their wealth or a top 1%’er to lose 1% of their wealth, then that might be very different. Consider the political influence that 1% represents, at the very least. Consider the fact that 1% of that person in the middle 20% is 173 times smaller than for the top 1%.
It’s still not fair, though, because the middle class is so squeezed on necessities like food, housing, education, medical expenses, and child care, that they can’t afford even a 1% loss. What if you took those out?
If you go even further and ask someone in the middle class which they want more, a 1% increase in their discretionary income or a top 1%’er to lose 1% of their discretionary income, then that might be very different still. I haven’t been able to find a similar graphic to work with to see the discretionary income distribution, but rest assured it’s even more unbalanced.
Caroline Baum, would you care to cover those questions on your next poll to the middle class?
Why is LIBOR such a big deal? (#OWS)
The manipulation of LIBOR interest rates by the big, mostly-European banks (but not entirely, see a full list here) was an open secret inside finance in 2008. As in so open that I didn’t think of it as a secret at all.
The fact that that manipulation is now consistently creating huge headlines is interesting to me – it brings up a few issues.
- People seem surprised this out-and-out manipulation was happening. That says to me that they clearly still don’t understand what the culture of finance is really like. The fact that Bob Diamond of Barclays claims to have felt “physically ill” when he saw the emails of the traders manipulating LIBOR is either an out-and-out lie or they guy is simple-minded, as in stupid. And word on the street is he’s not stupid.
- People still buy the line that most of the problems from the credit crisis arose from legal but wrong-headed efforts to make money, plus corrupt ratings on mortgage-backed securities. This is incredible to me. Let’s get it clear: the culture of finance is to take advantage of every opportunity to juice your bottom line, even if it’s wrong, even if it’s fraudulent, even if it affects the terms of loans on millions of houses and towns in other countries, and even if only your trading desk is benefiting.
- The LIBOR manipulation in 2008 was about more than that, namely trying not to look as bad as other banks, to avoid being the next Lehman. It was done in the name of not looking weak and requiring a government bailout. Bob Diamond still doesn’t think they did anything wrong by lying there. It was almost like they were doing something noble.
- Speaking of towns in other countries, read this article about how LIBOR manipulation has screwed U.S. cities to the ground. I’ve got a lot more to say about municipal debt and how that sleazy system works but it’s waiting for another post.
- Finally, why did it take so long for the media to pick up on LIBOR manipulation? It tempts me to make a list of the illegal stuff that we all knew about back then and send it around just to make sure.
Is open data a good thing?
As much as I like the idea of data being open and free, it’s not an open and shut case. As it were.
I’m first going to argue against open data with three examples.
The first is a pretty commonly discussed concern of privacy. Simply put, there is no such thing as anonymized data, and people who say there is are either lying or being naive. The amount of information you’d need to remove to really anonymize data is not known to be different from the amount of data you have in the first place. So if you did a good job to anonymize a data set, you’d probably remove all interesting information anyway. Of course, you could think this is only important with respect to individual data.
But my next example comes from land data, specifically Tamil Nadu in Southern India. There’s an interesting Crooked Timber blogpost here (hat tip Suresh Naidu) explaining how “open data” has screwed a local population, the Dalits. Although you could (and I would) argue that the way the data is collected and disseminated, and the fact that the courts go along with this process, is itself politically motivated and disenfrachising, there are some important point made in this post:
Open data undermines the power of those who benefit from “the idiosyncracies and complexities of communities… Local residents [who] understand the complexity of their community due to prolonged exposure.” The Bhoomi land records program is an example of this: it explicitly devalues informal knowledge of particular places and histories, making it legally irrelevant; in the brave new world of open data such knowledge is trumped by the ability to make effective queries of the “open” land records.15 The valuing of technological facility over idiosyncratic and informal knowledge is baked right in to open data efforts.
The Crooked Timber blog post specifically called out Tim O’Reilly and his “Government as Platform” project as troublesome:
The faith in markets sometimes goes further among open data advocates. It’s not just that open data can create new markets, there is a substantial portion of the push for open data that is explicitly seeking to create new markets as an alternative to providing government services.
It’s interesting to see O’Reilly’s Mike Loukides’s reaction (hat tip Chris Wiggins), entitled the Dark Side of Data, here. From Loukides:
The issue is how data is used. If the wealthy can manipulate legislators to wipe out generations of records and folk knowledge as “inaccurate,” then there’s a problem. A group like DataKind could go in and figure out a way to codify that older generation of knowledge. Then at least, if that isn’t acceptable to the government, it would be clear that the problem lies in political manipulation, not in the data itself. And note that a government could wipe out generations of “inaccurate records” without any requirement that the new records be open. In years past the monied classes would have just taken what they wanted, with the government’s support. The availability of open data gives a plausible pretext, but it’s certainly not a prerequisite (nor should it be blamed) for manipulation by the 0.1%.
[Speaking of DataKind (formerly Data Without Borders), it’s also a problem, as I discovered as a data ambassador working with the NYCLU on Stop, Question and Frisk data, when the government claims to be open but withholds essential data such as crime reports.]
My final example comes from finance. On the one hand I want total transparency of the markets, because it sickens me to think about how nobody knows the actual price of bonds, or the correct interest rate, or the current default assumption of the market, how all of that stuff is being kept secret by Wall Street insiders so they can each skim off their little cut and the dumb money players get constantly screwed.
But on the other hand, if I imagine a world where everything really is transparent, then even in the best of all database situations, that’s just asstons of data which only the very very richest and most technologically savvy high finance types could ever munge through.
So who would benefit? I’d say, for some time, the average dumb money customer would benefit very slightly, by not paying extra fees, but that the edgy techno finance firms would benefit fantastically. Then, I imagine, new ways would be invented for the dumb money customers to lost that small amount of benefit altogether, probably by just inundating them with so much data they can’t absorb it.
In other words, open data is great for the people who have the tools to use it for their benefit, usually to exploit other people and opportunities. It’s not clearly great for people who don’t have those tools.
But before I conclude that data shouldn’t be open, let me strike an optimistic (for me) tone.
The tools for the rest of us are being built right now. I’m not saying that the non-exploiters will ever catch up with the Goldman Sachs and credit card companies, because probably not.
But there will be real tools (already are things like python and R, and they’re getting better every day), built out of the open software movement, that will help specific people analyze and understand specific things, and there are platforms like wordpress and twitter that will allow those things to be broadcast, which will have real impact when the truth gets out. An example is the Crooked Timber blog post above.
So yes, open data is not an unalloyed good. It needs to be a war waged by people with common sense and decency against those who would only use it for profit and exploitation. I can’t think of a better thing to do with my free time.
Today is a day for politics
President Obama made comments last Friday in Fort Myers, Florida, about the Aurora theater shooting in Colorado. Here’s an excerpt of what he had to say:
So, again, I am so grateful that all of you are here. I am so moved by your support. But there are going to be other days for politics. This, I think, is a day for prayer and reflection.
This makes no sense. Actually, it’s offensive. When is it a day for politics, President Obama? And why are we treating this tragedy like an act of nature?
When a guy gets enough ammunition shipped to him legally, through the U.S. Post Office, to perform a massacre, and he rigs his house with sophisticated booby traps over months of preparation, we can safely say two things. First, this guy was absolutely insane, and second he had all of the resources available to him to kill dozens of people.
I can understand why, for the families of the victims, their therapists or priests may ask them to accept this fatalistically – they can’t get their loved one back. But as a nation, we should not be willing to be so passive in the face of what is obviously a fucked up system. We can imagine, I hope, a culture where it’s a wee bit more difficult to massacre innocent people if and when you decide that’s a good idea.
If you’re in doubt that this system is skewed towards the madman, keep in mind that the uninsured Aurora shooting victims are at risk of debtor’s prison in this country.
It begs the question of why we’ve become so inured to bad politicians. Notice I’m not saying inured to violence and random shootings, because we’re not, actually. We are all horrified, but in the face of such tragedy we shrug our shoulders and say stuff about the fact that there’s nothing we can do. Because that’s what our politicians say.
I’ll draw an analogy between this and the financial crisis, which is ongoing and could be getting worse. We often hear passive, third person narratives coming from our politicians and central bankers, who talk about the bankrupt banks and the corruption like there’s nothing we can actually do to fix this. Again, acts of nature.
