Archive
Econned and Magnetar
Gaming the risk model
When I worked in finance, there was a pretty well-known (and well-used) method of working around the pesky requirements of having a risk model and paying attention to risk limits in your group.
Namely, you’d let a risk guy in the group for a while, long enough to write a half-decent risk model, and then you’d say thanks, and we don’t need you anymore we’ll run with this, and then you’d kick him out of the group. You’d then spend the next few years learning how to game the risk model.
In particular you’d know exactly what kind of trades you could put in that the risk model can’t “see”: things like interest rate risk or counterparty risk, that the poor risk guy didn’t think of at the time, or even better the market you trade in would have developed and changed in the last few years so you were applying the risk model to instruments it wasn’t even meant to measure.
That way you could always stay within your risk limits, as a group, even while you took larger and larger bets on things that were invisible to the risk model. As long as the world didn’t blow up, this method returned higher-than-expected profits, so your “Sharpe ratio” looked great. You got rewarded for this, and in the meantime the company you worked for took on the risk (and they typically didn’t see it as coming from your trading group but rather as some amorphous systemic risk). It’s not clear how many people how high up were in on this method, but it seemed pretty clear that they also enjoyed the ride as long as it lasted.
The CDO market
One really enormous and tragic example of this behavior is described in Yves Smith‘s brilliant book Econned, in the chapter describing the CDO market and Magnetar Capital‘s involvement.
CDOs were the reason we had a global economic crisis and not just a housing bubble. The CDO market is complicated, and you can learn a lot about it by reading the book. Suffice it to say I’m not going to be able to explain the whole thing, but let me simplify the story thus.
At the beginning (late 1980s through mid-late 1990s) there were not that many securitizations outside of the federal arena (Freddie Mac, Fannie Mae, and FHA), and they were pretty useful because they made piles of riskier but still viable-looking mortgages more predictable than individual mortgages. The top of the pile (they were separated in to groups called “tranches” depending on possible defaulting actions) were rated AAA by the big three ratings agencies (Moody’s, Fitch, and S&P) and probably deserved it, because they had a big cushion of loss protection beneath them. The lower tranches were lower rated and harder to sell, which limited the size of the overall market.
Starting around 2003 the lower-rated, harder-to-sell tranches from the BBB to the junior AAA tranche started getting resecuritized into instruments called CDOs. In fact there were riskier CDOs, called mezzanine CDOs, which consisted mainly of the BBB tranches, and “high grade” CDOs consisting mostly of old A and AA tranches. These CDOs were again tranched, with around 75% of the par value getting an AAA rating.
Yes, you heard that right: if you took a bunch of easy-to-imagine-they’d-fail low rated mortgage bond tranches (especially if you knew anything about the terms of those mortgages and how much they were counting on the housing market to continue its climb), and bundle them together, then the resulting package would, at its highest tranche, be deemed AAA. It made no sense then and it makes no sense now.
The CDS and synthetic CDO markets
Enter the credit default swaps market. The ability to buy CDS protection (insurance on the underlying bonds) on a higher tranche of the mortgage bonds (the first generation securitization) while purchasing a lower tranche made it possible for lots of people to bet that “if things go bad, they will go really bad”, while limiting their overall exposure. Moreover, the income on the lower rated tranche would fund an even bigger short position on the higher rated tranche, so this was a self-financing bet.
The demand for more cheap credit default swaps led some clever traders to realize they could create CDOs largely or entirely from credit default swaps rather than actual bonds. No need to be constrained by finding real borrowers! And you could bet against the same crap BBB bonds again and again, and have them packaged up and have most of the value of the “synthetic” or “hybrid” CDO rated AAA (again with the collusive help of the ratings agencies).
At first, the big protection sellers in the CDS market was AIG and the monoline insurers. But they only wrote CDSs on the least risky AAA CDO tranches. Later, after AIG stopped being involved, that side of the CDS market was entered into by all sorts of really dumb people, with the help from the complicit ratings agencies who kept awarding AAA ratings.
Even so, there was still a bottleneck for this re-rebundled synthetic/heavily synthetic CDO market. Namely, it was hard to find people to buy the so-called “equity tranche”, which was the tranche that would disappear first, as the first crop of the underlying loans defaulted.
Magnetar
That’s when Magnetar Capital came in. They set up deals to fail. They did this through explicitly designing the synthetic CDOs (banks gave this privelege to whomever was willing to buy the equity tranche) and by, in addition to buying the equity tranche, they bought up all of the CDS’s in the synthetic CDO.
The overall bet Magnetar Capital was taking was similar to the one above: when the market goes bad, it will go really bad. The difference is that Magnetar’s exposure was altogether very short: they set up the equity tranche to pay lots of cash in the short term (a couple of years), which would finance the cost of all of the CDSs in the hybrid CDO, which meant they didn’t just cover the exposure but magnified it multiple times. And it was again a self-financing bet, as long as they were right about the market exploding rather than slowly degrading.
How big was this? Magnetar Capital made the majority of the market in 2006, which was one of the biggest years in this market. And everything they did was legal. They also drove demand in the subprime mortgage market, during its most toxic phase, by dint of a combination of leverage and the clever manipulation of investors, specifically convincing them to post cash bonds.
WTF?
Let’s go back to the groups gaming their risk models from the beginning of this post. Same thing happened here, except the group was this entire market, and the risk guy was the combination of the ratings agencies and AIG, as well as the greedy fools who wrote CDS on mortgages in 2006. And instead of the hedge fund being on the hook for their trading group’s games, in this case it was the United States and various European governments who were on the hook.