Bullshit. These guys have been paid off by bank lobbyists and told to act impotent. They are following orders. Our country deserves better than this leadership, whose politicians give money to banks, which they turn around and use to buy off politicians. As Neil Barofsky said in his new book:
“The suspicions that the system is rigged in favor of the largest banks and their elites, so they play by their own set of rules to the disfavor of the taxpayers who funded their bailout, are true,” Mr. Barofsky said in an interview last week. “It really happened. These suspicions are valid.”
I’d like to separate, for a moment, two issues. First, what we have come to expect from Obama, who gave us such hope when he was elected. Second, what we deserve – what we should expect from a politician who cares about people and doing the right thing.
There’s a huge difference, but let’s not lose sight of that second thing. That’s when I turn from pissed to bitter, and I really don’t want to be bitter.
This is a day for politics, President Obama, so step it up. I’m not giving up hope that someone, though probably not you, can deliver it to us.
A call to Occupy: we should listen.
Yesterday a Bloomberg View article was published, written by Neil Barofsky.
In case you don’t remember, Barofsky was the special inspector general of the Troubled Asset Relief Program, which meant he was in charge of watching over TARP until he resigned in February 2011. And if you can judge a man by his enemies, then Barofsky is doing pretty well by being cussed out by Tim Geithner.
The Bloomberg View article was an excerpt from his new book, which comes out July 24th and which I’m going to have to find time to read, because this guy knows what’s going on and the politics behind possible change.
In the article, Barofsky tears through some of the most obvious and ridiculous shenanigans that the Obama administration and the Treasury have been up to in preserving the status quo whereby the banks get bailed out and the average person pays. In order, he obliterates:
- Obama’s HAMP project: “with fewer than 800,000 ongoing permanent modifications as of March 31, 2012, a number that is growing at the glacial pace of just 12,000 per month.”
- The recent mortgage settlement: “In return for what was touted as a $25 billion payout, the banks received broad immunity from future civil cases arising out of their widespread use of forged, fraudulent or completely fabricated documents to foreclose on homeowners.” and “As a result, the settlement will actually involve money flowing, once again, from taxpayers to the banks.”
- The recent so-called Task Force for investigating toxic mortgage practices: “it seems unlikely that an 11th-hour task force will result in a proliferation of handcuffs on culpable bankers.”
- The Dodd-Frank Bill: “…the market distortions that flow from the presumption of bailout may have gotten worse. By failing to alter this presumption, Dodd-Frank may have inadvertently sowed the seeds for the next financial crisis.”
- Specifically, the Volcker Rule, where he quotes a milquetoast Geithner: `“We’re going to look at all the concerns expressed by these rules,” he said. “It is my view that we have the capacity to address those concerns.”’ – Barofsky draws a line directly from Geithner to the conclusion of Senator Levin, `“Treasury are willing to weaken the law.”’ Barofsky here highlights out the most basic problem we face, namely that regulators are suckling from their Wall Street masters: “Indeed, words like Geithner’s, when accompanied by actions such as the Fed’s authorization of the largest banks to release capital, send what should be a clear message. We may be in danger of quickly returning to the pre-crisis status quo of inadequately capitalized banks that take outsized risks while being coddled by their over-accommodating regulators. A repeat of the financial crisis would soon be upon us.”
- Finally, he gets on my favorite riff about TARP, namely that it’s not about the money being paid back, it’s about the risk that we’ve taken on as a nation.
But what’s most interesting to me about the article is the fact that he’s not proposing a political solution to the unbelievably unbalanced distribution of resources. Probably this is because the political power is so firmly entrenched and because it is so firmly corrupt that there’s no use barking up that tree. Instead, he is asking for Occupy and other popular movements to step it up. The article ends:
The missteps by Treasury have produced a valuable byproduct: the widespread anger that may contain the only hope for meaningful reform. Americans should lose faith in their government. They should deplore the captured politicians and regulators who distributed tax dollars to the banks without insisting that they be accountable. The American people should be revolted by a financial system that rewards failure and protects those who drove it to the point of collapse and will undoubtedly do so again.
Only with this appropriate and justified rage can we hope for the type of reform that will one day break our system free from the corrupting grasp of the megabanks.
The question I have is, will we need yet another financial crisis to get this done? (Not that I think one is far off- the banning of short selling recently by Spain and Italy is a desperate move, kind of like throwing in the towel and admitting you’d rather openly manipulate markets than let people have honest opinions.)
I for one think we’ve got plenty of evidence right now, and I’m outraged. But maybe not everyone is, and I take responsibility for that.
I think my job now, as an Occupier, is to make sure people understand that these decisions and speeches made at the Treasury and the White House are directly related to people illegally losing their homes and jobs and town services and having their pensions rewritten after they’ve reached retirement age. I absolutely believe that, if people knew all of those connections, we’d have an enormous number of people ready to occupy and the political power to do something.
Tu-du leest bork bork
What with finishing a job up at the end of June, and then immediately going off to three weeks of math camp, I’ve put off lots of stuff around the house. My to-do list, just on household stuff alone, is getting kind of intimidating:
- Call Richard to get air conditioners installed
- Call insurance company about crazy bills
- Send care package to junior staff
- Deposit paycheck in bank
- Replace broken window shades
- Replace lightbulbs in bedroom
- Find babysitter for this Friday
- Find babysitter for early September
But I’ve figured out a way to avoid being too down about it. Namely, I just put it through the Swedish Chef Translator (if you can’t remember the Swedish Chef, check this out), and I’m good (borks added):
- Cell Reecherd tu get eur cundeeshuners instelled bork bork
- Cell insoorunce-a cumpuny ebuoot crezy beells bork bork
- Send cere-a peckege-a tu jooneeur steffff bork bork
- Depuseet peycheck in bunk bork bork
- Replece-a brukee veendoo shedes bork bork
- Replece-a leeghtboolbs in bedruum bork bork
- Feend bebyseetter fur thees Freedey bork bork
- Feend bebyseetter fur ierly September bork bork
Also available in Pig Latin to make me feel sneaky:
- allCay ichardRay otay etgay airway onditionerscay installedway
- allCay insuranceway ompanycay aboutway azycray illsbay
- endSay arecay ackagepay otay uniorjay affstay
- epositDay aycheckpay inway ankbay
- eplaceRay okenbray indowway adesshay
- eplaceRay ightbulbslay inway edroombay
- indFay abysitterbay orfay isthay idayFray
- indFay abysitterbay orfay earlyway eptemberSay
Exploit me some more please
I’m back home from HCSSiM (see my lecture notes here). Yesterday I took the bus from Amherst to New York and slept all the way, then got home and took a nap, and then after putting my 3-year-old to bed crashed on the couch until just now when I woke up. That’s about 13 hours of sleep in the past 20, and I’m planning to take a nap after writing this. That’s just an wee indication of how sleep deprived I became at math camp.
Add to that the fact that my bed there was hard plastic, that I completely lost touch with the memory of enjoying good food (taste buds? what are those?), and that I was pitifully underpaid, and you might think I’m glad to be home.
And I am, because I missed my family, but I’m already working feverishly to convince them to let me go again next year, and come with me next time if that would be better. Because I’m so in love with those kids and with those junior staff and with Kelly and with Hampshire College and with the whole entire program.
Just so you get an idea of what there is to love, check out one of the students talking about his plan for his yellow pig day shirt which I luckily captured on my phone:
And here’s a job description which always makes me laugh (and cry) (and I only worked there the first half):
When people haven’t experienced HCSSiM, we worry about being able to explain adequately the unusual commitment required by the exploitative position. The workday is long and challenging; it is also exciting and rewarding. A senior faculty and 2 junior faculty members actively participate in the morning classes (8:30 – 2:30, M-S) and evening problem sessions (7:30 – 10:30, M-F) of each of the c. 14-student Workshops (7/2 – 7/20 = days); they prepare (and duplicate) daily problem sets; they proofread notes and program journal articles, and they write evaluations; they offer constructive criticism; they attend the afternoon Prime Time Theorems (a 51-minute math-club type talk, over half given by visitors) and give 1 or 2. The staffing and most of those teaching opportunities (chores) apply to the 2nd half of the program when students take a Maxi-course (8:30-11, M-S, and 7:30 – 10:30, M-F, 7/23 – 8/10). During the 2nd half of the program, students also take, consecutively, 2 Mini-courses, which meet from 11:17 until 12:30 for 7 days and which have no attached problem sessions; many minis are created or co-created by junior staff. Except for Kelly and Susan (who are on call) the staff live in in the dorm (Enfield this year), join students for meals and recreational activities, provide transportation and counseling and supervision for students, and help to get the program to sleep around 11:17. There is virtually no hope of getting any research done or of maintaining an outside social life. In spite of (with some because of) the preceding, the job is exhilarating as well as exhausting; we have repeaters, and there are a lot of good math teachers out there who credit HCSSiM with teaching them to teach.
HCSSiM Workshop day 17
This is a continuation of this, where I take notes on my workshop at HCSSiM.
Magic Squares
First Elizabeth Campolongo talked about magic squares. First she exhibited a bunch, including these classic ones which I found here:

Then we noted that flipping or rotating a magic square gives you another one, and also that the trivial magic square with all “1”‘s should also count as a crappy kind of magic square.
Then, for 3-by-3 magic squares, Elizabeth showed that knowing 3 entries (say the lowest row) would give you everything. This is in part because if you add up all four “lines” going through the center, you get the center guy four times and everything else once, or in other words everything once and the center guy three times. But you can also add up all the horizontal lines to get everything once. The first sum is 4C, if C is the sum of any line, and the second sum is 3C, so subtracting we get that C is the the center three times, or the center is just C/3.
This means if you have the bottom row, you can also infer C and thus the center. Then once you have the bottom and the center you can infer the top, and then you can infer the two sides.
After convincing them of this, Elizabeth explained that the set of magic cubes was actually a vector space over the rational numbers, and since we’d exhibited 3 non-collinear ones and since we’d proved we can have at most 3 degrees of freedom for any magic square, we actually had a basis.
Finally, she showed them one of the “all prime magic squares”:
 The one with the “17” in the corner of course. She exhibited this as a sum of the basis we had written down. It was very cool.
The one with the “17” in the corner of course. She exhibited this as a sum of the basis we had written down. It was very cool.
The game of Set
My man Max Levit then whipped out some Set cards and showed people how to play (most of them already knew). After assigning numbers mod 3 to each of the 4 dimensions, he noted that taking any two cards, you’d be able to define the third card uniquely so that all three form a set. Moreover, that third card is just the negative of the sum of the first two, or in other words the sum of all three cards in a set is the vector
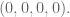
Next Max started talking about how many cards you can have where they don’t form a set. He started in the case where you have only two dimensions (but you’re still working mod 3). There are clearly at most 4, with a short pigeon hole argument, and he exhibited 4 that work.
He moved on to 3 and 4 dimensions and showed you could lay down 9 in 3 and 20 in 4 dimensions without forming a set (picture from here), which one of our students eagerly demonstrated with actual cards:

Finally, Max talked about creating magic squares with sets, tying together his awesome lecture with Elizabeth’s. A magic square of sets is also generated by 3 non-collinear cards, and you get the rest from those three placed anywhere away from a line:

Probability functions on lattices
Josh Vekhter then talked about probability distributions as functions from posets of “event spaces” to the real line. So if you role a 6-sided die, for example, you can think of the event “it’s a 3, 4, or 6” as being above the event “it’s a 3”. He talked about a lattice as a poset where there’s always an “or” and an “and”, so there’s always a common ancestor and child for any two elements.
Then he talked about the question of whether that probability function distributes in the way it “should” with respect to “and” and “or”, and explained how it doesn’t in the case of the two slit experiment.
He related this lack of distribution law of the probability function to the concept of the convexity of the space of probability distributions (keeping in mind that we actually have a vector space of possibly probability functions on a given lattice, can we find “pure” probability distributions that always take the values of 0 or 1 and which form a kind of basis for the entire set?).
This is not my expertise and hopefully Josh will fill in some details in the coming days.
King Chicken
I took over here at the end and discussed some beautiful problems related to flocks of chickens and pecking orders, which can be found in this paper. It was particularly poignant for me to talk about this because my first exposure to these problems was my entrance exam to get into this math program in 1987, when I was 14.
Notetaking algorithm
Finally, I proved that the notetaking algorithm we started the workshop with 3 weeks before actually always works. I did this by first remarking that, as long as it really was a function from the people to the numbers, i.e. it never gets stuck in an infinite loop, then it’s a bijection for sure because it has an inverse.
To show you don’t get stuck in an infinite loop, consider it as a directed graph instead of an undirected graph, in which case you put down arrows on all the columns (and all the segments of columns) from the names to the numbers, since you always go down when you’re on a column.
For the pipes between columns, you can actually squint really hard and realize there are two directed arrows there, one from the top left to the lower right and the other from the top right to the lower left. You’ve now replaces the “T” connections with directed arrows, and if you do this to every pipe you’ve removed all of the “T” connections altogether. It now looks like a bowl of yummy spaghetti.
But that means there is no chance to fall into an infinite loop, since that would require a vertex. Note that after doing this you do get lots of spaghetti circles falling out of your diagram.
HCSSiM Workshop day 16
This is a continuation of this, where I take notes on my workshop at HCSSiM.
Two days ago Benji Fisher came to my workshop to talk about group laws on rational points of weird things in the plane. Here are his notes.
Degenerate Elliptic Curves in the plane
Conics in the plane
Pick 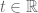




Substitute 

After you do it the hard way, notice that you already know one root: 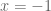
The sum of the roots is 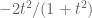

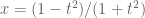
From 

Do not forget that if you are given 

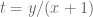
This gives you a 1-1 correspondence between the points of the circle (conic) and the points of the 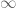
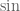



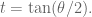
There are several ways you can generalize this. You could project a sphere onto a plane. I want to consider replacing the circle with a cubic curve. The problem is that the expected number of intersections between a line and a cubic is 3, so you get a 2-to-1 correspondence in general. That is interesting, too, but for now I want to consider the cases where the curve has a double point and I choose lines through that point. Such lines should intersect the cube in one other point, giving a 1-1 correspondence between the curve (minus the singular point) and a line (minus a small number of points).
cubic with a cusp
Let 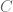

which has a sharp corner at the origin. This type of singularity is called a cusp. Let 


- Sketch the curve
- The line
. Find formulae for
- You almost get a digestion (bijection) between
. What points do you have to omit from each in order to get a digestion?
- Three points
, and
on
The calculations are easier than for the circle: 

You have to remove the point 

The condition for colliniarity is

Plug in the expressions in terms of the

If we let 



cubic with a node
This problem deals with the curve

which intersects itself at the origin. This type of singularity is called a node. Let

- Sketch the curve
- The line
). Find formulae for
- You almost get a digestion (bijection) between
- Three points
Once again, 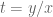

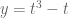


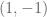
The lines through the origin with slope 
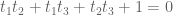
Remember our curve 
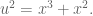

Claim: in terms of 

(Hint: In terms of 
If you start with the known equation and replace the 
If you start with the LHS of the desired equation, there is a shortcut:

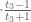
But then we have
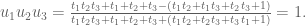
Note that the change-of-variable formulae are fractional linear transformations. Geometrically, 
To get from one line to the other, just draw a line through the origin.
One interpretation of our results for the curves 

In other words, we are allowed to draw vertical lines. I will continue to refer to this as “straightedge only.” I forgot to mention: you need to have the curve provided as well. Explicitly, this is the rule. Given two points on the line, find the corresponding point on the curve. Draw a line through them. The third point of intersection with the curve will be the (additive or multiplicative) inverse of the desired sum. Draw a vertical line through this point: the second point of intersection (or the third, if you count the point at infinity as being the second) will be the desired sum/product.
More precisely, it is the point on the curve corresponding to the desired sum/product, so you have to draw one more line.
Another interpretation is that we get a troupe (or karafiol) structure on the points of the curve, excluding the singular point but including the point at infinity. The point at infinity is the identity element of the troupe (group). The construction is exactly the same as in the previous paragraph, except you leave off the parts about starting and ending on the line.