How predictable was this whole scheme? My guess is that Goldman Sachs knew exactly what was happening and what was going to happen. They made a very intelligent bet that if and when the housing market went under, AIG would be backed by the government. In essence this entire market was an enormous bet on government bailout. Not everyone knew, of course, especially the guys who were long the market when it collapsed, but lots of people knew. The same people who right now know where the dead bodies are on the books and who aren’t coming forward with a plan to resuscitate the financial system, in fact.
At the very least I think this story argues for the treatment of CDS as insurance, with the requisite regulation. In different terms, Magnetar chose buildings where they saw arsonists enter with gallons of gasoline and matches, and bet everything on a fire in that building. The question then is, how many fire insurance claims should one entity be allowed to buy for one building?
Freddie Mac: worse than hedge funds?
Check out this outrageous article about what Freddie Mac has been doing. Seriously makes my blood boil!!
Update: Yves Smith on Naked Capitalism posted this morning about how this is maybe not such a big deal.
Medical identifiers
In this recent article in the Wall Street Journal, we are presented with two sides of a debate on whether there should be a unique medical identifier given to each patient in the U.S. healthcare system.
Both sides agree that this would help record keeping problems so much (compared to the shambles that exist today) that it would vastly improve scientists’ ability to understand and predict disease. But the personal privacy issues are sufficiently worrying for some people to conclude that the benefits do not outweigh the risks.
Once it’s really easy to track people and their medical data through the system, the data can and will be exploited for commercial purposes or worse (imagine your potential employer looking up your entire medical record in addition to your prison record and credit score).
I agree with both sides, if that’s possible, although they both have flaws: the pro-identifier trivializes the problems of computer security, and the anti-identifier trivializes the field of data anonymization. It’s just incredibly frustrating that we haven’t been able to come to some reasonable solution to this that protects individual identities while letting the record keeping become digitized and reasonable.
Done well, a functional system would have the potential to save people’s lives in the millions while not exposing vulnerable people to more discrimination and suffering. Done poorly and without serious thought, we could easily have the worst of all worlds, where corporations have all the data they can pay for and where only rich people have the ability or influence to opt out of the system.
Let’s get it together, people! We need scientists and lawyers and privacy experts and ethicists and data nerds to get together and find some intelligently thought-out middle ground.
Complexity and transparency in finance
The blog interfluidity, written by Steve Randy Waldman, posted a while back on opacity and complexity in the financial system, arguing that it is opacity and the resulting lack of understanding of risk that makes the financial system work.
Although I like a lot of what this guy writes, I don’t agree with his logic. First, he uses the idea of equilibrium from economics, which I simply don’t trust, and second, his basic assumption is that people need to not have complete information to be optimistic. But that’s simply not true: people are known to be optimistic about things that have complete clarity, like the lottery. In other words, it’s not opacity that makes finance work, it’s human nature, and we don’t need any fancy math to explain that.
Partly in response to this idea, I wrote this post on how people in the financial system make money from information they know but you don’t.
But then Steve wrote a follow-up post which I really enjoy and has a lot of interesting ideas, and I want to address some of them today. Again he assumes that we don’t want a transparent financial system because it would prevent people from buying in to it. I’d just like to argue a bit more against this before going on.
In a p.s. to the follow-up post Steve defines transparency in terms of risks. But as anyone knows who has worked in finance, transparency is broadly understood to mean that the data is available. This could be data about who bought what for how much money, or it could refer to the data of which mortgages are bundled in which CDO’s, and whose houses those refer to and what is the credit score of the mortgagees, or all of the above. Let’s just say all of the above, say we have all the data we could legally ask for about everything on the market.
That’s still not a risk model. In fact, making good risk models from so much data is really hard, and is partly why the ratings agencies existed, so that people could outsource this work. Of course it turns out those guys sucked at it too.
My point is this: a transparent system is at best a system that gives you the raw ingredients to allow you to cook up some risk soup, but it’s left up to you to do so. Every person does this differently, and most people are optimistic about both the measurement of risk and the chances of something bad happening to them (see AIG for a great example of this).
I conclude from this that transparency is a goal we should not be afraid of, because first of all it won’t be all that useful unless people have excellent modeling skills, second of all because no two firms will agree on the risks, and third of all we are so far from transparent right now that it’s laughable to be afraid of such an unlikely scenario.
Going on to the second post of Steve now, he has some good points about how we should handle the very dysfunctional and very opaque current financial system. First, he talks about the relationship between bankers and regulators and argues for strong regulation. The incentives for bankers to make things opaque are large, and the payoffs huge. This creates an incentive for bankers to essentially bribe regulators and to share in the proceeds, which in turn creates an incentive for the regulators to actually encourage opacity, since it makes it easier for them to claim they were trying to do their job but things got too complicated. This sounds like a pretty good explanation for the current problems to me, by the way. He then goes on:
… I think that high quality financial regulation is very, very difficult to provide and maintain. But for as long as we are stuck with opaque finance, we have to work at it. There are some pretty obvious things we should be doing. It is much easier for regulators to supervise and hold to account smaller, simpler banks than huge, interconnected behemoths. Banks should not be permitted to arrange themselves in ways that are opaque to regulators, and where the boundary between legitimate and illegitimate behavior is fuzzy, regulators should err on the side of conservatism. “Shadow banking” must either be made regulable, or else prohibited. Outright fraud should be aggressively sought, and when found aggressively pursued. Opaque finance is by its nature “criminogenic”, to use Bill Black’s appropriate term. We need some disinfectant to stand-in for the missing sunlight. But it’s hard to get right. If regulation will be very intensive, we need regulators who are themselves good capital allocators, who are capable of designing incentives that discriminate between high-quality investment and cost-shifting gambles. If all we get is “tough” regulation that makes it frightening for intermediaries to accept even productive risks, the whole purpose of opaque finance will be thwarted. Capital mobilized in bulk from the general public will be stalled one level up, and we won’t get the continuous investment-at-scale that opaque finance is supposed to engender. “Good” opaque finance is fragile and difficult to maintain, but we haven’t invented an alternative.
I agree with everything he said here. We need strong and smart regulators, and we need to see regulation in every part of finance. Why is this so hard? Because of the vested interests of the people in control of the system now – they’ve even invented a kind of moral philosophy around why they should be allowed to legally rape and plunder the economy. As he explains:
I think we need to pay a great deal more attention to culture and ideology. Part of what has made opaque finance particularly destructive is a culture, in banking and other elite professions, that conflates self-interest and virtue. “What the market will bear” is not a sufficient statistic for ones social contribution. Sometimes virtue and pay are inversely correlated. Really! People have always been greedy, but bankers have sometimes understood that they are entrusted with other people’s wealth, and that this fact imposes obligations as well as opportunities. That this wealth is coaxed deceptively into their care ought increase the standard to which they hold themselves. If stolen resources are placed into your hands, you have a duty to steward those resources carefully until they can be returned to their owners, even if there are other uses you would find more remunerative. Bankers’ adversarial view of regulation, their clear delight in treating legal constraint as an obstacle to overcome rather than a standard to aspire to, is perverse. Yes, bankers are in the business of mobilizing capital, but they are also in the business of regulating the allocation of capital. That’s right: bankers themselves are regulators, it is a core part of their job that should be central to their culture. Obviously, one cannot create culture by fiat. The big meanie in me can’t help but point out that what you can do by fiat is dismember organizations with clearly deficient cultures.
Hear, hear! But how?
“Where to start?”, I wondered.
Please consider purchasing a 55 gallon tub of lube from Amazon.com (pictured below). And before deciding, I suggest you read the reviews (hat tip Richard Smith via Yves Smith).

Also, please be sure to take this quiz to differentiate (if you can) between Newt Gingrich and a comic book supervillian.
Does hip-hop still exist?
I love music. I work in an open office, one big room with 45 people, which makes it pretty loud sometimes, so it’s convenient to be able to put headphones on and listen to music when I need to focus. But the truth it I’d probably be doing it anyway.
I’m serious about music too, I subscribe to Pandora as well as Spotify, because I’ll get a new band recommendation from Pandora and then I want to check their entire oeuvre on Spotify. My latest obsession: Muse, especially this song. Muse is like the new Queen. Pandora knew I’d like Muse because my favorite band is Bright Eyes, which makes me pathetically emo, but I also like the Beatles and Elliott Smith, or whatever. I don’t know exactly how the model works, but the point is they’ve pegged me and good.
In fact it’s amazing how much great music and other stuff I’ve been learning about through the recommendation models coming out of things like Pandora and Netflix; those models really work. My life has definitely changed since they came into existence. I’m much more comfortable and entertained.
But here’s the thing, I’ve lost something too.
My oldest friend sent me some mixed CDs for Christmas. I listened to them at work one recent morning, and although I like a few songs, many of the them were downright jarring. I mean, so syncopated! So raw and violent! What the hell is this?! It was hip-hop, I think, although that was a word from some far-away time and place. Does hip-hop still exist?
I’ve become my own little island of smug musical taste. When is the last time I listened to the radio and learned about a new kind of music? It just doesn’t happen. Why would I listen to the radio when there’s wifi and I can stream my own?
It made me think about the history of shared music. Once upon a time, we had no electricity and we had to make our own music. There were traveling bands of musicians (my great-grandmother was a traveling piano player and my great-grandfather was the banjo player in that troupe) that brought the hit tunes to the little towns eager for the newest sounds. Then when we got around to inventing the radio and record players, boundaries were obliterated and the world was opened up. This sharing got accelerated as the technology grew, to the point now that anyone with access to a browser can hear any kind of music they’d like.
But now this other effect has taken hold, and our universes, our personal universes, are again contracting. We are creating boundaries again, each around ourselves and with the help of the models, and we’ve even figured out how to drown out the background music in Starbucks when we pick up our lattes (we just listen to our ipods while in line).
I’d love to think that this contracting universe issue is restricted to music and maybe movies, but it’s really not. Our entire online environment and identity, and to be sure our actual environment and identity is increasingly online, is informed and created by the models that exist inside Google, Facebook, and Amazon. Google has just changed its privacy policy so that it can and will use all the information it has gleaned from your gmail account when you do a google search, for example. To avoid this, simply clear your cookies and don’t ever log in to your gmail account. In other words, there’s no avoiding this.
Keep in mind, as well, that there’s really one and only one goal of all of this, namely money. We are being shown things to make us comfortable so we will buy things. We aren’t being shown what we should see, at any level or by any definition, but rather what will flatter us sufficiently to consume. Our modeled world is the new opium.
Sturgeon
In honor of Chekhov’s 152nd birthday tomorrow, I’ve just finished reading the Lady with the Dog.
WTF: Greek debt vs. CDS
Just to be clear, if I’m a hedge fund who owns Greek bonds right now, and say I’ve hedged my exposure using CDSs, then why the fuck would I go along with a voluntary write-down of Greek debt??
From my perspective, if I do go along with it, I lose a asston of money on my bonds and my CDSs don’t get triggered because the write-down is considered “voluntary”. If I don’t go along with it, and enough other hedge funds also don’t go along with it, I either get paid in full or the CDSs I already own get triggered and I get paid in full (unless the counterparty who wrote the CDS goes under, but there’s always that risk).