smooth cubic
Similarly, we get a troupe (group) structure on any smooth cubic curve. For example, consider the curve 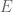
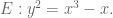
Start with two points on the curve, say 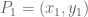


Solving for 
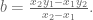
Plug this into the equation defining 
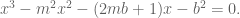
Luckily, we know how to solve the general cubic. (Just kidding! Coming back to what we did with the circle, we observe that 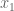
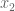


The result is:
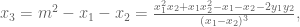
where the final form comes from squaring 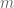
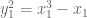

At this point, a little patience (or a little computer-aided algebra) gives

Do not forget the final step: 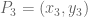
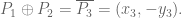

Now, I give up. With a lot of machinery, I could exlpain why the group law is associative. (The identity, as I think I said above, is the point at infinity. Commutativity and inverses are clear.) What I can do with a different machine (Mathematica or some other computer-algebra system) is verify the associative law. I could also do it by hand, given a week, but I do not think I would learn anything from that exercise.
Some content on this page was disabled on December 15, 2019.
HCSSiM Workshop day 15
This is a continuation of this, where I take notes on my workshop at HCSSiM.
Aaron was visiting my class yesterday and talked about Sandpiles. Here are his notes:
Sandpiles: what they are
For fixed 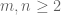
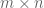

Do stable
Answer: well, you can add them together (pointwise) and then let that stabilize until you’ve got back to a stable beach (not trivial to prove this always settles! But it does). But is the sum well-defined?
In other words, if there is a cascade of toppling, does it matter what order things topple? Will you always reach the same stable beach regardless of how you topple?
Turns out the answer is yes, if you think about these grids as huge vectors and toppling as adding other 2-dimensional vectors with a ‘-4’ in one spot, a ‘1’ in each of the four spots neighboring that, and ‘0’ elsewhere. It inherits commutativity from addition in the integers.
Wait! Is there an identity? Yep, the beach with no sand; it doesn’t change anything when you add it.
Wait!! Are there inverses? Hmmmmm….
Lemma: There is no way to get back to all 0’s from any beach that has sand.
Proof. Imagine you could. Then the last topple would have to end up with no sand. But every topple adds sand to at least 2 sites (4 if the toppling happens in the center, 3 if on an edge, 2 if on a corner). Equivalently, nothing will topple unless there are at least 4 grains of sand total, and toppling never loses more than 2 grains, so you can never get down to 0.
Conclusion: there are no inverses; you cannot get back to the ‘0’ grid from anywhere. So it’s not a group.
Try again
Question: Are there beaches that you can get back to by adding sand?
There are: on a 2-by-2 beach, the ‘2’ grid (which means a 2 in every spot) plus itself is the ‘4’ grid, and that topples back to the ‘2’ grid if you topple every spot once. Also, the ‘2’ grid adds to the 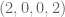
Wow, it seems like the ‘2’ grid is some kind of additive identity, at least for these two elements. But note that the ‘1’ grid plus the ‘2’ grid is the ‘3’ grid, which doesn’t topple back to the ‘1’ grid. So the ‘2’ grid doesn’t work as an identity for everything.
We need another definition.
Recurrent sandpiles
A stable beach C is recurrent if (i) it is stable, and (ii) given any beach A, there is a beach B such that C is the stabilization of A+B. We just write this C = A+B but we know that’s kind of cheating.
Alternative definition: a stable beach C is recurrent if (i) it is stable, and (ii) you can get to C by starting at the maximum ‘3’ grid, adding sand (call that part D), and toppling until you get something stable. C = ‘3’ + D.
It’s not hard to show these definitions are equivalent: if you have the first, let A = ‘3’. If you have the second, and if A is stable, write A + A’ = ‘3’, and we have B = A’ + D. Then convince yourself A doesn’t need to be stable.
Letting A=C we get a beach E so C = C+E, and E looks like an identity.
It turns out that if you have two recurrent beaches, then if you can get back to one using a beach E then you can get back to to the other using that same beach E (if you look for the identity for C + D, note that (C+D)+E = (C+E) + D = C+D; all recurrent beaches are of the form C+D so we’re done). Then that E is an identity element under beach addition for recurrent beaches.
Is the identity recurrent? Yes it is (why? this is hard and we won’t prove it). So you can also get from A to the identity, meaning there are inverses.
The recurrent beaches form a group!
What is the identity element? On a 2-by-2 beach it is the ‘2’ grid. The fact that it didn’t act as an identity on the ‘1’ grid was caused by the fact that the ‘1’ grid isn’t itself recurrent so isn’t considered to be inside this group.
Try to guess what it is on a 2-by-3 beach. Were you right? What is the order of the ‘2’ grid as a 2-by-3 beach?
Try to guess what the identity looks like on a 198-by-198 beach. Were you right? Here’s a picture of that:

We looked at some identities on other grids, and we watched an app generate one. You can play with this yourself. (Insert link).
The group of recurrent beaches is called the m-by-n sandpile group. I wanted to show it to the kids because I think it is a super cool example of a finite commutative group where it is hard to know what the identity element looks like.
You can do all sorts of weird things with sandpiles, like adding grains of sand randomly and seeing what happens. You can even model avalanches with this. There’s a sandpile applet you can go to and play with.
HCSSiM Workshop, day 14
This is a continuation of this, where I take notes on my workshop at HCSSiM.
We switched it up a bit and I went to talk about Rubik’s Cubes in Benji Fisher’s classroom whilst Aaron Abrams taught in mine and Benji taught in Aaron’s. We did this so we could meet each other’s classes and because we each had a presentation that we thought all the classes might want to see.
In my class, besides what Aaron talked about (which I hope to blog about tomorrow), we talked about representing groups with generators and relations and we looked at how to create fractals on the complex plane using Mathematica.
Solving the Rubik’s Cube with group theory