Bottomline: I don’t go along with it.
None of this political finagling will change my mind. No argument for the stability of the European Union will change my mind. In fact, I will feel like arguing, hey if you force an involuntary voluntary write-down, then you are essentially making the meaning of CDS protection null and void. This is tantamount to ignoring legal contracts. And I’d have a pretty good point.
How’s this: let this shit go down, and start introducing a system that works, with a CDS market that is either reasonably regulated or nonexistent.
In the meantime, if I’m a Greek citizen, I’m wondering if I’ll ever be living in a country that has a consistent stock of aspirin again.
Updating your big data model
When you are modeling for the sake of real-time decision-making you have to keep updating your model with new data, ideally in an automated fashion. Things change quickly in the stock market or the internet, and you don’t want to be making decisions based on last month’s trends.
One of the technical hurdles you need to overcome is the sheer size of the dataset you are using to first train and then update your model. Even after aggregating your model with MapReduce or what have you, you can end up with hundreds of millions of lines of data just from the past day or so, and you’d like to use it all if you can.
The problem is, of course, that over time the accumulation of all that data is just too unwieldy, and your python or Matlab or R script, combined with your machine, can’t handle it all, even with a 64 bit setup.
Luckily with exponential downweighting, you can update iteratively; this means you can take your new aggregated data (say a day’s worth), update the model, and then throw it away altogether. You don’t need to save the data anywhere, and you shouldn’t.
As an example, say you are running a multivariate linear regression. I will ignore bayesian priors (or, what is an example of the same thing in a different language, regularization terms) for now. Then in order to have an updated coefficient vector 



So the problem simplifies to, how can we update
As I described before in this post for example, you can use exponential downweighting. Whereas before I was expounding on how useful this method is for helping you care about new data more than old data, today my emphasis is on the other convenience, which is that you can throw away old data after updating your objects of interest.
So in particular, we will follow the general rule in updating an object $T$ that it’s just some part old, some part new:
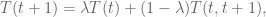
where by 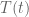
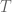
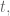


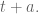
The speed at which I forget data is determined by my choice of 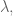
Specifically, I want to give an example of this update rule for the covariance matrix 
Namely, I claim that after updating 
Just to be really dumb, start with a univariate regression example, so where we have a single signal 

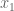


Now we get a new piece of data 
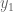

![[\mu x_1 x_2]](https://s0.wp.com/latex.php?latex=%5B%5Cmu+x_1+x_2%5D&bg=ffffff&fg=555555&s=0&c=20201002)

where by 
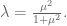
Things to convince yourself of:
- This works when we move from
pieces of data to
pieces of data.
- This works when we move from a univariate regression to a multivariate regression and we’re actually talking about square matrices.
- Same goes for the
- We don’t really have to worry about scaling; this uses the fact that everything in sight is quadratic in
, the downweighting scalar, and the final product we care about is
where, if we did decide to care about scalars, we would mutliply
- We don’t have to update one data point at a time. We can instead compute the `new part’ of the covariance matrix and the other thingy for a whole day’s worth of data, downweight our old estimate of the covariance matrix and other thingy, and then get a new version for both.
- We can also incorporate bayesian priors into the updating mechanism, although you have decide whether the prior itself needs to be downweighted or not; this depends on whether the prior is coming from a fading prior belief (like, oh I think the answer is something like this because all the studies that have been done say something kind of like that, but I’d be convinced otherwise if the new model tells me otherwise) or if it’s a belief that won’t be swayed (like, I think newer data is more important, so if I use lagged values of the quarterly earnings of these companies then the more recent earnings are more important and I will penalize the largeness of their coefficients less).

End result: we can cut our data up into bite-size chunks our computer can handle, compute our updates, and chuck the data. If we want to maintain some history we can just store the `new parts’ of the matrix and column vector per day. Then if we later decide our downweighting was too aggressive or not sufficiently aggressive, we can replay the summation. This is much more efficient as storage than holding on to the whole data set, because it depends only on the number of signals in the model (typically under 200) rather than the number of data points going into the model. So for each day you store a 200-by-200 matrix and a 200-by-1 column vector.
Brainstorming with narcissists
In the most recent New Yorker, there’s an article which basically says that, although “no-judgment” brainstorming sounds great, it doesn’t actually produce better ideas. That in fact you need to be able to criticize each other’s half-baked plans to get real innovation.
The idea that a bunch of people, who have been instructed that no idea is too banal to speak out loud will eventually move beyond the obvious into creative territory is certainly attractive, mostly because it’s so hopeful: in this world everyone can participate in innovation. And in fact it may be true, that everyone can be creative, but I agree that it won’t generally happen in the standard brainstorming meeting.
As usual I have lots of opinions about this, and lots of experience, so I’ll just go ahead and say what I think.
When does working in a group work?
- When people are sufficiently technical for the discussion, although not completely informed: it’s helpful to have someone with great technical skills or domain knowledge but who hasn’t thought through the issue, so they can question all of the assumptions as they come up to speed. In my experience this is when some of the best ideas happen.
- When people are more interested in getting to the answer than in impressing the people around them. This sounds too obvious to mention, but as we will see below it’s actually almost impossible to achieve in a largish group at an ambitious or successful company.
- When people know the people around them will be able to follow somewhat vague arguments and help them make those arguments precise.
- Alternatively when people know that others will gladly find flaws in ideas that are essentially bullshit. When everyone has agreed to call each other’s bullshit in a supportive way, and has taken on that role aggressively, you have a good dynamic.
Why does the “no-judgment” rule fail?
- When you aren’t being critical, you never get to the reasons why things are obviously a bad idea, so you never get to a new idea. That’s the critical part of no-judgment brainstorming that fails, the friction supplied by the other people who call you on a bad idea. Otherwise it’s just a bunch of people talking in a room, distracting you from thinking well by the loudness of their voices.
- When you have a bunch of successful people who have never failed, nobody actually lowers their guard. This idea of the super-achieving educational 1% is described in this recent New York Times article. I’ve seen this phenomenon close-up many times. People who are academic superstars absolutely hate taking risks and hate being wrong: life is a competition and they need to win every time. (update: there are plenty of people who were really freaking good at school that aren’t like this; when I say “academic superstars” I want to incorporate the idea that these people identify their success in school and/or other arenas that have metrics of success, like contests or high-quality brands (Harvard, McKinsey, etc.), as part of their identity.)
- Finally, the setup of the brainstorm is necessarily shallow and doesn’t require follow-through. In my experience only germs of good ideas can possibly occur in meetings. Lots of good germs have been left to rot on whiteboards. It would be wicked useful to try to rank ideas at the end of a meeting (by a show of hands, for example), but the “no-judgment” rule also prevents this.
Asian educational systems often get criticized for being so non-individualistic that they repress originality. True. But a system where the individual is promoted as special in every way also represses originality, because narcissists brook no argument.
This recent “Room for Debate” discussion in the New York Times brings up this issue beautifully. The idea is that schools are more and more being seen as companies, where the students and parents (especially the parents) are seen as the customer. The customer is always right, of course, and the schools are expected to tailor themselves to please everyone. It’s the opposite of learning how to disagree, learning how to be a member of society, and learning how to be wrong.
Interestingly, some of the best experiences I’ve had recently in the successful brainstorming arena have come from the #OWS Alternative Banking group I help organize. It’s made up of a bunch of citizens, many of whom are experts, but not all, and many of whom are experts in different corners of finance. The fact that people come to a meeting to talk policy and finance on Sunday afternoons means they are obviously interested, and the fact that no two people seem to agree on anything completely makes for feisty and productive debates.
Mortgage settlement talks
If you haven’t been following the drama of the possible mortgage settlement between the big banks that committed large-scale mortgage fraud and the state Attorney Generals, then get yourself over to Naked Capitalism right away. What could end up being the biggest boondoggle coming out of the credit crisis is unfolding before us.
The very brief background story is this. Banks made huge bets on the housing market through securitized products (mortgage backed securities which were then often repackaged or rerepackaged). The underlying loans were often given to people with very hopeful expectations about the future of the housing market, like that it would only go up. In the meantime, the banks did very bad jobs of keeping track of the paperwork. In addition to that, many of the loans were actually fraudulent and a very large number of them were ridiculous, with resetting interest rates that were clearly unaffordable.
Fast forward to post-credit crisis, when people were having trouble with their monthly bills. The banks made up a bunch of paperwork that they’d lost or had never been made in the first place (this is called “robo-signing”). The judges at foreclosures got increasingly skeptical of the shoddy paperwork and started balking (to be fair, not all of them).
Who’s on the hook for the mistakes the banks made? The home owners, obviously, and also the investors in the securitized products, but most critically the taxpayer, through Fannie and Freddie, who are insuring these ridiculous mortgages.
So what we’ve got now is an effort by the big banks to come to a “settlement” with the states to pay a small fee (small in the context of how much is at stake) to get out of all of this mess, including all future possible findings of fraud or misdeeds. The settlement terms have been so outrageously bank-friendly that a bunch of state Attorney Generals have been pushing back, with the help of prodding from the people.
Meanwhile, the Obama administration would love nothing more than to be able to claim they cleaned up the mess and made the banks pay. But that story seriously depends on people not really understanding the scale of the problem and the meaning of the fine print of the proposed settlement.
If you want to learn more recent details about this potential tragedy, this post from Naked Capitalism got me so entranced that I actually missed my subway stop on the way to work and had to walk uptown from Canal. From the post:
The story did not outline terms, but previous leaks have indicated that the bulk of the supposed settlement would come not in actual monies paid by the banks (the cash portion has been rumored at under $5 billion) but in credits given for mortgage modifications for principal modifications. There are numerous reasons why that stinks. The biggest is that servicers will be able to count modifying first mortgages that were securitized toward the total. Since one of the cardinal rules of finance is to use other people’s money rather than your own, this provision virtually guarantees that investor-owned mortgages will be the ones to be restructured. Why is this a bad idea? The banks are NOT required to write down the second mortgages that they have on their books. This reverses the contractual hierarchy that junior lienholders take losses before senior lenders. So this deal amounts to a transfer from pension funds and other fixed income investors to the banks, at the Administration’s instigation.
Another reason the modification provision is poorly structured is that the banks are given a dollar target to hit. That means they will focus on modifying the biggest mortgages. So help will go to a comparatively small number of grossly overhoused borrowers, no doubt reinforcing the “profligate borrower” meme.
But those criticisms assume two other things: that the program is actually implemented. The experience with past consent decrees in the mortgage space is that the servicers get a legal get out of jail free card, a release, and do not hold up their end of the deal. Similarly, we’ve seen bank executives swear in front of Congress in late 2010 that they had stopped robosigning, which turned out to be a brazen lie. So here, odds favor that servicers will pretty much do nothing except perhaps be given credit for mortgage modifications they would have made anyhow.
Interestingly, Romney has gone on record siding with the homeowners. The following is a Romney quote:
The banks are scared to death, of course, because they think they’re going to go out of business… They’re afraid that if they write all these loans off, they’re going to go broke. And so they’re feeling the same thing you’re feeling. They just want to pretend all of this is going to get paid someday so they don’t have to write it off and potentially go out of business themselves.”