First I talked about the position game, so ignoring orientation of the pieces. In other words, if all the pieces are in the correct position but are twisted or flipped, that’s ok.
Consider the group acting on the set which is the Rubik’s cube. We can fix the centers, and then this group is clearly generated by 90 degree clockwise turns on each of the 6 faces (clockwise when you look straight at the center of the face). It has a bunch of relations too, of course, including (for example) that the “front” move commutes with the “back” move and that any of these generators is trivial if you do it 4 times in a row.
Next we noted that the 8 corners always move to other corners on any of these moves, and that the 12 edges always move to edges. So we could further divide the “positions game” into an “edges game” and a “corners game.” Furthermore, because of this separation, any action can be realized as an element of the group
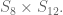
But there’s more: any one of these generators is a 4-cycle on both edges and corners, which is odd in both cases, so so is a product of the generators. This means the group action actually lands inside
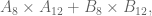
where I denote by 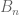
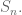
Next I stated and proved that the 3-cycles generate 
The reason that’s interesting is that, once I show that I can act by arbitrary 3-cycles on the edges or corners, this means I get that entire group up there of the form (even, even) or (odd, odd).
Next I demonstrated a 3-cycle on three “bad pieces” where one needs to go into the position of one of the other two. Namely:
- Put two “bad” pieces on the top and one below, including the piece which is the destination of the third.
- Do some move U which moves the third bad piece below to its position on the top without changing anything else.
- Move the top so you decoy the new piece with the other bad piece on top. Call this decoy move V.
- Undo the U move.
- Undo the V move.
Seen from the perspective of the top, all that happens is that suddenly it has one piece in the right place (after U), then it gets rid of a piece it didn’t want anyway. From the perspective of the bottom, it sent up a piece it didn’t want to the top, then unmessed itself by taking back another piece from the top.
That’s a 3-cycle on the pieces, on the one hand (and a commutator on the basic moves), and we can perform it on any three corners or edges by first performing some move to get 2 out of the 3 pieces on the same face and the third not on that face. This is essentially acting by conjugation (and it’s still a commutator).
Moreover, the overall effect on the puzzle is that it took 3 pieces that were messed up and got at least 1 in the right spot.
The overall plan now is that you solve the corners puzzle, then the edges puzzle, and you’re done. Specifically, I get to the (even, even) situation by turning one face once if necessary, and then I can perform arbitrary 3-cycles to solve my problem. If I have fewer than three messed up corners (resp. edges), then I have either 0, 1, or 2 messed up corners (resp. edges). But I can’t have exactly 1, and exactly 2 would be odd, so I have 0.
That’s the position game, and I’ve given an algorithm to solve it (albeit not efficient!).
What about the orientations?
Shade the left and right side of a solved cube. Both the position (cubicle) and the piece of plastic (cubie) can be considered as shaded. Also shade a strip on the front and on the back, so we get the top and bottom edge of the front and back shaded.
Convince yourself that every edge and every corner position has exactly one shaded face.
When the cube is messed up, the shaded face of the position may not coincide with the shaded face of the cubie in that position. For edges it’s either right or wrong – assign each a value of 0 (if it’s right) or 1 (if it’s wrong). These can be considered orientation values modulo 2.
For corners, it can be wrong in two ways. The cubie’s shaded face could coincide with the position’s shaded face (give it a value 0), or it could be clockwise 120 degrees (value 1), or counterclockwise 120 degrees (value -1). These numbers are modulo 3.
Next, convince yourself that all of the generators of the group of actions on the rubik’s cube preserve the fact that the sum of the orientation numbers is 0, considered either mod 3 for the corners or mod 2 for the edges.
In particular, this means we can’t have exactly one edge flipped but everything in the right position. If you see this on a Rubik’s cube then someone took it apart and put it back together wrong.
However, you can twist one corner clockwise and another one counterclockwise, which means you can get any configuration of orientation numbers on the corners that satisfy that their sum is 0. Same with edges – it’s possible to flip two.
Finally, I exhibit how to do each of these basic orientation moves by 2 3-cycles. First I choose a pivot corner and perform a 3-cycle on those three corners, and then I do another 3-cycle, which uses the same 3 corners but is slightly different and results in everything being back in the right position but two corners twisted. I can do the same thing for edges, and I have thus totally solved the cube.
This method of 3-cycles is slow but it generalizes to all Rubik’s puzzles, so for example the 7 by 7 cube:

Or, with some work, something else like this:

p.s. I learned all of this when I was 15 from Mike Reid at HCSSiM 1987.
p.p.s. This was what we ate after singing our Yellow Pig Carols last night:

HCSSiM Workshop, day 13
This is a continuation of this, where I take notes on my workshop at HCSSiM.
Permutation notation
Using a tetrahedron as inspiration, we found the group of rotational symmetries as a subgroup of the permutation group 
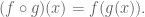
Quadratic Reciprocity
Today we proved quadratic reciprocity, which totally rocks. In order to get there we needed three lemmas, which were essentially a bunch of different formulas for computing the Jacobi symbol.
The first was that, modulo 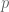
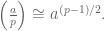
The second one was that we could write 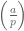



In the third one we assume 

![\left[ \frac{a j}{p} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cfrac%7Ba+j%7D%7Bp%7D+%5Cright%5D&bg=ffffff&fg=555555&s=0&c=20201002)

Each of these lemmas, in other words, gave us different ways to compute the symbol
The first one uses the fact that if 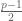
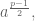
The second one just uses the fact that, ignoring negative signs, 
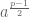

The third lemma follows from repeatedly applying the division algorithm to 
![\displaystyle{a j = p \cdot \left[\frac{aj}{p} \right] + r_j}](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle%7Ba+j+%3D+p+%5Ccdot+%5Cleft%5B%5Cfrac%7Baj%7D%7Bp%7D+%5Cright%5D+%2B+r_j%7D&bg=ffffff&fg=555555&s=0&c=20201002)
for all 

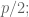
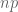