This is cascading throughout our system and in some respects government is trying to just hold things in place, hoping things get better… My own view is you recognize the distress, you take the loss and let people reset. Let people start over again, let the banks start over again. Those that are prudent will be able to restart, those that aren’t will go out of business. This effort to try and exact the burden of their mistakes on homeowners and commercial property owners, I think, is a mistake.
“This effort” must refer to the mortgage settlement. I’m with Romney on this one.
In 50 years, when we look back at this period of time, we may be able to describe it like this:
The financial system got high on profits from unreasonably priced homes and mortgages, underestimating risk, and securitization fees. When the truth came out they paid a pittance to escape their mistakes, transferring the cost to homeowners and the taxpayer and leaving the housing market utterly inflated and confused. The entire charade lasted decades and was in the name of not acknowledging what everyone already knew, namely that the banks were effectively insolvent.
Occupy the World Economic Forum

Seasonally adjusted news
In one of my first posts ever, I talked about seasonal adjustment models and how they can work. I was sick of seeing that phrase go unexplained in the news all the time.
If I had been a bit more thoughtful, maybe I could have also mentioned various ways seasonal adjustment models could screw things up, or more precisely be screwed up by weird events. Luckily, a spokesperson from Goldman Sachs recently did that for me, and it was mentioned in this Bloomberg article. Those GS guys are smart, and would only mention this to Bloomberg if they thought everyone on the street knew it anyway, but I still appreciate them strewing their crumbs (it occurs to me that they might be trading on people’s overreactions to inflated good news right now).
Recall my frustration with seasonal adjustment models: they typically don’t tell you how many years of data they use, and how much they weight each year. But it’s safe to say that for statistics like unemployment and manufacturing, multiple years are used and more recent years are at least as important as older years. So events in the market that occurred in 2008 are still powerfully present in the seasonal adjustment model.
That means that, when the model is deciding what to expect, it looks at the past few years and kind of averages them. One of those years was 2008 when all hell broke loose, Lehman fell, TARP came into being, and Fannie, Freddie, and AIG were seized by the government. Lots of people lost their jobs and the housing and building industries went into freefall.
So the model thinks that’s a big deal, and compares what happened this year to that (and to the other years in the model, but that year dominates since it was such an extreme event), and decides we’re looking good. Here’s a picture from the Kansas Fed of the raw vs. seasonally adjusted manufacturing index results, from July 2001 to December 2011:

As one of my readers has already commented (darn, you guys are fast!), this just refers to manufacturing near Kansas, but the point I’m trying to make is still valid, namely that the seasonal adjustments clearly pale in comparison to the actual catastrophic event in 2008. However, that event still informs the seasonal adjustment model afterwards.
Because of the “golden rule” I mentioned in my post, namely that seasonal adjustment needs to on average (or at least in expectation) not add bias to the actual numbers, if things look better than they should in the second half of the year, that means they will look worse than they should in the first half of the year.
So be prepared for some crappy statistics coming out soon!
I still wish they’d just show us the graphs for the past 10 years and let us decide whether it’s good news.
Data Scientist degree programs
Prediction: in the next 10 years we will see the majority of major universities start masters degree programs, or Ph.D. programs, in data science, data analytics, business analytics, or the like. They will exist somewhere in the intersection of the fields of statistics, operations research, and computer science, and business. They will teach students how to use machine learning algorithms and various statistical methods, and how to design expert systems. Then they will send these newly minted data scientists out to work at McKinsey, Google, Yahoo, and possibly Data Without Borders.
The questions yet unanswered:
- Relevance: will they also teach the underlying theory well enough so that the students will know when the techniques are applicable?
- Skepticism: will they in general teach enough about robustness in order for the emerging data scientists to be sufficiently skeptical of the resulting models?
- Ethics: will they incorporate understanding the impact of the models so that students will think to understand the ethical implications of modeling? Will they have a well-developed notion of the Modeler’s Hippocratic Oath by then?
- Open modeling: will they focus narrowly on making businesses more efficient or will they focus on developing platforms which are open to the public and allow people more views into the models, especially when the models in question affect that public?
Open questions. And important ones.
Here’s one that’s already been started at the University of North Carolina, Charlotte.
Bad statistics debunked: serial killers and cervixes
If you saw this story going around about how statisticians can predict the activity of serial killers, be sure to read this post by Cosma Shalizi where he brutally tears down the underlying methodology. My favorite part:
Since Simkin and Roychowdhury’s model produces a power law, and these data, whatever else one might say about them, are not power-law distributed, I will refrain from discussing all the ways in which it is a bad model. I will re-iterate that it is an idiotic paper — which is different from saying that Simkin and Roychowdhury are idiots; they are not and have done interesting work on, e.g., estimating how often references are copied from bibliographies without being read by tracking citation errors4. But the idiocy in this paper goes beyond statistical incompetence. The model used here was originally proposed for the time intervals between epileptic fits. The authors realize that
[i]t may seem unreasonable to use the same model to describe an epileptic and a serial killer. However, Lombroso [5] long ago pointed out a link between epilepsy and criminality.
That would be the 19th-century pseudo-scientist3 Cesare Lombroso, who also thought he could identify criminals from the shape of their skulls; for “pointed out”, read “made up”. Like I said: idiocy.
Next, if you’re anything like me, you’ve had way too many experiences giving birth without pain control, even after begging continuously and profusely for some, because of some poorly derived statistical criterion that should never have been applied to anyone. This article debunks that among others related to babies and childbirth.
In particular, it suggests what I always suspected, namely that people misunderstand the effect of using epidurals because they don’t control for the fact that in the case of a long difficult birth you are more likely to get everything, which brings down the average outcome among people with epidurals but doesn’t at all prove causation.
Pregnant ladies, I suggest you print out this article and bring it with you to your OB appointments.
Apologies to Adam Smith
Not a lot of time to write this morning what with the sledding schedule, but I thought you might like this:
How’s it going with the Volcker Rule?
Glad you asked.
Recall that Occupy the SEC is currently drafting a letter of public comment of the Volcker Rule for the SEC (for background on the Volcker Rule itself, see my previous post). I was invited to join them on a call with the SEC last week and I will talk further about that below, but first I want to give you more recent news.
Yves Smith at Naked Capitalism wrote this post a couple of days ago talking about a House Financial Services Committee meeting, which happened Wednesday. Specifically, the House Financial Services Committee was considering a study done by Oliver Wyman which warned of reduced liquidity if the Volcker Rule goes into effect. Just to be clear, Oliver Wyman was paid by a collection of financial institutions (SIFMA) who would suffer under the Volcker Rule to study whether the Volcker Rule is a good idea. In her post, Yves was discussed the meeting as well as Occupy the SEC’s letter to that Committee which refuted the findings of Oliver Wyman’s study.
Simon Johnson, who was somehow on the panel even though it was more or less stuffed with people who wouldn’t argue, had some things to say about how much it makes sense to listen to people who are paid to write studies in his New York Times column published yesterday. He also made lots of good arguments against the content of the study, namely about the assumptions going into it and how reasonable they are. From Simon’s article:
Specifically, the study assumes that every dollar disallowed in pure proprietary trading by banks will necessarily disappear from the market. But if money can still be made (without subsidies), the same trading should continue in another form. For example, the bank could spin off the trading activity and associated capital at a fair market price.
Alternatively, the relevant trader – with valuable skills and experience – could raise outside capital and continue doing an equivalent version of his or her job. These traders would, of course, bear more of their own downside risks.
If it turns out that the previous form or extent of trading existed only because of the implicit government subsidies, then we should not mourn its end.
The Oliver Wyman study further assumes that the sensitivity of bond spreads to liquidity will be as it was in the depth of the financial crisis, 2007-9. This is ironic, given that the financial crisis severely disrupted liquidity and credit availability more generally – in fact this is a major implication of the Dick-Nelson, Feldhutter and Lando paper.
If Oliver Wyman had used instead the pre-crisis period estimates from the authors, covering the period 2004-7, even giving their own methods the implied effects would be one-fifth to one-twentieth of the size (this adjustment is based on my discussions with Professor Feldhutter).
CSPAN taped the meeting, which was pretty long, but I’d suggest you watch minutes 50 through 57, where Congressman Keith Ellison took some of the panel to task for being, or acting, super dumb.
For whatever reason, Occupy the SEC wasn’t invited to the panel. You can read their letter that argues against Wyman’s study, which is on Yves’s post, or you can read this comment that one of the members of Occupy the SEC posted on Johnson’s NYTimes piece (“OW” refers to Oliver Wyman, the author of the paid study):
Your testimony at the hearings yesterday was a refreshing counterpoint to the other members of the panel.
On top of the flaws in the OW analysis you covered in the article, there was another misleading point that the OW report purported to prove.
The study focused on liquidity for corporate bonds, which SIFMA/OW characterized as ‘financing american businesses’ . But a quick review of the outstanding corporate bonds in the study reveals that the lions share of corporate bonds are CMOs and ABS. Additionally, the study reports that the majority of the holdings of corporate bonds are in the hands of the finance industry.
As a result the loss of liquidity anticipated by the SIFMA folks will mostly impact them, not the pensioners and soldiers (and their Congressmen) the bankers were trying to scare with the OW loss estimates.
If the banks are forced to withdraw as market makers for this debt, replacement market makers won’t enter until these bonds trade at much lower levels. These losses are currently stranded (and disguised) in the banking system, and by extension are inflating the value of the funds invested in these bonds.
It’s critical that the market making rules are clarified to ensure that liquidity provision for these instruments is driven out of the protected banks and into a transparent market where the mispricing will be corrected and the losses will be properly recognized.
So just to summarize, the Congressional committee listened to the results of a paid study talking about how bad the Volcker Rule would be for the market, when in fact it would be good for the market to be uninsured and realistic.
I’m not a huge fan of the Volcker Rule as it is written, but these are really terrible reasons to argue against it. To my mind, the real problem is that, as written, the Volcker Rule is too easy to game and has too many exceptions written into it.
Going back to the call with the SEC (and with Occupy the SEC). I haven’t kept abreast of the details of the Volcker Rule like these guys (they are super relentless), but I did have some questions about the risk part. Namely, were they going to end up referring to an already existing risk regulatory scheme like Basel or Basel II, or were they creating something separate altogether? They were creating something separate. They mentioned that they weren’t interested in risk per se but only to the extent that wildly fluctuating risk numbers expose proprietary trading, which is the big no-no under the Volcker Rule.
But here’s the thing, I explained, the risk numbers you are asking for are so vague that it’s super easy, if I’m a bank, to game this to make my risk numbers look calm. You don’t specify the lookback period, you don’t specify the kind of Value-at-Risk, and you don’t compare my risk model worked out on a benchmark portfolio so you really don’t know what it’s saying. Their response was: oh, yeah, um, if you could give us better wording for that section that would be great.