![a (1 + 2 + \dots + \frac{p-1}{2}) = \left( \left[\frac{a}{p} \right] + \left[\frac{2a}{p} \right]+ \dots + \left[\frac{\frac{p-1}{2} a}{p} \right] \right) p + s_1 + s_2 + \dots + s_{\frac{p-1}{2}} + n \cdot p.](https://s0.wp.com/latex.php?latex=a+%281+%2B+2+%2B+%5Cdots+%2B+%5Cfrac%7Bp-1%7D%7B2%7D%29+%3D+%5Cleft%28+%5Cleft%5B%5Cfrac%7Ba%7D%7Bp%7D+%5Cright%5D+%2B+%5Cleft%5B%5Cfrac%7B2a%7D%7Bp%7D+%5Cright%5D%2B+%5Cdots+%2B+%5Cleft%5B%5Cfrac%7B%5Cfrac%7Bp-1%7D%7B2%7D+a%7D%7Bp%7D+%5Cright%5D+%5Cright%29+p+%2B+s_1+%2B+s_2+%2B+%5Cdots+%2B+s_%7B%5Cfrac%7Bp-1%7D%7B2%7D%7D+%2B+n+%5Ccdot+p.&bg=ffffff&fg=555555&s=0&c=20201002)
Since
![1 + 2 + \dots + \frac{p-1}{2} = \left[\frac{a}{p} \right] + \left[\frac{2a}{p} \right]+ \dots + \left[\frac{\frac{p-1}{2} a}{p} \right] + s_1 + s_2 + \dots + s_{\frac{p-1}{2}} + n.](https://s0.wp.com/latex.php?latex=1+%2B+2+%2B+%5Cdots+%2B+%5Cfrac%7Bp-1%7D%7B2%7D+%3D+%5Cleft%5B%5Cfrac%7Ba%7D%7Bp%7D+%5Cright%5D+%2B+%5Cleft%5B%5Cfrac%7B2a%7D%7Bp%7D+%5Cright%5D%2B+%5Cdots+%2B+%5Cleft%5B%5Cfrac%7B%5Cfrac%7Bp-1%7D%7B2%7D+a%7D%7Bp%7D+%5Cright%5D+%2B+s_1+%2B+s_2+%2B+%5Cdots+%2B+s_%7B%5Cfrac%7Bp-1%7D%7B2%7D%7D+%2B+n.&bg=ffffff&fg=555555&s=0&c=20201002)
Up to signs, 
Incidentally, using the formula above (before we ignore
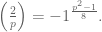
Finally, we show that the sum ![\left[\frac{a}{p} \right] + \left[\frac{2a}{p} \right]+ \dots + \left[\frac{\frac{p-1}{2} a}{p} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cfrac%7Ba%7D%7Bp%7D+%5Cright%5D+%2B+%5Cleft%5B%5Cfrac%7B2a%7D%7Bp%7D+%5Cright%5D%2B+%5Cdots+%2B+%5Cleft%5B%5Cfrac%7B%5Cfrac%7Bp-1%7D%7B2%7D+a%7D%7Bp%7D+%5Cright%5D&bg=ffffff&fg=555555&s=0&c=20201002)


But, letting 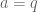
![\left[\frac{p}{q} \right] + \left[\frac{2p}{q} \right]+ \dots + \left[\frac{\frac{q-1}{2} p}{q} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B%5Cfrac%7Bp%7D%7Bq%7D+%5Cright%5D+%2B+%5Cleft%5B%5Cfrac%7B2p%7D%7Bq%7D+%5Cright%5D%2B+%5Cdots+%2B+%5Cleft%5B%5Cfrac%7B%5Cfrac%7Bq-1%7D%7B2%7D+p%7D%7Bq%7D+%5Cright%5D&bg=ffffff&fg=555555&s=0&c=20201002)

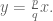
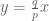

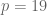
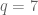
 Therefore we’ve proved:
Therefore we’ve proved:

Alternating Group
We introduced cyclic notation, showing everything is a product of transpositions, then we introduced the sign function and showed that 
Transformation of the Plane
We discussed rotations, shears, shrinks, reflections, and translations of the plane and demonstrated them in Mathematica using this.
Yellow Pig Carols
Tomorrow is Yellow Pig Day, which is a yearly tradition here at HCSSiM during which we celebrate our mascot the yellow pig and our favorite number, 17.

In particular, there will be an hour and a half lecture during which we will hear many surprising and elegant 17 facts (examples: the longest time anybody has ever sat in a tub of ketchup? 17 hours. The average adolescent male has a sexually related thought how often? Every 17 seconds).
Some time after the 17 lecture we get together to sing Yellow Pig Carols. These are usually set to the tune of some song, with the lyrics changed to refer to math, in particular the number 17, and yellow pigs, Weird Al Yankovic- style. Check out this list for a taste.
But there’s a problem, which is that the songs are really old and many of the tunes are unknown to this crop of kids. In desperate need of a revamp, I got my workshop to write a new song, which I’m super proud of. We started out by voting on a song (winner: Somewhere Over the Rainbow) for which we wrote new lyrics. Here they are:
Some July Seventeenth
Some july seventeenth
when pigs fly
we’ll see patches of yellow
scattered across the sky
Some “f” over the reals
satisfy
f of x plus f of y
is f-of-x plus y
someday I’ll find another g
besides f of t is k t or zer-o
and then I will compose the two
and get solutions that are new
they’ll appear-o
Some groups they are abelian
they commute
but some have commutators
whose actions are not moot
The action on the complex plane
by matrices is so in-sanely dum-ber
than even that of conjugation
whose equivalence relation pairs the num-bers
Some july seventeenth
when pigs fly
we’ll see patches of yellow
scattered across the sky
Honestly I thought it would stop there, but people around here have been on a tear. My hilarious junior staff Maxwell Levit has written a brilliant song based on Gotye’s “Somebody I Used to Know”. If you haven’t been living under a rock, you will have heard that song (and if you haven’t heard that song, please go ahead and do so now), about a guy wondering why this woman has left him and won’t talk to him, and then she comes in and tells her story which is how much of a manipulative creep he really was. There’s a dramatic video featuring nakedness and body paint which adds to the drama and to the song.
Well Max just turned that shit around and now it’s Fermat singing to Fermat’s Last Theorem, wondering where he went wrong, and then the theorem talks back and tells us the real deal. Plus he uses the word “marginalia,” which is in itself awesome. Here it is:
A Theorem that I used to know
(Fermat)
Now and then I think of Diophantine equations
Like how Pythagoras showed the case for n=2
Told myself that I understood,
And didn’t write down what I thought I would
Remember when I looked back at my marginalia
You can get addicted to a certain type of hubris
Assuming you don’t need to use elliptic curves
So when I found my proof did not make sense,
I knew it wasn’t my incompetence
But I’ll admit I was confused to say the least.
But you didn’t have to be so hard,
Make out like my intuitive method was for nothing
I don’t even need to know
But they treat you like Wiles solved you and that feels so rough
No you didn’t have to stoop so low
Elliptic curves and modular forms lack in imagination
I guess I don’t need you though,
Now you’re just some theorem that I used to know.
Now you’re just some theorem that I used to know.
Now you’re just some theorem that I used to know.
(theorem)
Now and then I think of when you said you’d solved me.
Part of me believing I had some marvelous proof.
But I don’t really work that way.
Adhering to everything you say.
You said that you could let it go,
And you shouldn’t get too hung up on a theorem that you used to know!
(Fermat)
But you didn’t have to be so hard,
Make out like my intuitive method was for nothing
I don’t even need to know
But they treat you like Wiles solved you and that feels so rough
No you didn’t have to stoop so low
Elliptic curves and modular forms lack in imagination
I don’t even need you though,
Now you’re just some theorem that I used to know.
[x2]
Some Theorem!
(I used to know)
Some Theorem!
(Now you’re just some theorem that I used to know)
(I used to know)
(That I used to know)
(I used to know)
Some Theorem!
We’re gonna make Devin Ivy, a fantastically funny junior staff here as well as a photographer, play Gotye/ Fermat in the video, with yellow pigs getting continually plastered all over his body. He’s Gotye’s spitting image:

HCSSiM Workshop, day 12
This is a continuation of this, where I take notes on my workshop at HCSSiM.
We originally defined ![\mathbb{R}[x]/(x^2+1),](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BR%7D%5Bx%5D%2F%28x%5E2%2B1%29%2C&bg=ffffff&fg=555555&s=0&c=20201002)


After we reminded people about matrix addition and multiplication, we showed this was an injective homomorphism under addition and also jived with the multiplication that we knew coming from 
Then we talked about actions on the plane including translations and scaling and showed that under the above map, “multiplication by 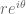
Platonic Solids
We went over the 5 platonic solids from yesterday- we’d proved it was impossible to have more than 5, and now it was time to show all 5 are actually possible! That’s when we whipped out Wayne Daniel’s “all five” puzzle:

We then introduced the concept of dual graph, and showed which platonic solids go to which under this map. We saw an example of a toy which flips from one platonic solid (cube) to its dual (octahedron) when you toss it in the air, the Hoberman Flip Out.

Here is it in between states:

Finally, we talked about symmetries of regular polyhedra and saw how we could embed an action into the group of symmetries on its vertices. So symmetries on tetrahedra is a subgroup of 
Then one of our students, Milo, showed us how he projected a tiling of the plane onto the surface of a sphere using the language “processing“. Unbelievable.
After that we went to an origami workshop to construct yellow pigs as well as platonic solid type structures.
HCSSiM Workshop, day 11
This is a continuation of this, where I take notes on my workshop at HCSSiM.
Lagrange
We reminded people that a finite group is a finite set with an associative multiplication law “*”, and an identity and inverses with respect that law. A subgroup is a subset which is a group in its own right with the same multiplication law. Given a subgroup 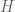
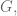

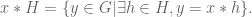
We proved that “being in the same coset as” is an equivalence relation and that each coset has the same size. Altogether the cosets form a partition of the group, so the size of the group is the product of the size of any coset and the number of cosets.
One of the students decided that you could form a group law on the set of cosets, inheriting the multiplication operation from 
Primitive Roots modulo p
Next we spent more time than you’d think proving there’s a nonzero number 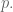
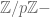

The left group is a group under multiplication, and the right one is a group under addition, which means this can be seen as a kind of logarithm in finite groups. Indeed an element 
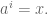
To prove such an 

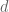
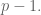
To do that, we have a few lemmas. First, that there are at most 
Next we proved that there are at most 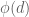


Finally, we wrote out boxes labeled with the divisors of 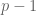
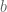
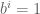
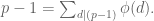
Platonic Solids
Riffing on our proof of Euler’s formula for planar graphs, we convinced the kids that we could just as well consider a graph to be on a sphere, using a stereographic projection.

Then, using graphs on spheres as guides, we looked at how many examples we could come up with for a regular polytope, where each face has the same number of edges and each vertex has the same number of edges leaving it. We came up with the five platonic solids.

It rocks to be 40
So it’s my birthday today, I’m finally 40. I’m enjoying it so much I started calling myself 40 like four months ago because I couldn’t wait.

I’m not exactly sure why it is so meaningful to me, this number. You might think I’m enough of a rebel to just not care at all about a number like this, even though it is certainly culturally significant. But here’s the thing, I’m owning it.
Since I’m an alpha female, being 40 frees me up quite a bit. I don’t have to even imagine not being taken seriously or being thought of as too young or inexperienced to have an opinion. I have no urge to be cute or play dumb. Leave that to younger people, it wouldn’t work for me anymore anyhow.
My dad used to tell me to try to be “more demure” so that people wouldn’t be put off by me. Worst advice ever. I definitely have gotten more out of my life by being completely honest and upfront than by playing a synthetic role. It also wastes less time for everyone. At this point I’m able to look over my experiences and know things like that rock-solid, and not second guess myself. That’s a good feeling.
You know what rocks about being 40? It comes down to this: I am old enough to know the difference between bullshit and the good stuff and I’m still feeling healthy and fully capable of enjoying the good stuff. It is seriously freeing, and I’m looking forward to everything about it. And I say this basically unemployed and not knowing what I’m doing next, which for some reason gives rise to the most freeing moments for me.
Presents I don’t want for my 40th birthday:
- hair dye. I’m letting myself go grey, it’s gorgeous IMHO.
- anti-wrinkle cream. Screw that.
- girdles. I’ve already complained about that.
Presents I might want for my 40th birthday:
- a night out on the town ending with karaoke is always nice.
- puzzles and games. I’ve always love playing with puzzles. Crosswords too.
- time with the many people I love. That’s the best part.
Let’s do this, people! Fuck yeah!!




{kind=link}