So to re-summarize, we have “experts”, being paid by the banks, who explain to Congress why we shouldn’t let the Volcker Rule go through, and in the meantime we’ve assigned the SEC the job of writing that rule even though they don’t know how to game a risk model (there’s a good example here of JP Morgan doing just that last week).
One last issue: when we asked about why repos had been exempted sometime in between the writing of the statute and the design of the implementation, the SEC people just told us we’d “have to ask the Fed that”.
Followup: Change academic publishing
I really appreciate the amazing and immediate feedback I got from my post yesterday about changing the system of academic publishing. Let me gather the things I’ve learned or thought about in response:
First, I learned that mathoverflow is competitive and you “do well” on it if you’re quick and clever. Actually I didn’t know this, and since it is online I naively assumed people read it when they had time and so the answers to questions kind of drifted in over time. I kind of hate competitive math, and yes I wouldn’t like that to be the single metric deciding my tenure or job.
Next, ArXiv already existed when I left math, but I don’t think it’s all that good a “solution” either, because it’s treated mostly as a warehouse for papers, and there is not much feedback (although I’ve heard there’s way more in physics). Correct me if I’m wrong here.
I don’t want to sound like a pessimist, because the above two things really do function and add a lot to the community. I’m just pointing out that they aren’t perfect.
We, the mathematics community, should formally set out to be creative and thoughtful about different ways to collaborate and to document collaboration, and to score it for depth as well as helpfulness, etc. Let’s keep inventing stuff until we have a system which is respected and useful. The reason people may not be putting time into this right now is that they won’t be rewarded for it, but I say do it anyway and worry about that later. Let’s start brainstorming about what that system would look like.
That gets to another crucial point, which is that the people we have to convince are really not each other so much as deans and provosts of universities who are super conservative and want to be absolutely sure that the people they award tenure to are contributing citizens and will be for 40 years. We need to convince them to reconsider their definitions of “mathematical contributions”. How are we going to do this?
My first guess is that deans and provosts would listen to “experts in the field” quite a bit. This is good news, because it means that in some sense we just need to wait until the experts in the field come from the generation of people who invented (or at least appreciate) these tools. There are probably other issues though, which I don’t know about. I’d love to get comments from a dean or a provost on this one.
Change academic publishing
My last number theory paper just came out. I received it last week, so that makes it about 5 years since I submitted it – I know this since I haven’t even done number theory for 5 years. Actually I had already submitted it to a journal, and they took more than a year to reject it, so it’s been at least 6 years since I finished writing it.
One of the reasons I left academics was the painfully slow pace of being published, plus the feeling I got that, even when my papers did come out, nobody read them. I felt that way because I never read any papers, or at least I rarely read the new papers out of the new journals. I did read some older papers, ones that were recommended to me.
In other words I’m a pretty impatient person and the pace was killing me.
And I went to plenty of talks, but that process is of course very selective, and I would mostly be at a conference, or inside my own department. It led me to feel like I was mathematically isolated in my field as well as being incredibly impatient.
Plus, when you find yourself building a reputation more through giving talks and face-to-face interactions, you realize that much of that reputation is based on how you look and how well you give talks, and it stops seeming like mathematics is a just society, where everyone is judged based on their theorems. In fact it doesn’t feel like that at all.
I was really happy to see this article in the New York Times yesterday about how scientists are starting to collaborate online. This has got to be the future as far as I’m concerned. For example, the article mentions mathoverflow.net, which is a super awesome site where mathematicians pose and answer questions, and get brownie points if their answers are consistently good.
It’s funny how nowadays, to get tenure, you need to have a long list of publications, but brownie points for answering lots of questions on a community website for mathematicians doesn’t buy you anything. It’s totally ass backwards in terms of what we should actually be encouraging for a young mathematician. We should be hoping that young person is engaged in doing and explaining mathematics clearly, for its own sake. I can’t think of a better way of judging such a thing than mathoverflow.net points.
Maybe we also need to see that they can do original work. Why does it have to go through a 5 year process and be printed on paper? Why can’t we do it online and have other people read and rate (and correct) current research?
I know that people would respond that this would make lots of crappy papers seem on equal par with good, well thought-out papers, but I disagree. I think, first of all, that crap would be identified and buried, and that people would be more willing to referee online, since on the one hand it wouldn’t be resented, free work for publishers, and on the other hand, people would get more immediate and direct feedback and that would be cool and it would inspire people to work at it.
In other words, we can’t compare it to an ideal world where everyone’s papers are perfectly judged (not happening now) and where the good and important papers are widely read. We need to compare it to what we have now, which is highly dysfunctional.
That begs another huge question, which is why papers at all? Why not just contributions to projects that can be done online? For example my husband has an online open source project called the stacks project, but he feels like he can’t really urge anyone, especially if they’re young, to help out on it, because any work they do wouldn’t be recognized by their department. This is in spite of the fact that there’s already a system in place to describe who did what and who contributed what, and there are logs for corrections etc.; in other words, there’s a perfectly good way of seeing how much a given mathematician contributed to the project.
I honestly don’t see why we can’t, as a culture, acclimate to the computer age and start awarding tenure, or jobs, to people who have made major contributions to mathematics, rather than narrowly fulfilled some publisher’s fantasy. I also wonder if, when it finally happens, it will be a more enticing job prospect for smart but impatient people like myself who thrive on feedback. Probably so.
See also the follow-up post to this one.
Happy Birthday, Betty White!
Betty White turns 90 today (although Obama doesn’t seem to completely believe it).
I love her, and want to be just like her when I grow up. If you don’t know why, check her out describing Sarah Palin as a crazy bitch a couple of years ago, a brilliant combination of humor, politics, and sexual freedom.



